 부제 : 거의 다왔어요 집중집중 !
부제 : 거의 다왔어요 집중집중 !
Models
IMT 연구가 꽤 오랜 기간 이어진 만큼 수많은 모델들이 고안되고 발표되었으나, 여건상 그 중 일부만을 보다 자세히 다뤄보도록 하겠다.
MultimodalNMT
Model Architecture
2 에서는 세 종류의 attention-based multi-modal neural machine translation model들을 제안한다. 해당 모델들은 동일한 베이스라인 모델을 채택하고 있으나, 각기 다른 cross-modal fusion method들을 사용한다. 논문의 저자들은 세 모델을 동일한 환경에서 학습 시킨 결과를 비교 대조하며 어떤 cross-modal fusion method이 가장 효과적인가를 논한다.
세 모델의 공통적인 model architecture은 다음과 같다. 기본적인 모델의 얼개는 encoder-decoder 구조이며, 모델의 encoder는 bidirectional RNN와 GRU가 결합된 형태를, decoder는 RNN과 attention이 결합된 형태를 띠고 있다. 이미지 정보를 추출하는 visual encoder로는 pre-trained ResNet-50을 활용하였다.
논문에서 제시하는 세 가지 cross-modal fusion method들은 이미지를 source sentence의 단어들과 통합하는 방식 (), encoder hidden state을 initialize하는데 사용되는 방식 (), 그리고 decoder hidden state을 initialize하는데 사용되는 방식 ()이다.
첫번째 방식 () 을 도식화하면 다음과 같이 표현할 수 있다.
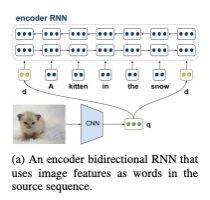 에서는 이미지를 문장의 첫번째 및 마지막 단어처럼 취급하여 model에 feed하여 이미지와 텍스트를 융합한다. 논문에 따르면 이미지를 첫번째 단어 취급하는 경우 forward RNN을 적용시켰을 때 source sentence와 이미지를 융합하는 효과를 얻을 수 있고, 이미지를 마지막 단어 취급하는 경우 backward RNN을 적용시켰을 때 source sentence와 이미지를 융합하는 효과를 얻을 수 있다고 한다. 연구진들은 이미지를 문장의 첫번째 단어로 취급하여 학습시키는 경우를 , 첫번째 그리고 마지막 단어로 취급하여 학습시키는 경우를 로 다시 구분하여 각각에 대한 실험을 진행하였다.
에서는 이미지를 문장의 첫번째 및 마지막 단어처럼 취급하여 model에 feed하여 이미지와 텍스트를 융합한다. 논문에 따르면 이미지를 첫번째 단어 취급하는 경우 forward RNN을 적용시켰을 때 source sentence와 이미지를 융합하는 효과를 얻을 수 있고, 이미지를 마지막 단어 취급하는 경우 backward RNN을 적용시켰을 때 source sentence와 이미지를 융합하는 효과를 얻을 수 있다고 한다. 연구진들은 이미지를 문장의 첫번째 단어로 취급하여 학습시키는 경우를 , 첫번째 그리고 마지막 단어로 취급하여 학습시키는 경우를 로 다시 구분하여 각각에 대한 실험을 진행하였다.
두번째 방식 () 은 다음과 같이 도식화할 수 있다.
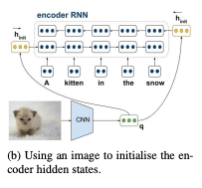
에서는 source language encoder를 초기화하기 위해 이미지를 활용한다. RNN 계열 모델을 베이스라인으로 활용하는 기존의 MT 모델들은 일반적으로 encoder의 hidden state을 zero vector로 초기화한다. 이와 달리 에서는 encoder의 forward RNN과 backward RNN의 첫번째 hidden state으로 이미지 정보를 넣음으로써 이미지와 텍스트를 융합하는 방식을 채택하였다.
마지막 방식 () 은 아래 그림과 같이 표현할 수 있다.
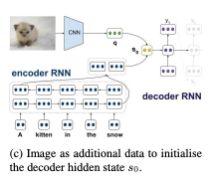
에서는 target language decoder을 초기화하기 위해 이미지를 활용한다. RNN 계열 모델을 베이스라인으로 활용하는 기존의 MT 모델들은 일반적으로 encoder의 마지막 hidden state을 활용해 decoder의 hidden state를 초기화한다. 이와 달리 에서는 encoder의 마지막 hidden state와 이미지 정보를 동시에 활용하여 decoder의 hidden state를 초기화함으로써 이미지와 텍스트를 융합하는 방식을 채택한 것이다.
Result
세 모델은 공통적으로 Multi30K 데이터셋을 활용하여 학습되었으며, 영어–독일어 언어쌍에 대한 각 모델 성능은 다음과 같았다.
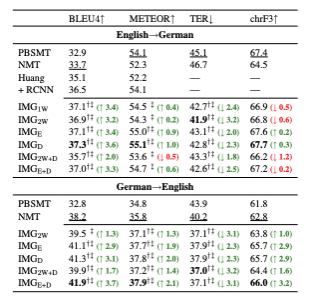
요컨대, 이외의 모든 모델이 기존 IMT 모델보다 좋은 성능을 보였으며, 영-독 번역에서는 모델이, 독-영 번역에서는 모델이 눈에 띄는 좋은 성능을 보였다.
Multimodal Transformer
Model Architecture
7 에서는 multimodal attention을 도입한 Transformer 기반 IMT 모델 Multimodal Transformer을 제안한다. 모델의 기본적인 얼개는 마찬가지로 encoder-decoder 구조이며, 모델의 encoder는 multimodal attention을 도입한 Transformer encoder를, decoder는 Transformer decoder를 차용하였다. 이 모델 또한 마찬가지로 이미지 정보를 추출하는 visual encoder로 pre-trained ResNet-50을 활용하였다.
모델 구조를 도식화하면 다음과 같다.
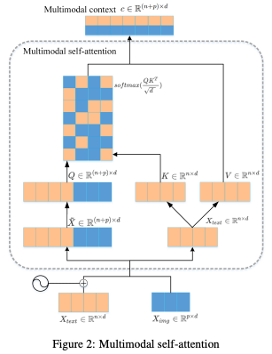
구체적으로 해당 모델은 encoder에서 image-aware attention을 활용하여 이미지 정보를 반영한 텍스트 정보(multimodal representation)를 추출하며, 이 과정을 통해 이미지와 텍스트정보가 융합시킨다. 이렇게 추출된 multimodal representation이 Transformer decoder을 거치면서 번역문이 산출된다.
Result
해당 모델 또한 Multi30K 데이터셋을 활용하여 학습되었으며, 영어–독일어 언어쌍에 대한 모델 성능은 다음과 같았다.
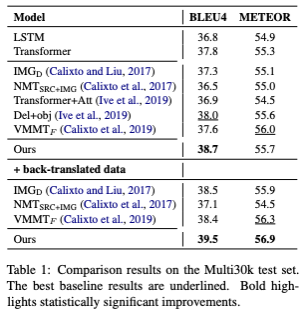
요컨대, Multimodal Transformer는 기존 IMT 모델보다 좋은 성능을 보였으며, back-translation을 통해 증강시킨 데이터로 추가 학습을 진행하였을 때 성능이 증진되는 것을 확인할 수 있었다.
DCCN
Model Architecture
8 에서는 두 개의 DCCN을 추가한 Transformer 기반 IMT 모델을 제안한다. 이 모델 또한 기본적으로 encoder-decoder 구조를 채택하고 있으며, 모델의 encoder는 Transformer encoder를, decoder는 마지막 layer에 두 개의 DCCN을 추가한 Transformer decoder를 채택하였다. 이미지 정보를 추출하는 visual encoder로는 역시 pre-trained ResNet-50을 활용하였다.
모델 구조는 다음과 같다.
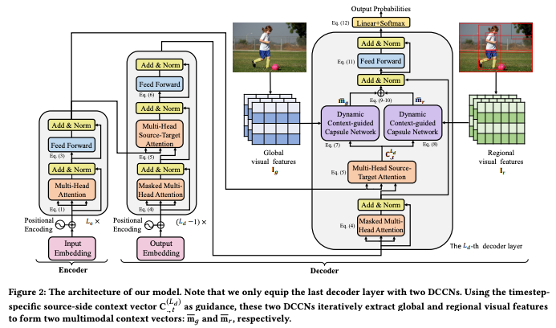
구체적으로 해당 모델은 encoder에서 텍스트 데이터 encoding을 진행하고, decoder의 마지막 layer에 두 개의 DCCN(Dynamic Context-guided Capsule Network)을 추가해 이미지 정보를 총체적으로 추출하는 동시에 해당 이미지 정보를 텍스트 정보와 융합한다. 마지막 layer의 DCCN들을 거치며 도출된 multimodal representation이 나머지 layer을 거치면서 번역문이 산출된다.
Result
해당 모델 또한 Multi30K 데이터셋을 활용하여 학습되었으며, 영어–독일어 언어쌍에 대한 모델 성능은 다음과 같았다.
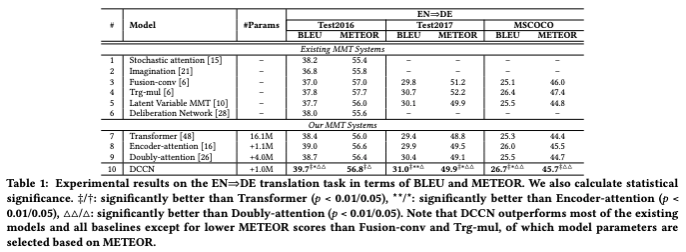
요컨대, DCCN을 활용한 본 모델은 BLEU score에 있어서 기존 IMT 모델들을 능가했으며, 비교적 나쁘지 않은 METEOR score을 보였다.
VTLM
Model Architecture
14 에서는 pre-trained된 VTLM 모델의 weight를 OpenNMT model을 초기화하는데 사용하고, 그렇게 초기화된 모델을 IMT task에 맞게 한번 더 fine-tuning 하여 성능을 높이는 방법을 제안하였다. 해당 모델은 IMT task에 대해 처음으로 pre-train & fine-tuning 방식을 채택한 모델이다.
1. Pre-training
VTLM은 기존의 TLM(Translation Language Modelling)에 masked region classification (MRC)을 결합해 시각적 정보와 다국어 정보를 총체적으로 활용하고자 설계된 모델이다. VTLM은 기본적으로 encoder-decoder 구조를 채택하고 있으며, encoder와 decoder 모두 Transformer 모델 구조를 그대로 차용하였다. 이미지 정보를 추출하는 visual encoder로는 pre-trained Faster R-CNN 모델을 활용하였다.
VTLM의 구조는 다음과 같다.
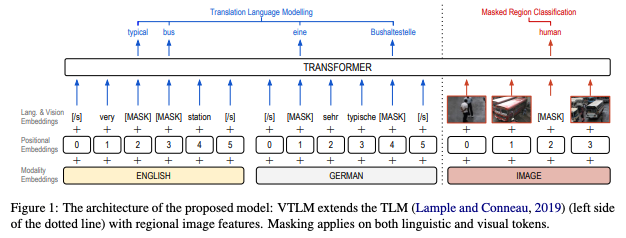
구체적으로 VLTM의 input으로는 masking된 텍스트 pair과 이미지가 들어가고, 해당 모델은 텍스트와 이미지 모두에 대해 masking된 지점을 예측하는 방식으로 학습된다.
2. Fine-tuning
위에서 언급했듯, fine-tuning 단계에서는 pre-trained된 VTLM의 weight를 MMT 모델에 적용시키고 IMT task에 맞게 다시 학습시키는 과정을 거친다.
Result
해당 모델도 마찬가지로 Multi30K 데이터셋을 활용하여 학습되었으며, 영어–독일어 언어쌍에 대한 모델 성능은 다음과 같았다.
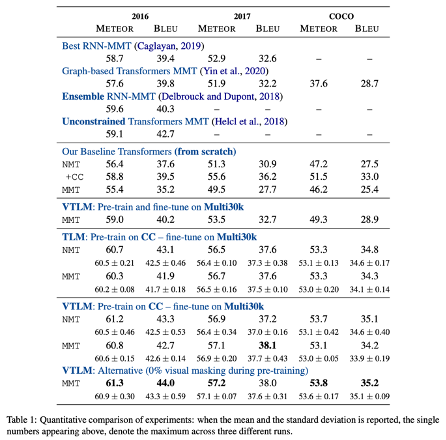
요컨대, 해당 논문에서 발표한 모델은 기존 IMT 모델들을 능가했으며, 논문 저술 시점 당시 SOTA의 성능을 보였다.
BERTGEN
Model Architecture
11 에서는 VL-BERT(Visual-Linguistic BERT)와 M-BERT(Multilingual BERT)을 융합한 모델인 BERTGEN을 제안한다. 이 모델은 위에서 언급한 모델들과 달리 encoder-decoder 사이의 구분이 없고, 하나의 generator로 구성되어있다. 다만 이미지 정보를 추출하기 위해 visual encoder로 bottom-up-top-down object detector를 채택하고 있으며, object detector에서 추출된 이미지 벡터와 위치 임베딩을 합한 결과값이 최종 이미지 정보로 사용된다. 해당 모델은 14 에서 제안한 방법과 마찬가지로 pre-train & fine-tuning의 학습 방식을 채택하고 있다.
BERTGEN의 모델 구조는 다음과 같이 도식화할 수 있다.
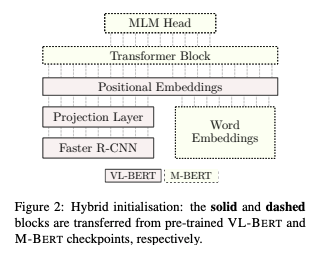
구체적으로, BERTGEN은 VL-BERT의 pre-trained checkpoint을 활용하는 동시에, pre-trained M-BERT를 활용해 word embedding, Transformer weight, MLM head을 초기화한다.
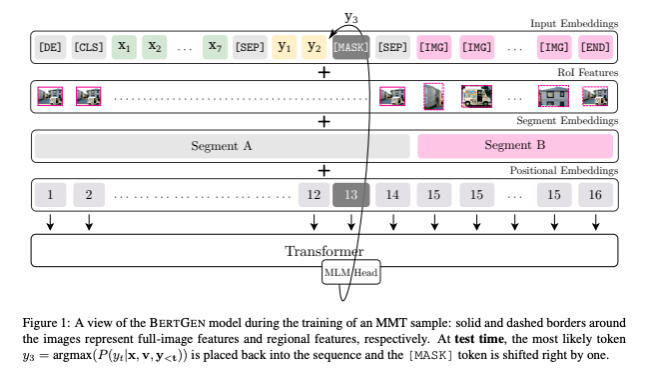
하나의 generator로 구성된 모델 특성 상, 모델의 input으로 텍스트 정보와 이미지 정보가 순차적으로 들어가고, input이 embedding 형식으로 변환되는 과정에서 텍스트 정보와 이미지 정보가 융합된다.
Result
해당 모델 또한 Multi30K 데이터셋을 활용하여 학습되었으며, 영어–독일어, 영어–프랑스어, 독일어–프랑스어 언어쌍들에 대한 모델 성능은 다음과 같았다.
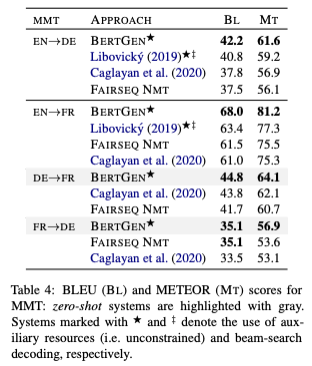
요컨대, BERTGEN의 성능은 기존의 IMT 모델을 능가하였고, 현시점 SOTA에 근접한 성능을 내고 있다.
So..?
현재 동일한 데이터셋(Multi30K dataset with Flickr 2016 test set)에 대한 BLEU score (혹은 METEOR score) 이라는 단일 지표에 의거하면 다섯개의 IMT 모델 중 BERTGEN이나 VTLM의 성능이 우수하다고 볼 수 있다. 그러나 이는 결코 절대적인 성능 지표로 여겨져서는 안된다. 논문들에서 발표한 score들은 영어–독일어 언어쌍에 국한된 실험 결과일 뿐 아니라, 각 모델들이 각기 다른 환경에서 학습된 후 산출된 결과값들이기 때문이다. 따라서 해당 지표에 대한 산술적인 비교는 별다른 효용을 가지지 않는다. 실제로 필자가 각 모델을 직접 돌려보며 실험해본 결과, 논문에서 발표한 공식 성능과 실제 성능 간 괴리가 큰 경우가 다수 존재했다.
이는 현재 절대우위에 있는 IMT 모델이 없다는 것을 보여준다. 다시 말해, 아직 크게 발전되지 못한 분야라는 것이고, 또 한편으로는 더 발전할 수 있는 여지가 있는 분야라는 것이다.
Reference
- Caglayan, O., Barrault, L., & Bougares, F. (2016). Multimodal attention for neural machine translation. arXiv preprint arXiv:1609.03976.
- Calixto, I., Liu, Q., & Campbell, N. (2017). Incorporating global visual features into attention-based neural machine translation. arXiv preprint arXiv:1701.06521.
- Calixto, I., Liu, Q., & Campbell, N. (2017). Doubly-attentive decoder for multi-modal neural machine translation. arXiv preprint arXiv:1702.01287.
- Calixto, I., Rios, M., & Aziz, W. (2018). Latent variable model for multi-modal translation. arXiv preprint arXiv:1811.00357. Chicago
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Ive, J., Madhyastha, P., & Specia, L. (2019). Distilling translations with visual awareness. arXiv preprint arXiv:1906.07701.
- Yao, S., & Wan, X. (2020, July). Multimodal transformer for multimodal machine translation. In Proceedings of the 58th annual meeting of the association for computational linguistics (pp. 4346-4350).
- Lin, H., Meng, F., Su, J., Yin, Y., Yang, Z., Ge, Y., ... & Luo, J. (2020, October). Dynamic context-guided capsule network for multimodal machine translation. In Proceedings of the 28th ACM International Conference on Multimedia (pp. 1320-1329). Chicago
- Li, B., Lv, C., Zhou, Z., Zhou, T., Xiao, T., Ma, A., & Zhu, J. (2022). On vision features in multimodal machine translation. arXiv preprint arXiv:2203.09173. Chicago
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Mitzalis, F., Caglayan, O., Madhyastha, P., & Specia, L. (2021). BERTGEN: Multi-task Generation through BERT. arXiv preprint arXiv:2106.03484.
- Gupta, K., Gautam, D., & Mamidi, R. (2021). ViTA: Visual-linguistic translation by aligning object tags. arXiv preprint arXiv:2106.00250.
- Hirasawa, T., Kaneko, M., Imankulova, A., & Komachi, M. (2022). Pre-Trained Word Embedding and Language Model Improve Multimodal Machine Translation: A Case Study in Multi30K. IEEE Access, 10, 67653-67668.
- Caglayan, O., Kuyu, M., Amac, M. S., Madhyastha, P., Erdem, E., Erdem, A., & Specia, L. (2021). Cross-lingual visual pre-training for multimodal machine translation. arXiv preprint arXiv:2101.10044.
