ORM(Object Relation Mapping)
들어가기전
이전에도 언급하였지만 개발의 기술(도구)의 발전은 이전 기술의 불편함에서 시작된다.
따라서 ORM이라는 것도 이전의 어떤 기술의 불편함을 해결하고자 탄생한 개념이다.
뭐가 불편했나요?
이전의 서버 개발자들은 서버에 연결되어 있는 데이터베이스를 직접 관리했어야 했다. 이는 안그래도 많은 것을 해야하는 서버 개발자들에게 큰 부담이였다. 예를들어서 자바 서버 개발자라고 하면 자바도 알아야 하고 데이터베이스를 제어하는 Sql 문법도 알아야 했기 때문이다.
어떻게 불편함을 해소했나요?
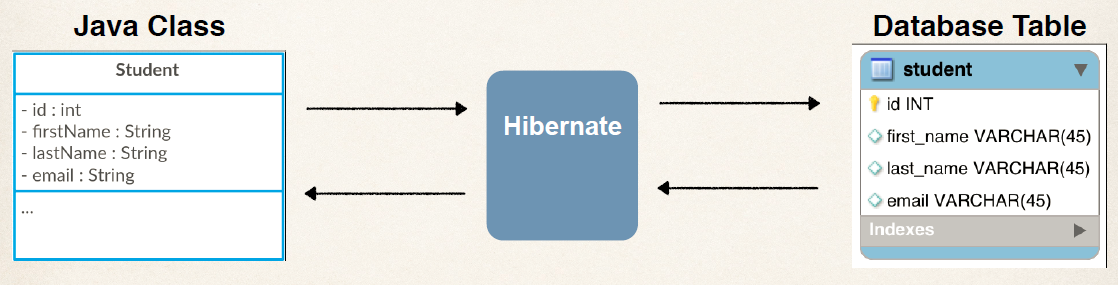
서버 개발자들이 직접 sql문을 작성하는 것이 아니라 사용하는 언어의 객체와 데이터베이스를 연결 시켜줬다. 즉 Java언어로 요청이 들어오면 ORM을 통해서 SQL문으로 번역되고 데이터베이스에서 동작을 처리해준다. (이전의 설명한 JSON과 비슷함) 쉽게 말해 자바의 객체를 테이블로 매핑해주는 일을 한다. 그래서 테이블을 sql문으로 직접 구성할 필요없이 객체로 만들면 알아서 테이블로 인식하고 생성 및 조작을 할 수 있다.
단점은 뭔가요?
ORM을 통해서 편리하게 SQL문을 사용했지만 이게 자주 사용하는 기능만 SQL문으로 번역을 할 수 있기 때문에 편리성은 챙겼지만 효율성은 챙기지 못하였다. 따라서 만약 SQL 실행 속도가 개발자의 기준보다 느리다면 개발자는 SQL문의 속도를 개선하기 위해서는 SQL문을 직접 튜닝해야한다. (복잡하고 많은 조인이 일어난 경우)
JPA
특정 언어를 SQL문으로 번역하여 실행해주는 ORM 중에서 자바 언어를 SQL문으로 번역해주는 ORM을 JPA라고 한다. 즉 자바에서 SQL 쿼리를 직접 짜지 않고 사용하기 위해서는 JPA를 사용해야 한다. 좀더 정확하게 이야기 자바와 관계형 데이터 베이스가 통신하는 방법을 정의한 인터페이스이다.
추가)
Node.js의 ORM = Sequelize
Django의 ORM = Django (워낙 편리한 기능이기 때문에 Django 자체적으로 지원 D)
Spring Data JPA(Hibernate)
Spring Data JPA는 JPA(사용 방법이 정의되어 있는 인터페이스)를 기반으로 만든 구현체이다.
+) fetch
@ToString.Exclude
@OneToMany(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private List<Address> addresses = new ArrayList<>();fetch에 lazy 값을 주게되면 해당 객체를 부를때 객체에 연결된 모든 정보를 한번에 불러오는 것이 아니라 객체의 특정 성분을 호출을 할때 그제서야 sql문을 날려서 정보를 가져오는 방식이다.
키워드: 즉시로딩 지연 로딩
장점: 필요한 정보만 불러와서 성능을 상향 시킬수있다.
사용법
public interface 엔티티이름Repository extends JpaRepository<엔티티 이름, 엔티티 아이디 타입>{
//원하는 내용 ex
해당 엔티티 안에서 userid 칼럼이 있는 모든 항목
List<엔티티 이름> findAllByUserId(Long userID);
해당 엔티티 안에서 title이라는 칼럼에 어떤것인 항목 1개 조회
엔티티 이름 findByTitle(String 어떤것);
}자세한 항목 (공식문서를 보면 더 자세한 기능을 사용 가능)
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods
