
부제 : 기계번역과 multimodal을 엮어야만 속이 후련했냐악 !
Multimodal Machine Translation (MMT)
Definition
드디어 본론이다.
Multimodal Machine Translation, 혹은 MMT. (이후 MMT로 통일) 이름만 봐도 어떤 연구 분야인지 직관적으로 파악이 가능하겠지만 명징하게 정의내리자면, MMT는 다음과 같이 설명할 수 있다.
텍스트 데이터만 사용하는 기존 기계 번역과 달리, 입력 텍스트와 관련된 다른 modality의 정보를 기계 번역 모델의 추가 입력으로 사용하는 task
MMT는 텍스트 정보와 텍스트 외부의 맥락 정보를 결합해 더 완전하고 정확한 번역을 하는 것을 목표로 하며, 멀티미디어 콘텐츠 등 비텍스트 정보가 중요한 도메인을 번역할 때 특히 유용하다고 알려져 있다.
여담이지만 필자가 5개월 남짓한 시간동안 연구했던 분야이기도 하다.
Machine Translation : Overview
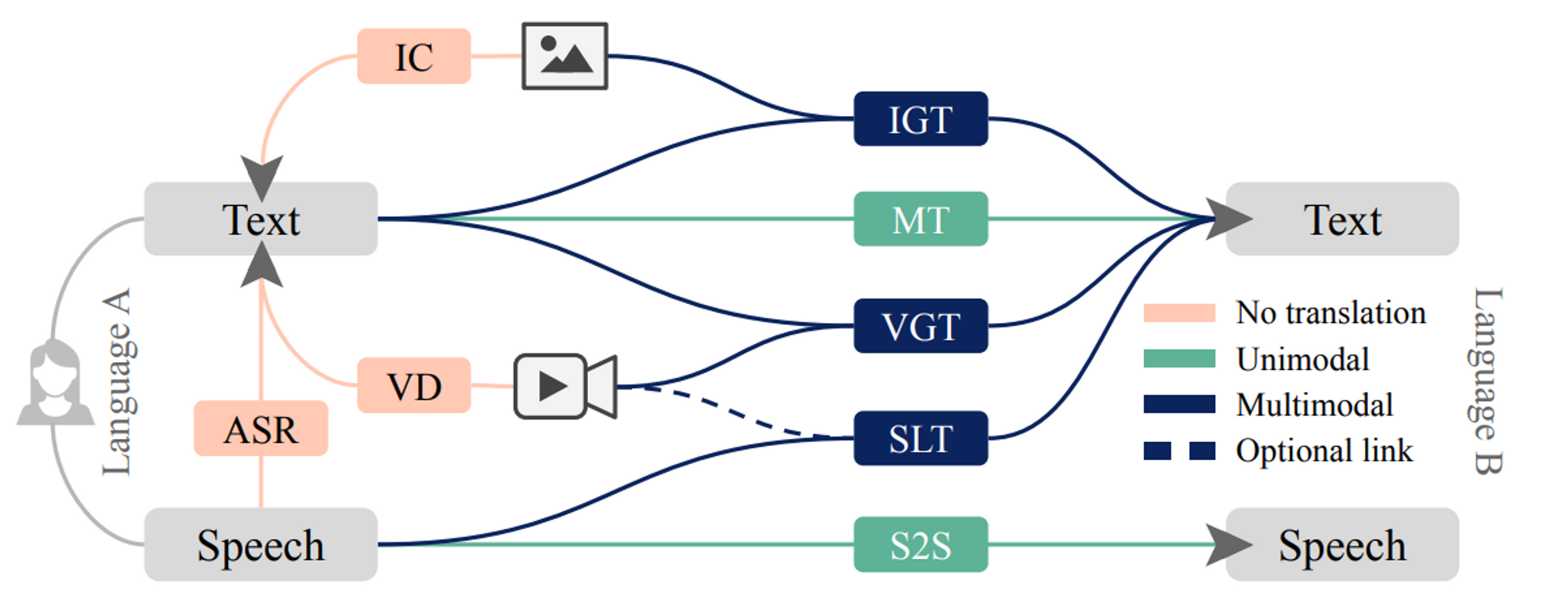
위의 그림은 MMT에 한정된 도표는 아니고, Machine Translation task 전반을 광범위하게 표현한 도표이다. 많은 사람들에게 MMT 이전에 Machine Translation task 자체가 생소할 수 있을 것이라고 생각한다. 도표에 나온 정도만이라도 Machine Translation에 대해 간단히 톺아보자.
Unimodal Machine Translation
Machine Translation (MT)

Machine Translation (MT)의 전형이다. 하나의 언어로 쓰인 텍스트를 다른 언어의 텍스트로 변환하는 것. 기본적으로 MT는 하나의 modality, text만 쓰이는 unimodal task이다. 따라서 MT model의 input으로는 Language A의 text만 들어가고, output으로 Language B의 text가 산출된다.
딥러닝을 활용한 MT task ( Neural Machine Translation , NMT ) 에 가장 널리 쓰였던 모델은 RNN 계열 모델(RNN, LSTM, GRU)들이다. 요새는 Transformer, 혹은 PLM ( Pretrained Language Model ) 기반의 NMT model들이 조금 더 핫한 것 같긴 하지만, 여전히 RNN 기반의 NMT model들도 쓰이고 있다.
혹시 NMT model에 관심이 간다면, Harvard NLP group과 SYSTRAN이 시작한 OpenNMT project의 레포를 살펴봐도 좋을 것 같다. 기본적인 RNN 기반의 NMT 모델은 물론, Transformer 기반의 NMT 모델도 공개되어 있기 때문이다. 현업에서 새로운 기계번역 모델을 개발할 때도 많이 참고하는 레포이다. 추천 ~
Speech-to-speech Translation (S2S)

Speech-to-speech Translation (S2S) 은 하나의 언어로 이루어진 발화를 다른 언어의 발화로 변환하는 task이다. 이 또한 MT와 마찬가지로 하나의 modality, speech만 쓰이는 unimodal task로, model의 input으로는 Language A의 speech만 들어가고 output으로 Language B의 speech가 산출된다.
S2S model은 automatic speech recognition (ASR), text-to-text machine translation (MT), text-to-speech (TTS) synthesis sub-system이 순차적으로 쌓인 구조로 이루어져 있다고 하는데, 이 정도만 다루고 호로록 넘어가도록 하겠다. 왜냐하면 필자도 speech data에 대해 잘 모르기 때문이다. Speech를 text로 translate하는 것은 여기까지만 다루고, 이 이후로는 일절 다루지 않을 예정이다. S2S model에 더 관심이 있다면 우리 모두의 친구 구글에게 물어보기를 추천한다.
Multimodal Machine Translation (MMT)
MMT는 기본적으로 두 개 이상의 modality를 고려하는 multimodal task이고, 그렇다 보니 필연적으로 MT task 외에도 cross-modal fusion task를 수반한다. MMT가 짱짱맨이지만 쉽지 않은 이유가 여기에 있다. 도표로는 아래와 같이 표현해볼 수 있겠다.
아, 참고로 도표에 정리된 것 이외에 다른 MMT 세부 분야가 있을 수 있다. 위의 도표에서 언급된 spoken language translation (SLT)가 그 대표적인 예시이다. 다만 앞으로 언급할 MMT 세부분야가 아래 두 분야라는 것이다. 오해 마시길 !
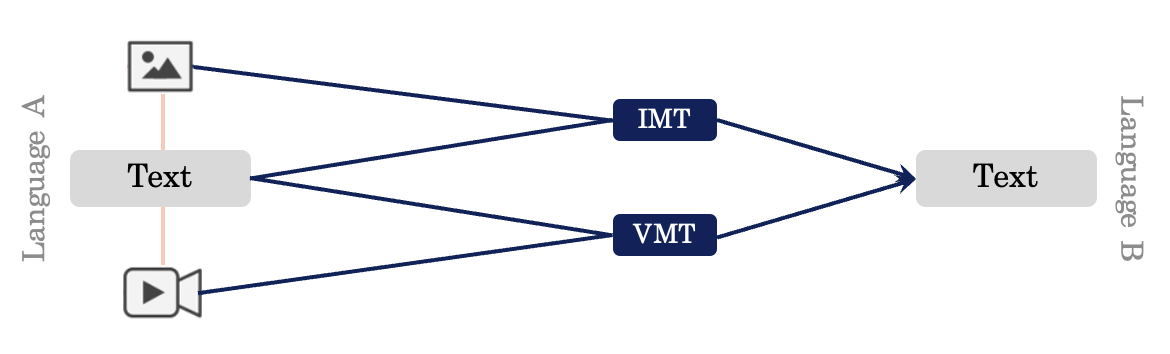
Image-guided Machine Translation (IMT)
입력 텍스트와 관련된 이미지 정보를 기계 번역 모델의 추가 입력으로 사용하는 Machine Translation task
좀 구체적으로 설명하자면, IMT model의 input으로는 Language A의 text와 해당 text와 연관된 이미지 정보가 들어가고, output으로 Language B의 text가 산출된다.
Video-guided Machine Translation (VMT)
입력 텍스트와 관련된 비디오 정보를 기계 번역 모델의 추가 입력으로 사용하는 Machine Translation task
위와 유사하게 VMT model의 input으로는 Language A의 text와 해당 text와 연관된 비디오 정보가 들어가고, output으로 Language B의 text가 산출된다.
( 갑자기 이렇게 대충 다루고 넘어가면 어떡하냐 ? 하고 생각할 수 있으나 IMT, VMT는 단일 주제로 포스팅을 쓸 생각이니 걱정하지 마시라 ! )
MMT Classification
요컨대, 필자가 앞으로 다루고자 하는 MMT의 세부 분야는 아래와 같이 나눠볼 수 있다.

이어지는 포스트들에서는 IMT와 VMT를 각각 딥하게 다룰 생각이다. 생각보다 재밌을테니 기대하시라.
