arxiv: https://arxiv.org/abs/1310.4546
date: 05/11/2022

Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.
Abstract - Introduction
-
Precedent Studies
-
Skip-gram Model
- 단어의 syntactic, semantic 관계를 효율적으로 표현할 수 있는 모델
- 중심 단어에서 주변 단어를 예측

 ( 중심 단어 - 주변 단어 간 관계 | 인공신경망 도식화 )
( 중심 단어 - 주변 단어 간 관계 | 인공신경망 도식화 )
-
Skip-gram Model의 특징
- 행렬곱 연산 수행 x (training efficiency ↑)
- 언어학적 패턴을 매우 명확하게 encoding
-
-
Objective
- Skip-gram Model의 개선 도모
(Skip-gram Model을 근간으로 하여 vector의 quality와 training의 속도 향상 방안을 논한다.)
- Skip-gram Model의 개선 도모
-
Key Point
- Subsampling of the frequent words ( rel. w/ 속도 향상, 규칙적인 단어 표현 可 )
- Negative Sampling ( hierarchical softmax의 대안 )
- "Simple method for finding phrases in text" ( 잘 훈련된 vector가 관용구의 의미를 표현할 수 있다. )
The Skip-gram Model
-
Training Objective
- 문장 or 문서에서 주변 단어들을 예측하는 단어 표현을 찾는 것
- regarding sequence of training words w1, w2, w3, ... ,wt - log 확률의 평균을 최대화하는 것이 Skip-gram Model의 목표
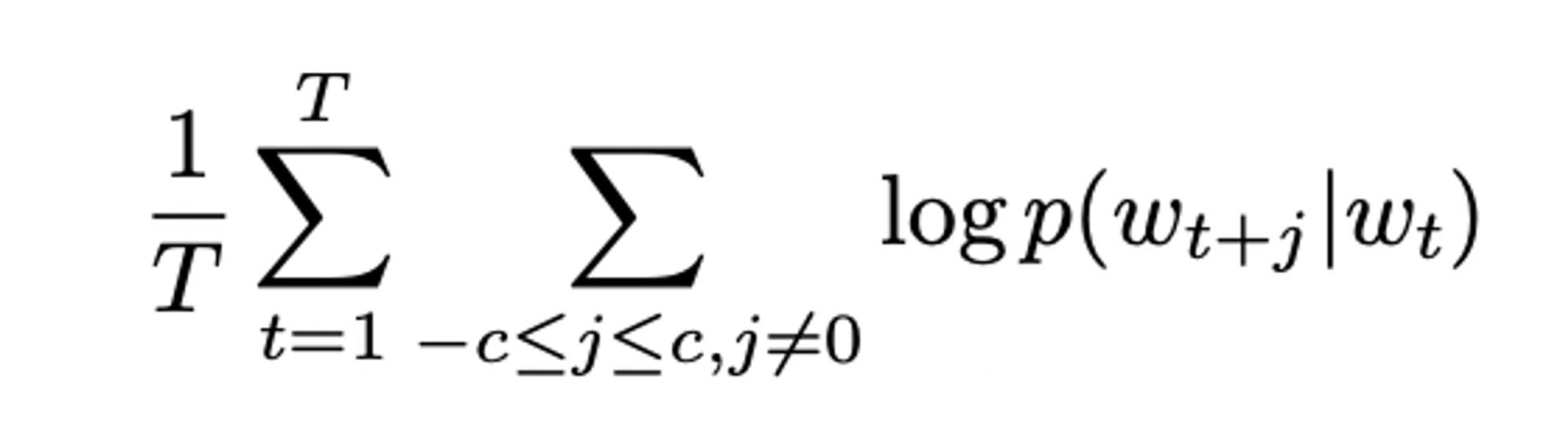 ( c = training context의 크기 )
( c = training context의 크기 )
* c의 값 ↑ 할수록 training의 결과가 좋으나, training에 소모되는 시간 또한 ↑
-
Basic Skip-gram formation
 ( softmax 함수 활용 )
( softmax 함수 활용 ) -
*Hierarchical Softmax*
- full softmax에 근접하면서 연산을 효율적으로 할 수 있는 방법
( w에 대한 확률 분포 대신 log(w)에 대한 확률 분포만을 구하면 된다는 이점 有 ) -
이진트리를 활용해 w의 output node 표현. 트리의 각 node의 leaf, child node의 확률과 연관 → 단어의 임의 확률 정의하게 해 줌
- 이진트리, 성능 향상에 큰 기여 ( rel. w/ 훈련 시간, 모델의 정확성 )hierarchical softmax에서의 p(w0|wi)
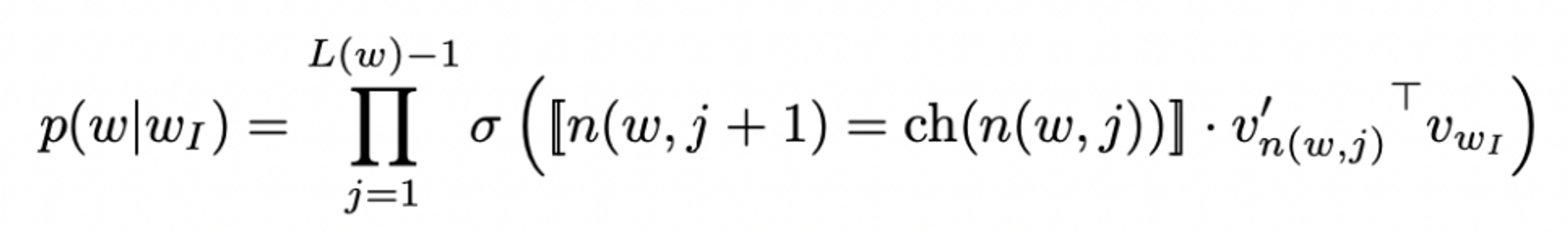 (Alternative for Hierarchical Softmax)
(Alternative for Hierarchical Softmax)
- 이진트리, 성능 향상에 큰 기여 ( rel. w/ 훈련 시간, 모델의 정확성 )hierarchical softmax에서의 p(w0|wi)
-
*Negative Sampling*
-
cf. NCE ( noise constructive estimation ) : softmax 로그 확률의 근사적 확률 최대 ( NCE의 변형 → Negative Sampling )
-
Objective / Definition
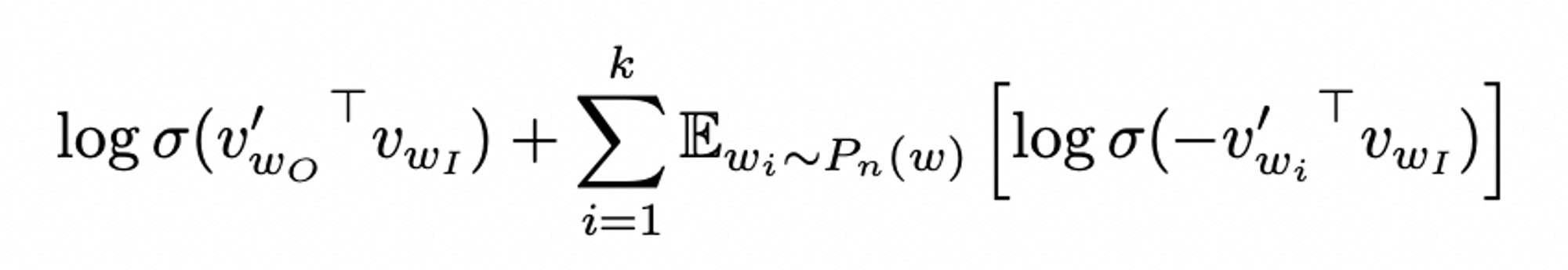 ( used to replace every logP(wo|wi) term in ths Skip-gram objective )
( used to replace every logP(wo|wi) term in ths Skip-gram objective ) -
Task
- noise 분포 Pn(w)로부터 각 데이터의 k개의 negative sampling을 활용한 로지스틱 회귀를 이용하여 target data W0를 구분하는 것
- cf. 작은 dataset에 대해서는 k값이 5~20, 큰 dataset에 대해서는 k값이 2-5일 때 가장 성능이 좋다.
-
-
Negative Sampling vs. NCE
- NCE : noise 분포의 수치적 확률, sample 모두 要
- Negative Sampling : 오직 sample만 要
+ NCE, Negative Sampling 모두 noise 분포 Pn(w)를 free parameter로 가짐
unigram 분포 U(w)의 3/4승 일 때 성능이 가장 좋음
-
*Subsampling of Frequent Words*
-
Background
- 매우 큰 말뭉치 内, 'a', 'the', 'in' 등 빈번히 등장하는 단어 有 → such words, ↓ information value than rare words → Subsampling 要
-
Objective / Definition
-
rare word, frequent word의 가중치 측정 위함
-
each word wi in the training set, discarded w/ probability computed by formula
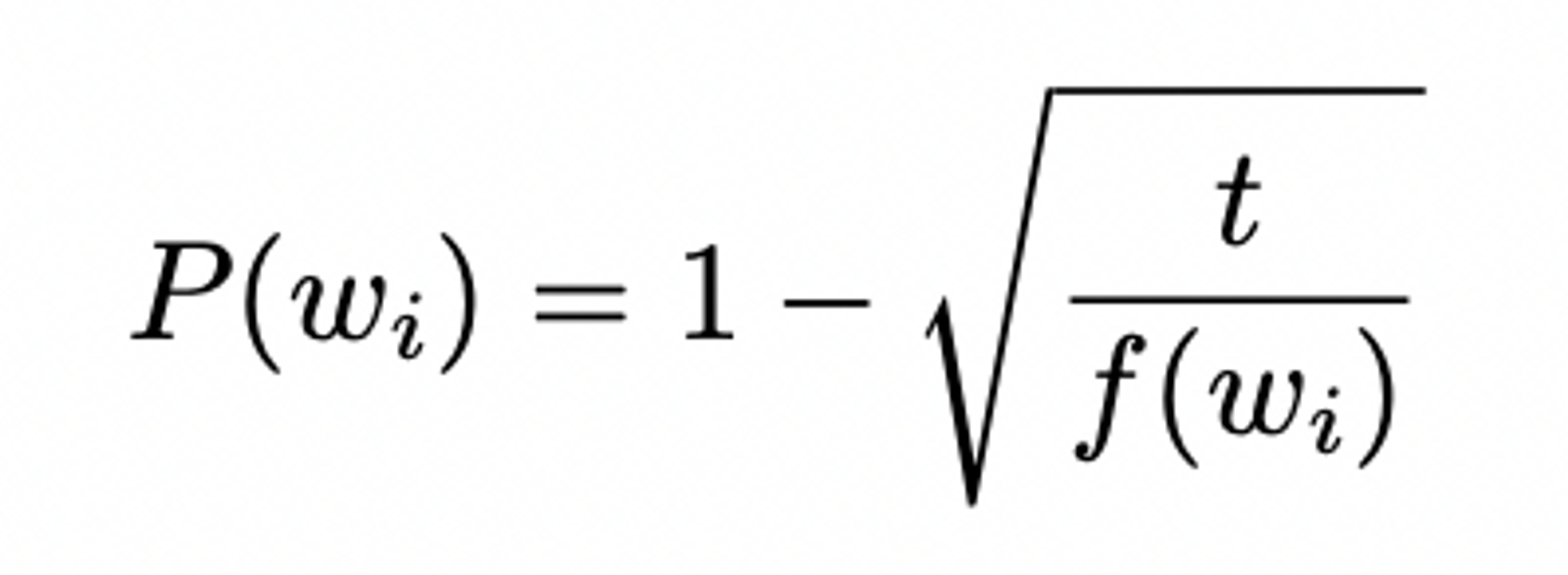 f(wi) = 단어 wi의 빈도수, t = threshold (typically 10^-5)
f(wi) = 단어 wi의 빈도수, t = threshold (typically 10^-5) -
t보다 빈도수 ↑ 한 단어를 aggressively subsample → works well in practice
-
accelerates learning + improves the accuracy of the learned vectors of the rare words
-
-
Empirical Results
; reg. Negative Sampling & Subsampling of Frequent Words
- Analogical reasoning task 利用、hierarchial softmax, NCE, negative sampling, subsampling 평가
- cf. analogical reasoning task
- syntactic analogies ( quick : quickly = slow : slowly )
- semantic analogies ( South Korea : Seoul = Ireland : Dublin )
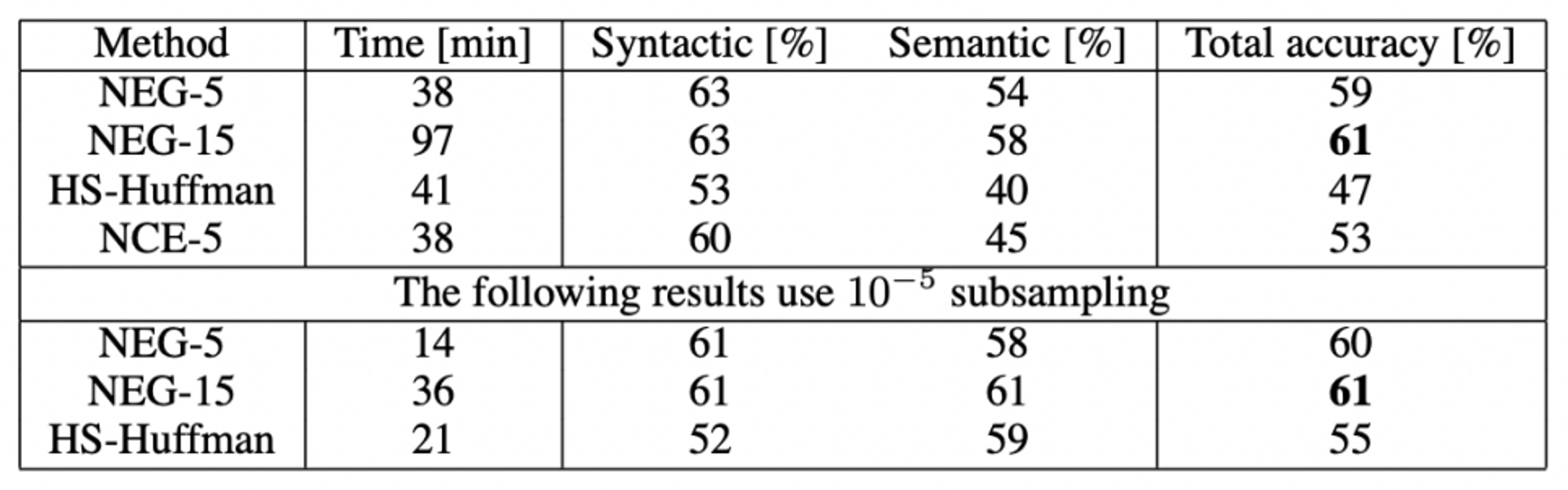
- cf. analogical reasoning task
- Result
- negative sampling, hierarchical softmax보다 성능 ↑
- subsampling of frequent words 사용 시 training 속도 및 정확성 ↑
Learning Phrases
-
Background
- 많은 phrases, 개별 단어 결합 이상의 의미를 가짐 → phrases에 대한 vector 학습 要
-
Methodology
-
특정 맥락에서만 자주 등장하는 단어쌍 표현 → 어휘 크기를 크게 키우지 않으면서도 多 reasonable phrases 얻게 해줌
-
cf. conventional skip-gram model, 과도한 메모리 부하 induce 可
-
simple data-driven approach, where phrases are formed based on the unigram / bigram counts
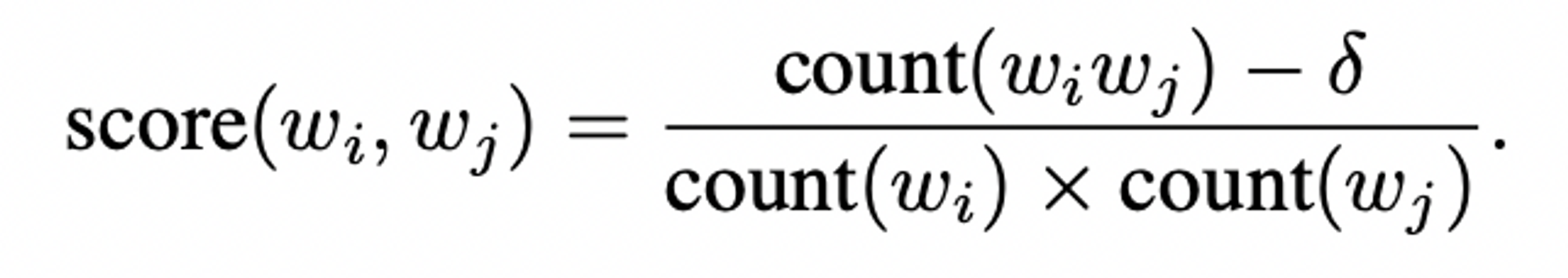 (𝛿 = discounting coefficient)
(𝛿 = discounting coefficient) -
매우 빈번하지 않은 단어로 구성된 구 방지 ( threshold 를 넘어선 score 가진 bi-gram이 선택됨 + 더 긴 phrase의 형성 )
-
-
Phrase Skip-gram model result
- phrase 기반의 training data 구성, hyperparameter 조정하여 training 진행 ( vector 차원 300, context size 5 )

- negative sampling의 겨우 k=15일 때 성능이 좋음
- subsampling 할 때 일관적으로 성능이 좋음
+ phrase analogy task의 가장 좋은 결과, 데이터 양 ↑ 했을 때임 ( 큰 dataset, accuracy 높이는 데에 중요하다 ! )
- phrase 기반의 training data 구성, hyperparameter 조정하여 training 진행 ( vector 차원 300, context size 5 )
Additive Compositionality
" Skip-gram을 이용한 단어나 구에 대한 표현, 벡터의 구조를 가지고도 analogical reasoning에서 정확한 성능을 보일 수 있는 선형적 표현이다 ! "
( Skip-gram의 표현, 의미있는 요소들의 결합을 벡터의 합으로 표현 可)

- 높은 확률을 갖고 있는 두 벡터의 결합 → 높은 확률을 갖게 됨
- 낮은 확률을 갖고 있는 두 벡터의 결합 → 낮은 확률을 갖게 됨
Conclusion
- Subsampling of the frequent words → 학습 속도 개선, rare words 에 대한 정확도 ↑
- Negative sampling → frequent word에 대한 accuracy ↑
- phrase에 대한 표현 방법 / 학습 방법 → 선형적인 구조를 가지고도 analogical reasoning에서 좋은 성능을 낼 수 있음 ( 연산의 단순화 ), word / phrase 표현 quality ↑
- 모델의 구조, vector의 크기, subsampling 비율, window 크기가 중요하다 !
Reference
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.
- https://wikidocs.net/22660
- https://coshin.tistory.com/44
