aws 설명
Remote Dictionary Server의 약어인 Redis는 데이터베이스, 캐시, 메시지 브로커 및 대기열로 사용하는 빠르고 오픈 소스, 인 메모리 키-값 데이터 스토어입니다. 이 프로젝트는 Redis의 원 개발자인 Salvatore Sanfilippo 씨가 이탈리아 스타트업의 확장성을 높이려 노력하는 과정에서 시작되었습니다. 현재 Redis는 1밀리초 미만의 응답 시간을 제공하므로 게임, 광고 기술, 금융 서비스, 의료 서비스 및 IoT 분야에서 실시간 애플리케이션을 위해 초당 수백만 건의 요청을 지원할 수 있습니다. Redis는 캐싱, 세션 관리, 게임, 리더 보드, 실시간 분석, 지형 공간, 라이드 헤일링, 채팅/메시징, 미디어 스트리밍 및 게시/구독 앱에서 주로 사용됩니다.
Redis의 특징
- 일반적인 DB와 다르게 디스크나 SSD에 저장되는 것이 아닌 서버의 주 메모리에 저장되기 때문에 빠르게 데이터에 접근이 가능하다. 일반적인 DB는 데이터를 호출하고 사용하기 위해서는 서버에서 디스크까지 왕복해야 하는데 Redis는 서버에서 바로 데이터를 호출한다.
사용 가능한 데이터 구조
- 문자열
- List
- Set
- Sorted Set
- Hash
- Bitmap
- HyperLogLogs
사용 사례
- 캐싱
- 채팅, 메시징 및 대기열
- 게임 순위표
- 세션 스토어
- 다양한 미디어 스트리밍
- 지리 공간
- Machine Learning
- 실시간 분석
Collection
redis는 in-memory 데이터 베이스이다. 기존의 데이터 베이스보다 빠른 이유는 데이터가 저장되는 위치가 다르기 때문이다. 디스크에 저장되는 것이 아닌 메모리에 저장되기 때문에 데이터의 왕복이 빠르기 때문에 redis를 사용한다. 다른 in-memory 데이터베이스인 memcached를 사용하지 않고 redis를 사용하는 이유는 다양한 자료구조를 지원하기 때문이다. redis는 key-value 형태로 데이터를 저장한다.
redis의 key
redis는 key-value 형식으로 데이터가 저장된다. 즉 데이터를 조회하려면 key를 입력해야한다.
key는 문자열이고 모든 이진 시퀸스를 키로 사용할 수 있다. 즉 빈칸도 키가 될 수 있다. key의 최대 크기는 512MB이다.
redis는 빠른 조회를 위해서 사용하는 것인 만큼 데이터를 조회 할 때 사용되는 키의 값이 길면 조회하는데 시간이 오래 걸린다. 따라서 가급적이면 너무 긴 키를 사용하지 않는 것이 권장된다.
그렇다고 해서 가독성을 줄여가면서 길이를 줄일 필요는 없다.
일반적으로 oject-type:id 형태를 권장한다. weather_week:56와 같이 사용하면 된다.
redis의 만료기간
redis는 일반적인 db가 아닌 메모리상에 존재하는 db임으로 저장될 수 있는 데이터는 한정적이다. 저장 할 수 있는 데이터가 한정적인 만큼 오래된 데이터는 날려줘야하는데 이때 사용하는 방법이 expire 값을 주는 것이다. 정해진 기간이 되면 자동으로 데이터가 날아감으로써 너무 많은 데이터가 db에 쌓이지 않게 해준다.
redis의 동작
서버에서 데이터의 요청이 들어오면 db에 접근 하는 것이 아니라 캐시(redis)에 먼저 원하는 값이 있는지 찾아보고 있으면 db까지 내려가는 것이 아니라 바로 캐시에서 반환해준다.(cache Hit)
캐시 안에 원하는 데이터가 없으면 그때 db에 접근하여 데이터를 가져와서 서버에게 반환해주고 그와 동시에 캐시(redis)에 저장하여 다음번에 사용이 가능하게 해준다.(cache Miss)
redis의 위험성
redis를 사용하면 편리성을 증가하였지만 데이터의 입출력 과정에 한번의 중간 과정이 추가로 생기는 것이기 때문에 데이터 유실의 문제가 생긴다.
즉 클라이언트에서 데이터를 요청을 하면 그 데이터가 캐시에 저장되어 있다면 db까지 내려가지 않고 바로 반환되는데 캐시에 저장된 값에 문제가 생기면 클라이언트가 보낸 요청의 원본 값이 뭐였는지 확인하기 힘들다.
그래서 캐시를 하나만 가지고 있는게 아니라 여러개의 캐시를 가지고 있고 한개의 캐시가 다운되면 멀쩡한 캐시를 바로 연결하여 사용하는 방식으로 문제를 해결하고 있다.
- redis(캐시) 프로세스가 다운되면 메모리 안에 저장된 데이터들은 유실이 된다.
- 여기서 미리 복제해둔 다른 redis(캐시)를 가지고 있다면 데이터를 같이 저장해주고 있어서 데이터 유실은 발생하지 않는다.
- 하지만 다운된 redis(캐시)의 연결을 끈고 멀쩡한 복제된 redis(캐시)을 연결한 뒤에 다시 배포해야 되는데 위의 작업을 하는 동안 서비스는 불안정하고 이 시간동안 요청된 데이터는 유실될 가능성이 높다. 또한 연결을 변경하는 동안 많은 데이터 요청이 들어오면 dbms가 다운될 수 있다.
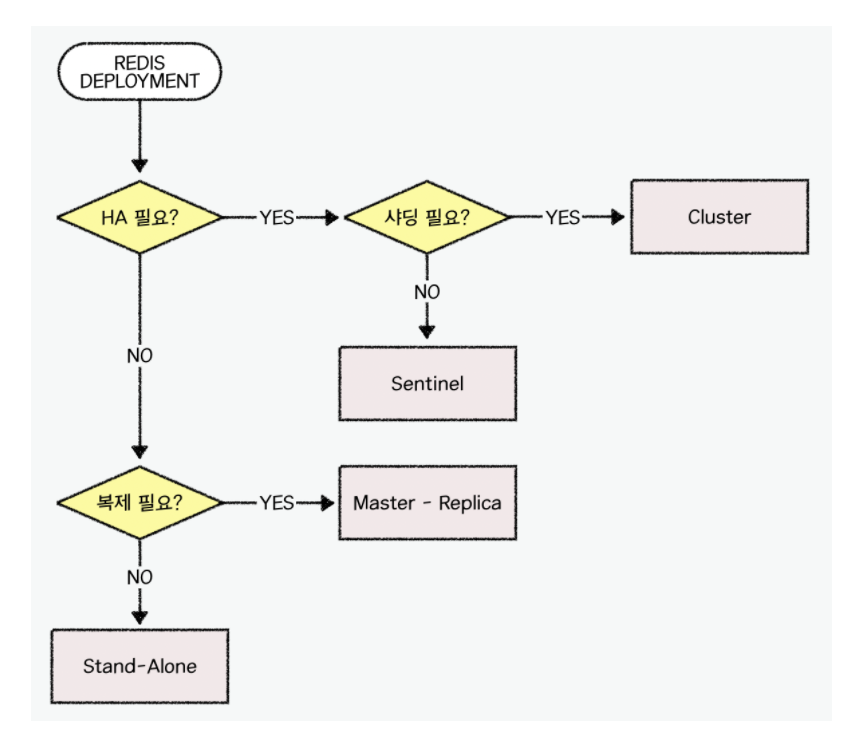
위의 상황을 해결하기 위해서 등장한게 Sentinel이다.
Sentinel
Sentinel은 마스터 노드와 복제 노드를 계속 모니터링하고 있다가 문제가 발생하면 마스터 노드를 끈고 복제 노드를 마스터 노드로 승격시키기 위해서 자동 페일오버를 진행한다.
이런 작업을 하기위해서는 적어도 3개의 Sentinel 인스턴스가 필요하다. 각각의 Sentinel 인스턴스는 모든 노드를 감시하고 서로 연결되어있어 장애를 바로 인식 할 수 있다. 패일오버는 연결된 Sentinel 인스턴스 중 과반수가 이상을 감지하면 페일오버를 시작한다.
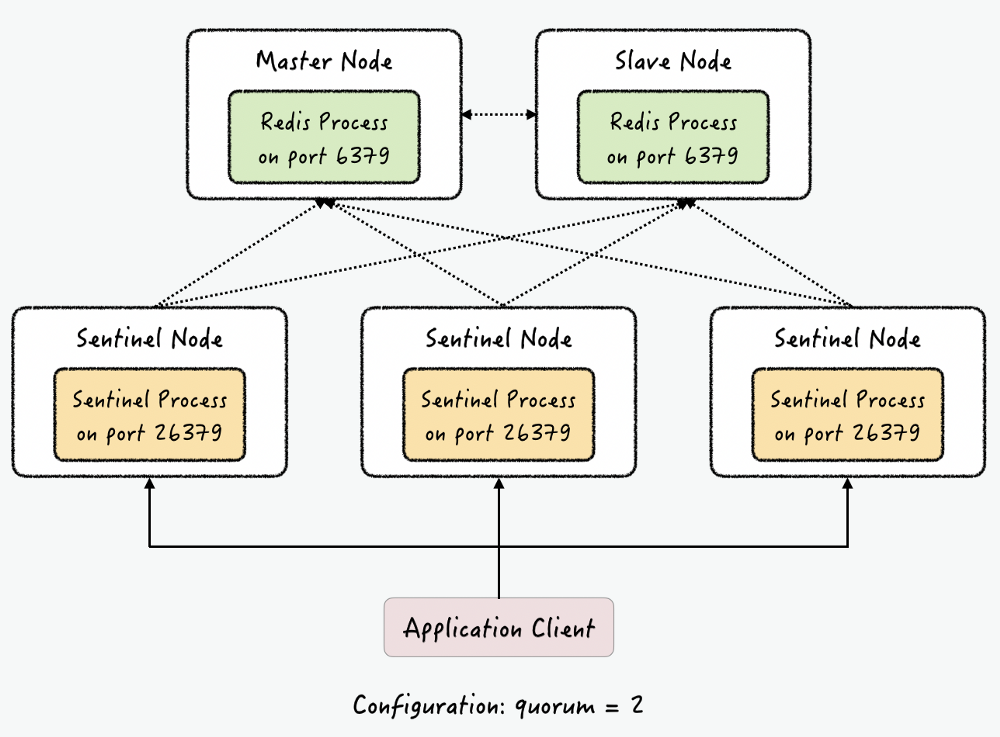
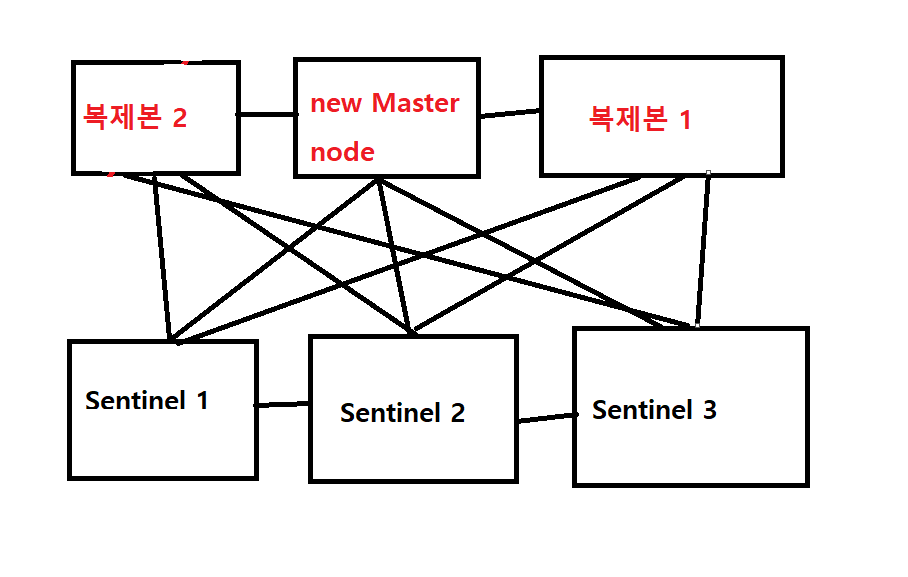
구조는 위의 사진 처럼 되어있는데 어플리케이션과 바로 master노드와 연결 되어 있는 것이 아니라 Sentinel 인스턴스를 거쳐서 연결 되어 있다. 오류가 발생하면 Sentinel 인스턴스가 현재 마스터 노드의 ip와 포트번호를 알려준다. 만약 오류가 발생해서 페일오버가 발생하면 기존의 master 노드를 연결하는 것이 아니라 복제본인 slave node의 ip와 포트번호를 알려준다.
페일오버(Failover)
Sentinel에서 마스터 노드가 문제가 생기면 페일오버를 진행한다고 하였는데 그럼 페일오버란 무엇일까?
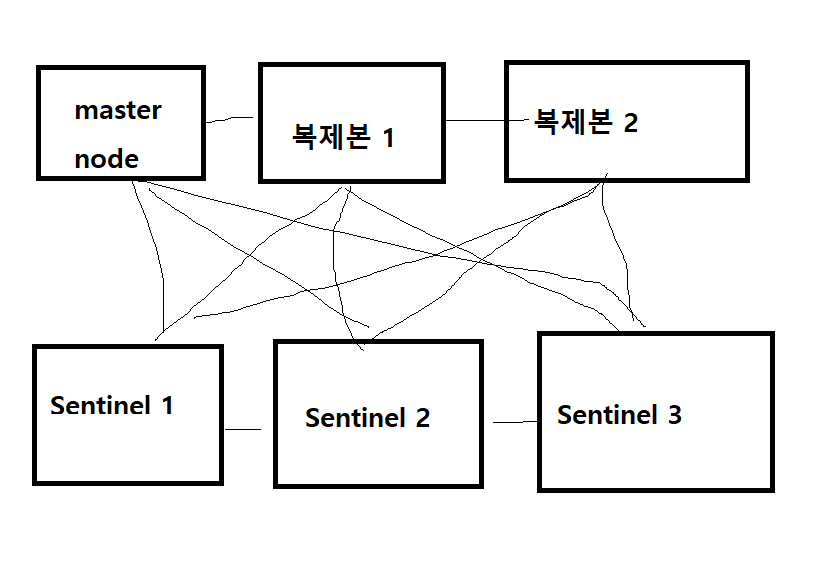
- 다음과 같이 연결되어 있는 구조가 있다고 했을 때 만약에 master node에 문제가 발생을 하였다.
- 처음 마스터 node의 문제가 있다고 감지한 Sentinel에서 투표를 시작한다.
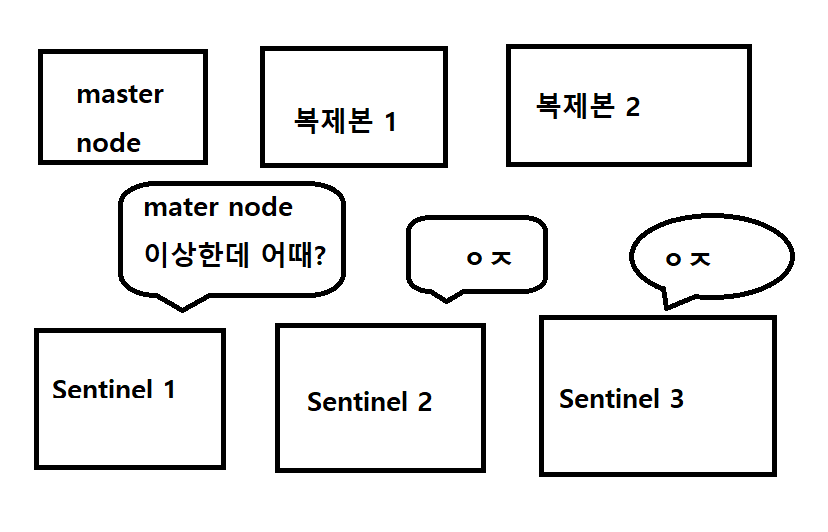
- 다른 sentinel에서 과반수의 동의를 이뤄내면(다른 sentinel에서도 master node에 연결이 안되면) 페일오버가 일어난다.
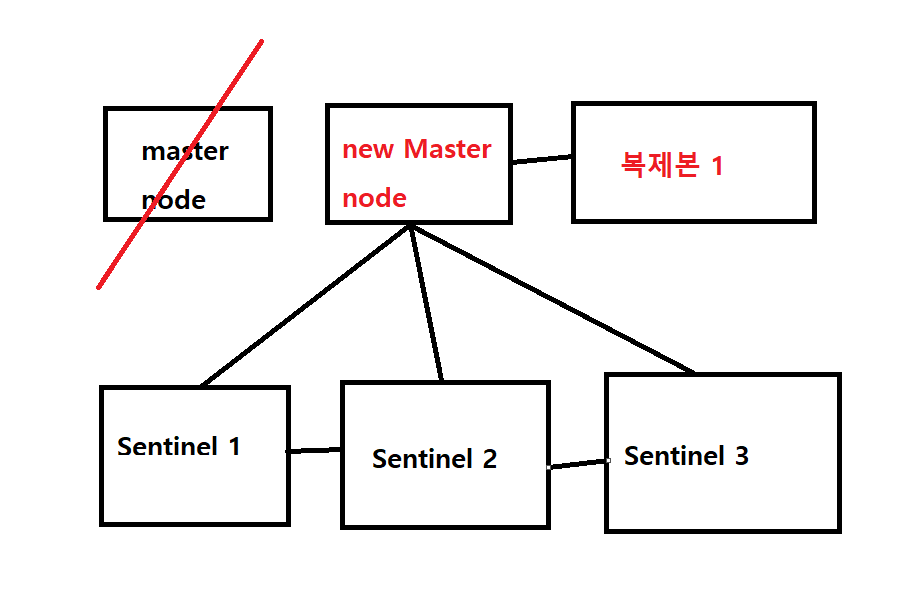
- 기존의 master node와 연결을 끊고 복제본 중 하나를 master node로 승격한다.
- 새로운 master node를 연결한다.
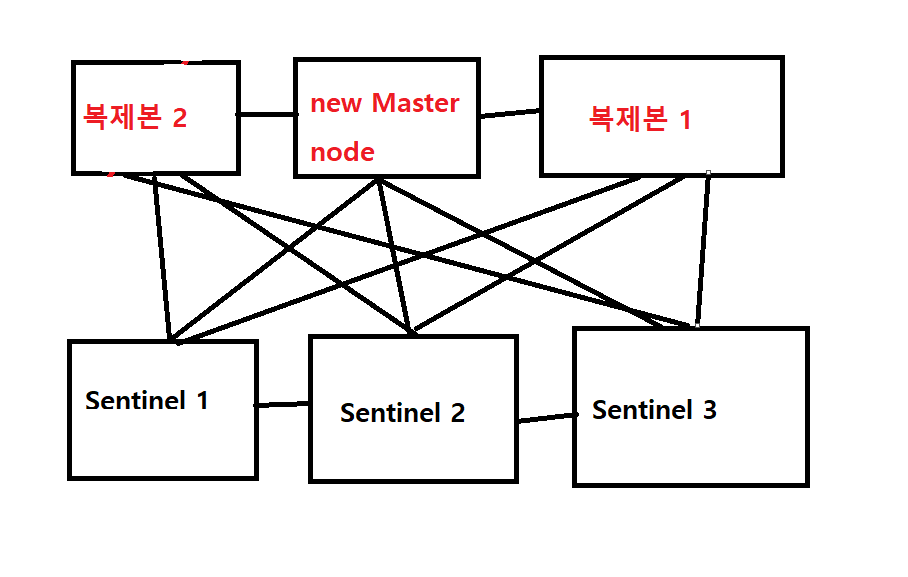
- 만약에 고장났던 옛날 master node가 복구가 되면 다시 master node로 승격되는 것이 아니라 새로 승격된 master node의 복제본으로 설정된다.
Cluster
클러스터는 기존의 Sentinel에서 한번 더 발전된 형태이고 redis를 많이 사용하는 가장 큰 이유 중 하나는 바로 클러스터링 때문이다.
- 데이터셋을 여러 노드에 자동으로 분산 -> 확장성, 고성능
- 일부 노드가 다운되어도 계속 사용 가능 -> 고가용성
redis cluster 구성
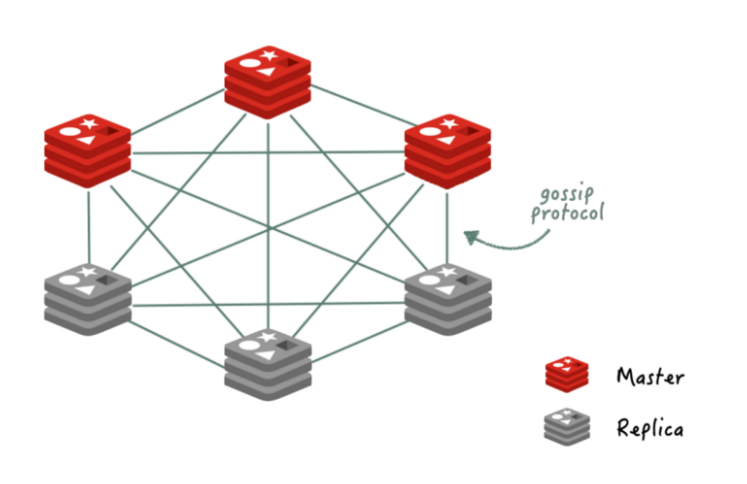
redis 클러스터를 사용하기 위해서는 최소 세 개의 마스터 노드가 필요하고 각각의 마스터 노드는 최소 한개의 복제 노드를 가지는 것이 가장 이상적인 구조이다.
sharding
일을 분배하는 과정
총 16384개의 슬롯에 데이터를 나눠 담는 방식 노드가 많으면 많을 수록 세분화된다.
3개를 기준으로 하면
0~5500, 5501~11000, 11001~16383 이렇게 3구간으로 나뉜다.
해시 슬롯은 마스터 노드에서 자유롭게 옮겨질 수 있기 때문에 새로운 노드를 추가하거나 삭제하기 쉽다. 그냥 옮겨주면 되기 때문이다.
페일오버(Failover)
이전의 sentinel에서는 sentinel 인스턴스에서 감시를 통해서 장애를 감지 했다면 cluster의 failover은 모든 노드가 서로서로를 감시한다는 차이가 있다.
sentinel과 마찬가지로 다운된 노드와 연결을 끊고 복제본을 마스터로 승격 시키고 연결을 한다. 여기서 마스터 노드에 연결된 복제 노드 2개 이상이면 복제본이 없는 마스터 노드에게 양도 할 수 있다.
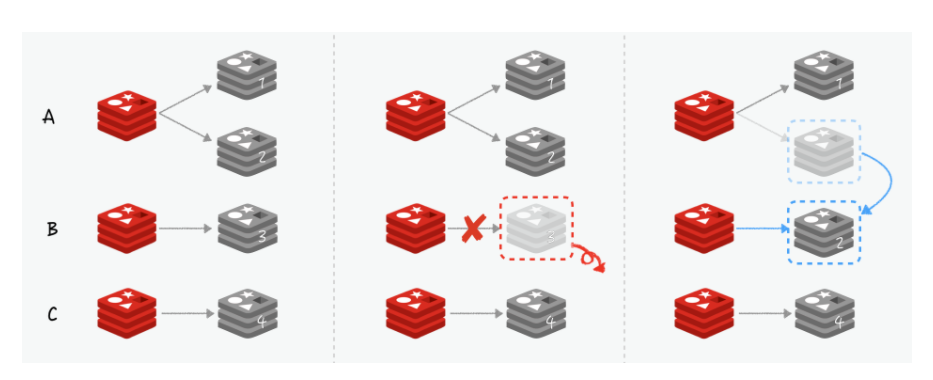
cluster의 사용
cluster는 마스터 노드를 여려개로 나눠 저장공간을 분할 하는 방식이다. 그럼 클라이언트는 데이터를 요청 할 때 몇번째 저장공간에 데이터가 담겨 있는지 항상 신경을 써야 되는 것일까?
결론은 그렇지 않다. 클라이언트에서 데이터를 요청을하면 redis 캐시에서 알아서 해당 데이터가 몇번째 저장소에 담겨있는지 알려주고 해당 데이터를 꺼내서 전달한다.
즉 샤딩을 생각하지 않고 아무데나 던져도 알아서 redis 서버가 데이터를 찾아서 가져다준다.
- 데이터를 요청 및 저장
- 연결된 master node가 올바른지 검사 올바르다면 데이터 처리
- 올바르지 않다면 클라이언트에 메시지로 해당 데이터가 저장된 위치를 알려주고 제대로 된 주소에 가서 데이터 처리
redis 사용 목적
redis를 사용하는 이유는 빠른 요청 및 효율적인 사용을 위해서 redis를 사용한다.
이런 목적을 이루기 위해서는 redis가 더 효율적일 때만 사용을 해야한다. 즉 캐시용으로 사용하는 것인지 저장소용도로 사용을 하는지를 잘 고민해 봐야한다.
무턱대고 redis를 사용하면 오히려 성능이 저하될 수 있다.
참조
https://velog.io/@hyeondev/Redis-%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
https://medium.com/garimoo/%EA%B0%9C%EB%B0%9C%EC%9E%90%EB%A5%BC-%EC%9C%84%ED%95%9C-%EB%A0%88%EB%94%94%EC%8A%A4-%ED%8A%9C%ED%86%A0%EB%A6%AC%EC%96%BC-03-1d5fa7ca9682
ec2에 redis 설치하기
https://artiiicy.tistory.com/24
make가 실행이 안될 때
sudo apt install pkg-config
