Lambda Cold Start 해결
Lambda의 Cold Start
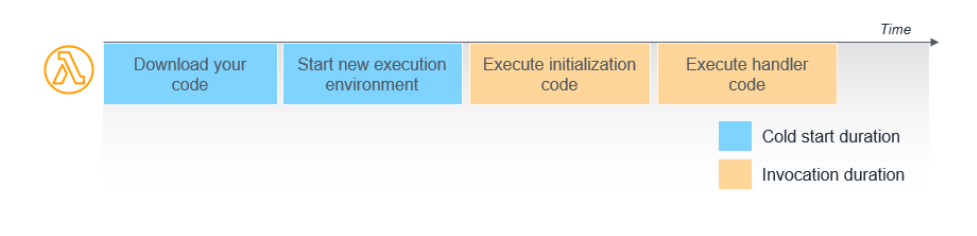
람다함수 코드는 위 그림과 같은 순서로 실행되는데, 저 과정들 중 코드를 실행하기 위한 환경을 준비하는 파란 부분을 콜드 스타트(Cold Start)라고 한다.
이와 반대로 이미 실행 환경이 갖추어져 있다면 Cold Start부분은 스킵하고 바로 노란색 부분부터 실행이 가능한데 이것을 Warm Start라고 한다.
람다는 실행시간에 비례하여 요금이 청구되므로 Warm Start가 훨씬 실행시간도 단축되고 비용도 적게 든다.
로그 분석
Cold Start
우선 실행 환경이 하나도 갖추어지지 않은채 처음부터 준비해야 하는 Cold Start를 해보자.
Duration: 31949.48 ms Billed Duration: 31950 ms Memory Size: 2048 MB Max Memory Used: 645 MB 첫 번째 실행은 CloudWatch를 이용해 모델 분석 API요청 로그를 보면 무려 31.9초나 걸린것을 볼 수 있다.
로그를 자세히 살펴보니, 실제 모델 추론시간보다 모델을 메모리에 적재하는 초기화 시간이 훨씬 더 오래 걸리고 있었다.
Warm Start
Lambda는 효율성을 위해 일정 시간 동안 실행 환경(컨테이너)을 파괴하지 않고 유지한다. 이 환경이 사라지기 전에 함수를 다시 호출하면 이미 메모리에 모델이 적재된 상태인 Warm Start가 가능하다.
Duration: 214.72 ms Billed Duration: 215 ms Memory Size: 2048 MB Max Memory Used: 653 MB 이에 반해 두 번째 실행 (Warm Start)에서는 첫 번째와는 다른 사진을 분석시켰음에도 0.2초로 실행시간이 확 줄어든 것을 볼 수 있다.
이는 YOLO모델 로드 코드를 전역 변수 영역에 배치하였기 때문이다. Warm start로 재실행시, 이미 메모리에 적재된 모델 객체를 즉시 참조하게 되면서 무거운 초기화 과정이 생략되었기 때문이다.
Provisioned Concurrency를 통한 Warm Start
그러나 Warm start는 영구적이지 않다.
람다는 일정시간동안 요청이 없으면 리소스를 회수하기 위해 실행 환경(컨테이너)를 삭제한다. 이 경우 다시 Cold Start가 발생한다는 한계가 있다. 이용자가 많은 서비스라면 요청이 잦아 대부분의 요청에서 Warm Start상태를 유지할 수 있겠지만, 개인 프로젝트처럼 사용자가 거의 없는 경우에는 요청이 잦아봐야 몇시간에 한 번일테니 매번 Cold Start가 되어 사진 하나를 분석하는데 30초를 넘게 기다려야 할 것이다.
이를 해결하기 위한 방법으로는 2가지가 있는데
첫번째는 프로비저닝 동시성(Provisioned Concurrency)이다.
이 기능은 EC2처럼 계-속 람다 함수를 켜두는 것이다.
프로비저닝 동시성 기능을 활성화하면, 설정된 개수만큼의 인스턴스를 초기화하여 대기시켜 둔다. 그러면 Cold Start가 발생하지 않고 Warm Start로 즉시 실행되게 된다.
프로비저닝 동시성 기능을 활성시킨후, 람다가 컨테이너를 삭제할만한 시간동안 호출을 하지 않았다.
다시 앱에서 람다 함수를 호출해보았더니 훨씬 단축된 실행시간에, 로그에 Init duration(초기화 시간)도 찍히지 않는 것을 볼 수 있었다. 즉, 성공적으로 Warm Start가 적용된 것이다.

[실행시간이 0.27초로 단축되었다]
다만 이는 EC2처럼 계속 실행시켜 두는 것이나 다름없다보니 비용이 꽤 있는편이다. 그래서 좀 더 심화된 최적화 방법으로, 프로비저닝 오토스케일을 사용하기도 한다고 한다.
프로비저닝 오토스케일링은 트래픽이 높은 시간대에 맞춰 프로비저닝을 오토스케일링하여 가격을 최적화하는 방법이다.
