EFK + EKS + DataDog(로그 관리하기)
도입배경
여러 프로젝트의 유지보수를 위해서 DataDog에 로그를 수집하였다. 하지만 여러 프로젝트에서 많은 로그를 수집하다보니 점점 비용이 높아졌다. 그래서 DataDog을 통해서 로그를 관리하되 에러가 발생한 로그만 수집하고 나머지 로그들은 오픈 소스인 elasticsearch, Kibana를 통해 관리하여 비용 절감을 노렸다. 물론 aws에서 제공하는 서비스를 사용하면 쉽게 구성할 수 있지만 도입배경이 비용 절감이기 때문에 직접 구성해서 사용해야 했다.
아키텍쳐
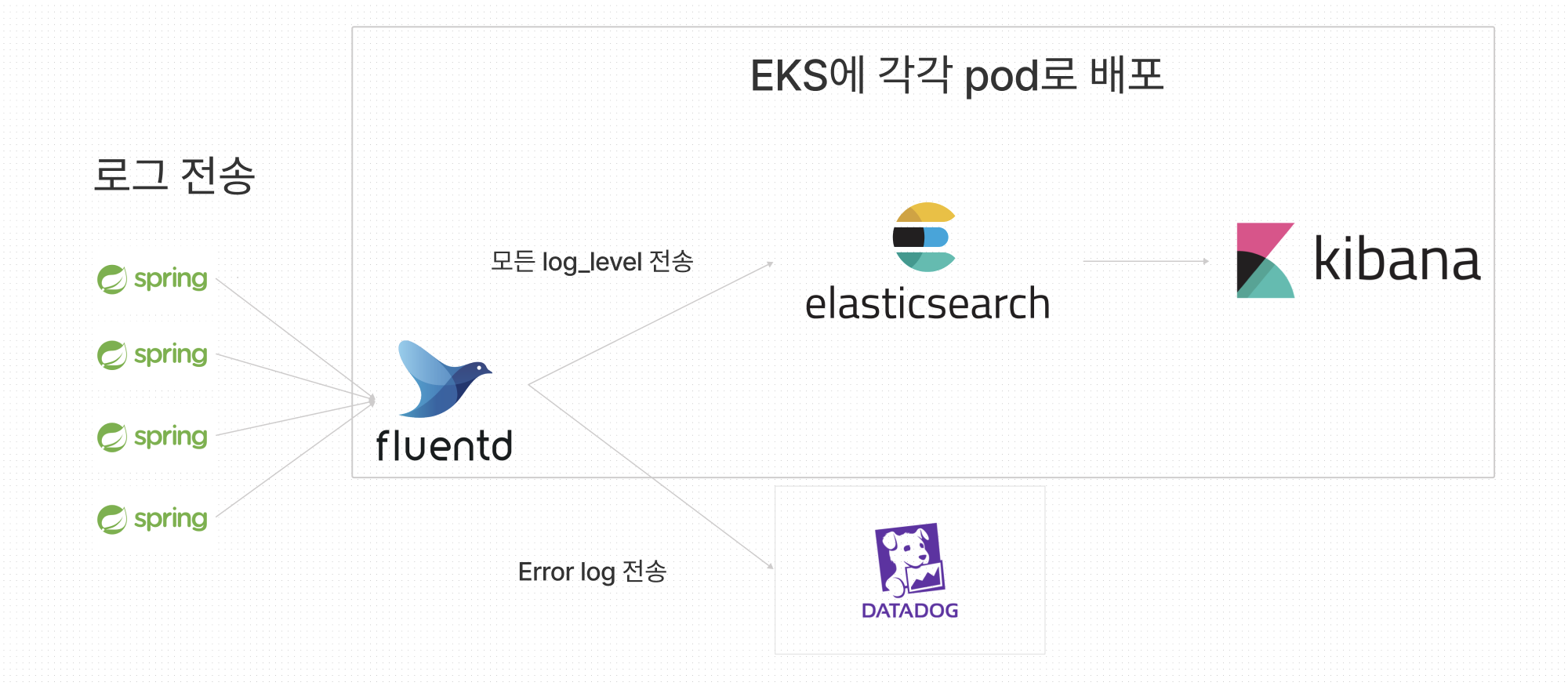
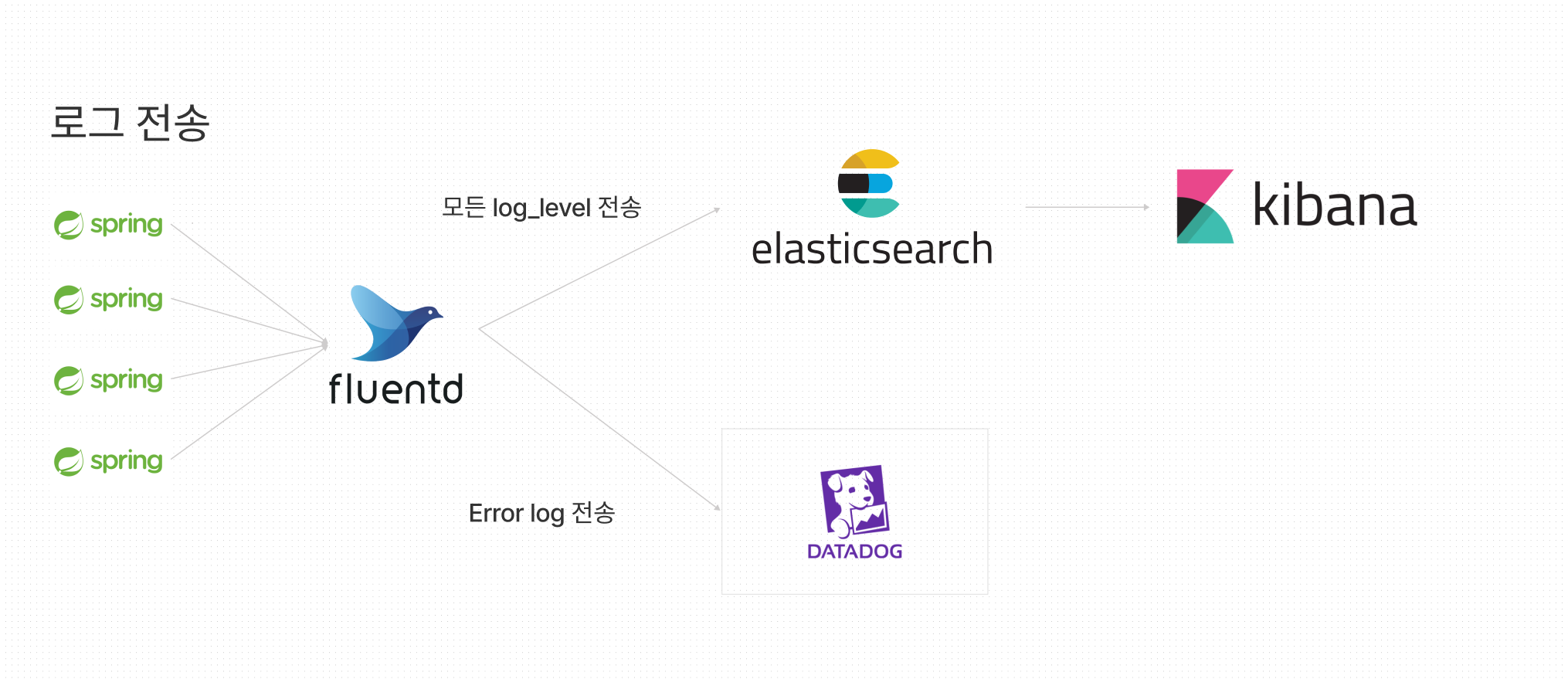
데이터 flow
- 프로젝트(스프링)에서 로그 발생
- 발생한 로그를 EKS로 띄운 fluentd로 tcp 통신을 통해서 전송
- fluentd에서 전송받은 로그를 처리하는데, 전달받은 모든 로그는 일단 elasticsearch로 전송
- elasticseaerch에서 kibana로 전송하여 시각화
- fluetnd에서 전송받은 로그 level이 error면 DataDog으로 로그 전송하여 시각화
작업 진행
스프링에서 fluetnd로 로그 전송 by.logback
eks에서 pod 외부IP, port 확인하기 위한 명령어: ' kubectl get svc -n 네임스페이스 '
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<include resource="org/springframework/boot/logging/logback/console-appender.xml" />
<!-- If there is no ENV var FLUENTD_HOST then use localhost -->
<property name="FLUENTD_HOST" value="${FLUENTD_HOST:- eks에서 띄운 fluestd 주소}"/>
<property name="FLUENTD_PORT" value="${FLUENTD_PORT:- eks에서 띄운 컨테이너 포트번호}"/>
<appender name="FLUENT_TEXT" class="ch.qos.logback.more.appenders.DataFluentAppender">
<!-- Check tag and label fluentd info: https://docs.fluentd.org/configuration/config-file-->
<tag>'태그 이름'</tag>
<label>'내용'</label>
<remoteHost>${FLUENTD_HOST}</remoteHost>
<port>${FLUENTD_PORT}</port>
</appender>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n
</Pattern>
</layout>
</appender>
<root level="info">
<appender-ref ref="CONSOLE" />
<appender-ref ref="FLUENT_TEXT" />
</root>
</configuration>스프링에서 fluentd로 직접 로그를 전송하기 위해서는 아래 2개를 추가해야한다.
implementation group: 'org.fluentd', name: 'fluent-logger', version: '0.3.4'
implementation group: 'com.sndyuk', name: 'logback-more-appenders', version: '1.5.6'공식 문서에는 fluent-logger만 추가하면 된다고 하였는데 실제로 작업해보면 logback-more-appenders도 필요하다. 이를 몰라서 정말 많이 헤맸다.
공식문서: https://github.com/fluent/fluent-logger-java
fluentd config 설정
스프링에서 전달받아 elasticsearch, DataDog으로 전송하기 위해선 각각의 plugin이 필요하다.
elasticsear 공식문서: https://github.com/uken/fluent-plugin-elasticsearch
DataDog 공식문서: https://github.com/DataDog/fluent-plugin-datadog
<source> // 스프링에서 로그를 받는 통로
@type forward
port 24224
</source>
<match **> // 스프링에서 로그를 받고 로그를 처리해주는 로직
@type copy // multi output을 받기위함
<store> // 일단 받은 로그를 elasticsearch로 전송
@type elasticsearch
host eks에서 띄운 elasticsearch의 host
port eks에서 띄운 = port
index_name '원하는 index'
include_tag_key true
tag_key tag
include_timestamp true
time_key timestamp
</store>
<store> // 일단 받은 로그를 SENDERRROR 라벨로 전송
@type relabel
@label @SENDERROR
</store>
</match>
<label @SENDERROR> // 전달 받은 로그를 검사
<filter **> // 필터를 통해서 해당 로그 level 검사, ERROR가 아니면 통과하지 못함
@type grep
regexp1 level ERROR
</filter>
<match>
@type datadog
@id awesome_agent
api_key DataDog 토큰
include_tag_key true
tag_key tag
service tag
<buffer>
@type memory
flush_thread_count 4
flush_interval 3s
chunk_limit_size 5m
chunk_limit_records 500
</buffer>
</match>
</label>fluentd의 대표적인 사용 용도가 eks 클러스터에 설치하여 전역적으로 클러스터안에서 발생하는 로그를 수집하는 용도로 많이 상용되는데, 도입목표가 클러스터내에 있는 프로젝트 뿐만 아니라 다른 클러스터의 프로젝트의 로그도 수집하기 위해서 pod로 띄우는 방식을 채택하였고 지원을 해주지 않기 때문에 직접 이미지를 커스텀해서 사용했다.
fluentd-ui를 통해서 fluentd 관리의 편리성을 더하였다.
fluentd-ui 공식문서: https://github.com/fluent/fluentd-ui
fluentd.yaml(EKS에 pod로 올리기)
apiVersion: v1
kind: Service
metadata:
name: fluentd
namespace: 개인 네임스페이스
labels:
app: fluentd
spec:
ports:
- port: 9292
name: ui
- port: 24224
name: link
selector:
app: fluentd
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: fluentd
namespace: 개인 네임스페이스
labels:
app: fluentd
spec:
replicas: 1
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
containers:
- name: fluentd
image: 커스텀 이미지
ports:
- containerPort: 9292
name: ui
- containerPort: 24224
name: link
여기서 고생을 정말 많이하였다. 컨테이너에 포트를 하나만 열어줘서 fluentd-ui는 보이는데 스프링에서 로그를 전송받지 못하는 문제가 발생하였다. 9292는 ui로 접근하는 포트이고, 24224는 서버에서 로그를 보내는 포트로 총 2개의 포트를 열어줘야한다.
elasticsearch.yaml(EKS에 pod로 올리기)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: 클러스터 이름
namespace: 원하는 네임스페이스
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: gp2 #do-block-storage #gp2 #do-block-storage
resources:
requests:
storage: 5Gi
---
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: kongservice-logger
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
type: LoadBalancer
kibana.yaml(EKS에 pod로 올리기)
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: 원하는 네임스페이스
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: 원하는 네임스페이스
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601