📍 병합 정렬 (merge sort)
✅ 정의
분할 정복(divide and conqur) 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘이다.
시간 복잡도 평균값은 O(nlogn)이다. (시간 복잡도가 가장 짧은 정렬이다.)
코딩 테스트의 정렬 관련 문제에서 자주 등장한다.
✅ 핵심 이론
집합은 setN으로 표시한다.
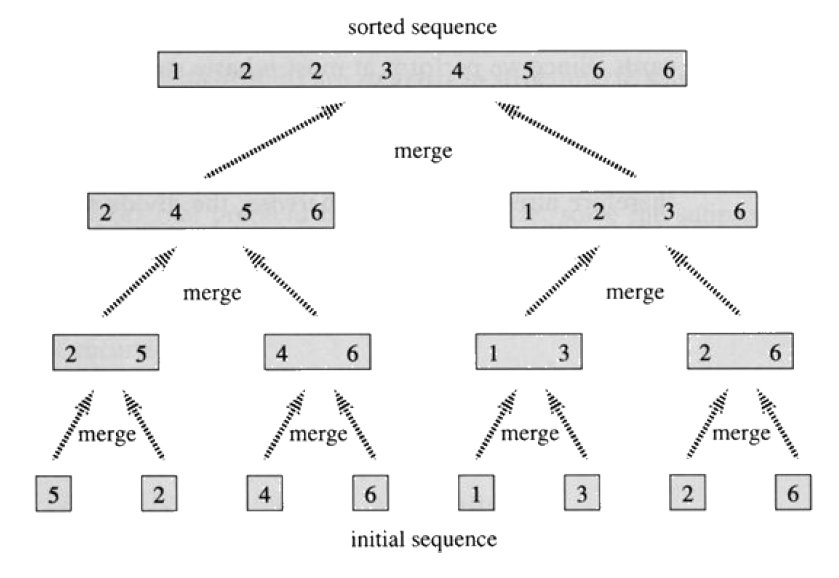
가장 작은 데이터 집합으로 분할하고 병합하며 정렬한다.
✅ 정렬 과정
개별적인 그룹을 각각 2개의 그룹으로 합치며 오름차순으로 정렬한다.
이어서 2개씩 그룹을 합치며 다시 오름차순으로 정렬한다.
과정을 반복하며 병합 정렬 과정을 거치면 전체를 오름차순으로 정렬할 수 있다.
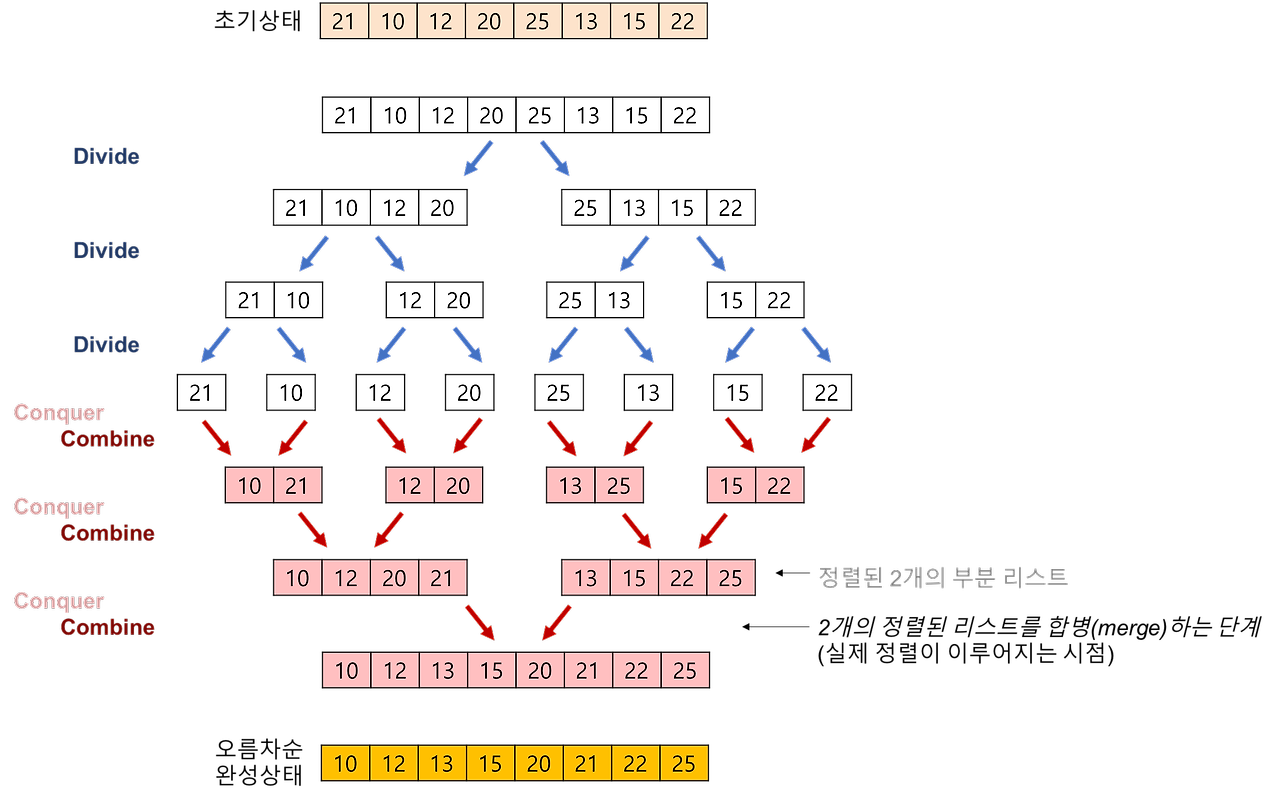
✅ 2개의 그룹을 병합하는 과정
병합 정렬은 코딩 테스트의 정렬 관련 문제에서 자주 등장한다.
투 포인터 개념을 사용하여 왼쪽, 오른쪽 그룹을 병합한다.
왼쪽 포인터와 오른쪽 포인터의 값을 비교하여 작은 값을 결과 배열에 추가하고 포인터를 오른쪽으로 1칸 이동시킨다.
📍 기수 정렬 (radix sort)
✅ 정의
값을 비교하지 않는 특이한 정렬이다.
값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교한다.
시간복잡도는 O(kn)이다.
k는 데이터 자릿수를 말한다.
ex. 234, 123을 비교하면 4와 3, 3과 2, 2와 1만 비교한다.
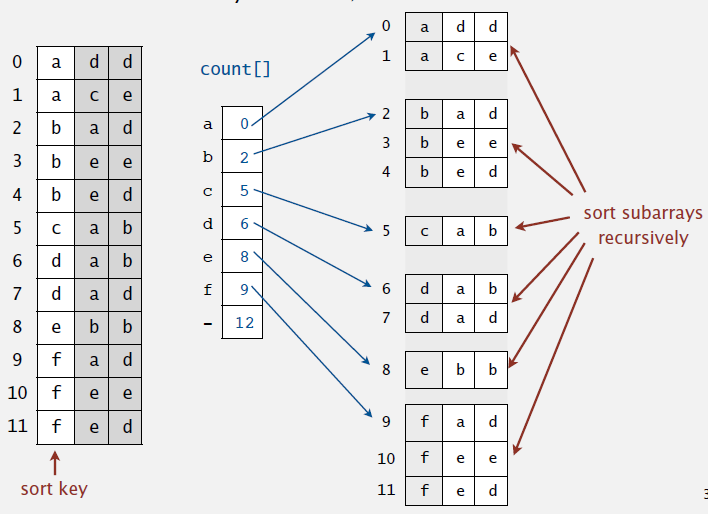
✅ 핵심 이론
기수 정렬은 10개의 큐를 이용한다.
각 큐는 값의 자릿수를 대표한다.
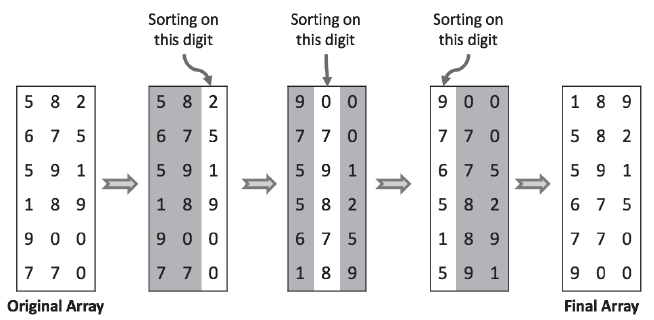
✅ 정렬 과정
- 일의 자릿수를 기준으로 데이터를 저장한다.
- 일의 자릿수를 기준으로 데이터를 정렬한다.
- 일의 자리에서 정렬된 순서 기준으로 십의 자리에 저장하는 것이 중요하다.
- 십의 자릿수를 기준으로 데이터를 저장한다.
4-1. 데이터를 담는 자료구조는 Queue로 FIFO 형태를 취한다.(0~9번째 큐까지 pop을진행한다.) - 마지막 자릿수를 기준으로 정렬할 때까지 앞의 과정을 반복한다.

https://honeypeach.tistory.com/ 로 이전했습니다.