해시 (Hash)
- 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 크기의 고유 값으로 변환하는 함수
- 해시 테이블, 딕셔너리(Dictionary), 집합(Set) 등과 같이 데이터를 빠르게 검색하고 저장하는 데 사용
- 매핑 전 원래 데이터 값을 키(key), 매핑 후의 데이터 값을 해시값(hash value), 과정 자체를 해싱(hashing)이라고 함
- 해시 가능 객체 조건: 객체가 변경 불가(Immutable)해야 함
- 숫자(int, float)
- 문자열(str)
- 튜플(tuple)
- 불변 집합(frozenset)
- 해시는 해시값의 개수보다 대개 많은 키값을 해시값으로 변환(many-to-one)하기 때문에 해시가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 해시충돌(collision)이 발생 (* 아래에서 다시 언급 예정)
- (A, B 두가지 키가 있다고 가정) hash function을 통해 해시값을 얻게 되어 hash 값이 동일하게 3으로 나온 경우
- 즉, 해시 값이 동일한 두 객체가 있을 수 있으며 서로 다른 키가 동일한 해시 값을 가질 때 충돌이 발생함
- 서로 다른 키가 같은 해시로 변경되면 같은 공간에 2개의 value가 저장되므로 key-value의 1:1 매핑이 성립되지 않음
- 해시충돌은 필연적으로 발생하며, 해시값 전체에 걸쳐 균등하게 발생하도록 함
- 해시충돌을 처리하기 위해 딕셔너리를 사용하며 아래와 같은 방법으로 해결하고자 함 (* 딕셔너리는 충돌을 관리하고 중복을 방지하는 알고리즘)
- 분리 연결법 (Separate Chaining): 충돌한 데이터를 연결 리스트로 관리)
- 개방 주소법 (Open Addressing): 충돌 시 다음 빈 자리를 찾아 데이터를 저장
해시 테이블
- 해시 맵, 사전
- 키(key)와 값(value)으로 구성된 자료구조로 데이터를 빠르게 검색하고 저장할 수 있음
- 해시를 사용하여 키를 해시값으로 매핑하고, 해시값을 index 혹은 주소로 삼아 데이터의 값(value)을 키와 함께 저장하는 자료구조
- 해시는 입력된 키를 통해 고유한 해시 값을 생성하며, 이 값을 이용해 테이블에 값을 저장하거나 검색함
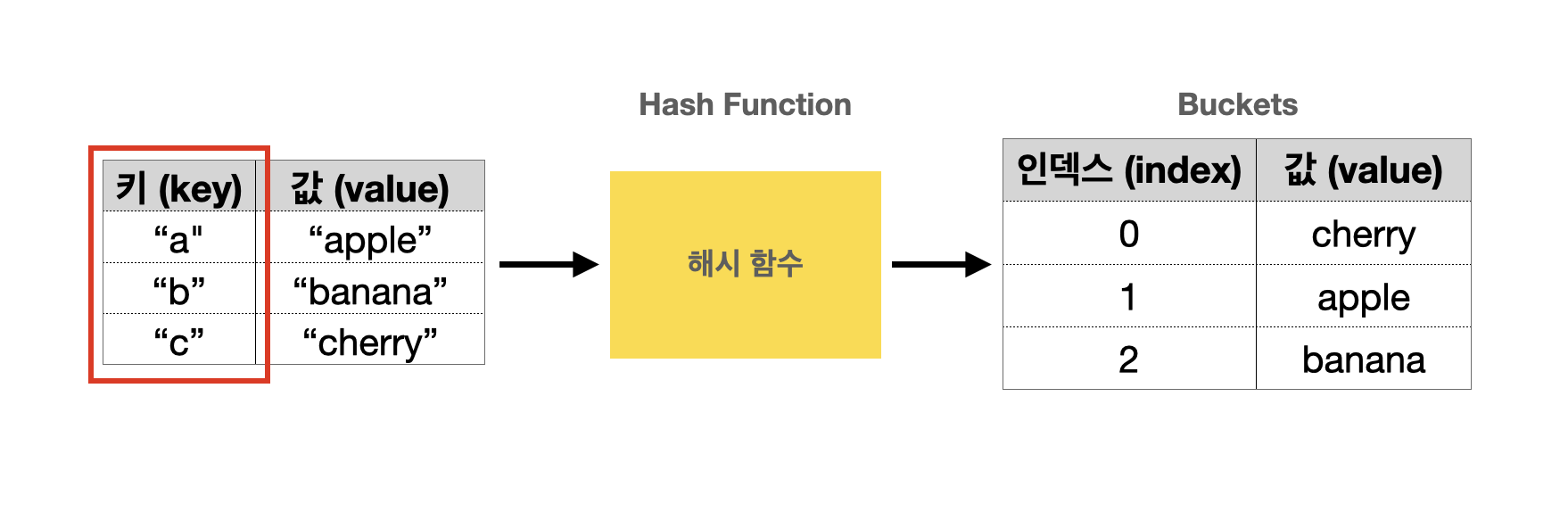
위와 같이 키와 값이 들어있는 경우, 해시 테이블에 저장하는 방법은 어떻게 될까?
해시 함수가 키의 아스키코드를 테이블 크기인 3으로 나눈 나머지를 구한다고 가정해보자
a의 데이터를 저장할 때, hash_function("a")(=ASCII 97) % 3(테이블 크기) 을 통해서 index 값인 1을 구해내고, array[1] = "apple"을 저장함
각 키의 해시 값을 계산하면 다음과 같다.
“a” → 해시 함수(97 % 3) → 1
“b” → 해시 함수(98 % 3) → 2
“c” → 해시 함수(99 % 3) → 0
이런 형식으로 데이터를 저장하면, key에 대한 데이터를 찾을 때, hash_function을 한번만 수행하면 array 내에 저장된 index 위치를 찾아낼 수 있기 때문에 데이터의 저장과 삭제가 매우 빠름
해시 테이블의 장점과 단점
- 장점
- 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있음
- 배열의 인덱스(index)를 사용해서 검색, 삽입, 삭제가 빠름 (빠른 검색, 저장 속도)
- 중복 확인이 쉬우며, 중복을 제거하는데 유용함 (집합에서는 중복을 허용하지 X)
- 키(key) 와 해시값(Hash)이 연관성이 없어 보안에도 많이 사용
- 단점
- 추가적인 저장 공간이 필요
- 공간 복잡도가 커짐
- 순서가 있는 배열에는 어울리지 않음
- 해시 함수 의존도가 높아짐
- 해시 충돌이 발생할 수 있기 때문에 충돌을 해결하는 별도의 방법이 필요
- 해시 충돌이 발생하는 경우 평균 시간 복잡도가 최악의 경우 O(N)
따라서, 해시 테이블은 검색, 저장, 삭제를 자주 하거나, 중복 확인 및 개수를 셀 때 사용하면 편하며, 관계를 표현할 때도 유용함
해시 테이블의 기본 연산은 삽입, 삭제 및 탐색!
충돌이 발생하지 않는다고 가정한다면, 시간 복잡도는 다음과 같음
- 탐색: 인덱스로 값 탐색 O(1)
- 삽입: 해시 함수를 통해 인덱스가 정해짐 O(1)
- 삭제: 인덱스와 인덱스 내부 값 지워주기 O(1) (배열과 달리 지워졌다고 순서를 다시 정리할 필요 X)
따라서 FullScan과 같은 선형탐색보다(=O(N)) 훨씬 빠르게 자료값을 찾는다고 볼 수 있음!
딕셔너리(Dictionary)와 리스트(List)
| operation | Dictionary | List |
|---|---|---|
| Get Item | O(1) | O(1) |
| Insert Item | O(1) | O(1) |
| Update Item | O(1) | O(1) ~ O(N) |
| Delete Item | O(1) | O(1) |
| Search Item | O(1) | O(1) ~ O(N) |
딕셔너리의 시간 복잡도는 대부분 O(1)이며, 원소를 넣거나 삭제, 찾는 일이 많을 때에는 딕셔너리를 사용하는 것이 좋음! (* 파이썬 3.7 이상부터 딕셔너리는 원소의 들어온 순서 보장, 3.7 미만은 유의)
딕셔너리(Dictionary)
- 딕셔너리 생성 (Init)
# 1. 빈 딕셔너리 생성
empty_dict1 = {}
empty_dict2 = dict()
# 2. 초기값이 있는 딕셔너리 생성
# key-value 쌍으로 데이터를 저장
person = {
'name': '나나',
'weight': 44,
'height': 157,
}
# {'height': 157, 'name': '나나', 'weight': 44}
# 3. 중첩된 딕셔너리 생성
# 딕셔너리를 값으로 가지는 중첩된 딕셔너리도 만들 수 있음
animals = {
'Dog': {
'name': '보리',
'age': 6
},
'Cat': {
'name': '나비',
'weight': 4
}
}
# { 'Dog': { 'name': '보리', 'age': 6},
# 'Cat': {'name': '나비','weight': 4 }}
# 4. `fromkeys()` 메소드 사용
# 동일한 기본값으로 초기화된 딕셔너리 생성
keys = ['a', 'b', 'c']
default_dict = dict.fromkeys(keys, 0)
print(default_dict) # {'a': 0, 'b': 0, 'c': 0}
# 값 생략 시 기본값은 `None`
none_dict = dict.fromkeys(keys)
print(none_dict) # {'a': None, 'b': None, 'c': None}- 딕셔너리 조회 (Get)
# 1. 대괄호 `[]` 사용
# 해당 키가 존재하지 않으면 `KeyError`가 발생
person = {'가나다라': 300, '마바사': 180}
print(person['가나다라']) # 300
# 2. `get()` 메소드 사용
# 키가 없으면 기본값을 반환하도록 설정할 수 있음
print(person.get('보리', 0)) # 0- 딕셔너리 값 설정 및 수정 (Set)
# 1. 값 추가
# 딕셔너리에 새로운 키-값 쌍을 추가할 수 있음
scores = {'루이': 300, '미나': 180}
scores['재하'] = 100
# 2. 값 수정
# 기존 값 수정은 대괄호를 사용해 간단히 할 수 있음
scores['루이'] = 500 # 특정 값으로 변경
scores['루이'] += 300 # 기존 값에 더하기- 딕셔너리 값 삭제 (Delete)
# 1. `del` 키워드 사용
# 키가 존재하지 않으면 `KeyError`가 발생
del scores['루이']
# 2. `pop()` 메소드 사용
# 키가 없으면 기본값을 반환하도록 설정할 수 있음
value = scores.pop('수진', 0) # 0
print(value)- 딕셔너리 순회 (Iterate)
# 1. 키만 순회
for key in scores:
print(key)
# 2. 키와 값 동시에 순회
for key, value in scores.items():
print(f"{key}: {value}")- 유용한 메소드
# 1. 키 존재 여부 확인
# `in` 키워드를 사용하면 특정 키의 존재 여부를 확인할 수 있음
print('미나' in scores) # True
print('미나' not in scores) # False
# 2. 키, 값 추출
# `keys()`: 키 목록 반환
# `values()`: 값 목록 반환
# `items()`: 키-값 쌍 반환
print(scores.keys()) # dict_keys(['미나'])
print(scores.values()) # dict_values([180])
print(scores.items()) # dict_items([('미나', 180)])- 딕셔너리 함수 활용
# 특정 키 존재 여부 확인 예제
students = {'지민': 17, '태희': 15, '윤아': 18}
if '지민' in students:
print('지민 is in students')
else:
print('지민 is not in students')
# 키, 값 순회 예제
for student, age in students.items():
print(f"{student}: {age}")
# 값 삭제 및 초기화 예제
del students['지민']
print(students) # {'태희': 15, '윤아': 18}
students.clear()
print(students) # {}활용 방안
-
리스트 사용이 불가할 경우
- 리스트는 숫자 인덱스를 이용하여 원소에 접근
- list[1]은 가능
- list['a']는 불가능
- 인덱스 값을 숫자가 아닌 다른 값 '문자열, 튜플'을 사용할 시, 딕셔너리를 사용하면 좋음
- 리스트는 숫자 인덱스를 이용하여 원소에 접근
-
빠른 접근 및 탐색이 필요할 경우
- 딕셔너리 함수의 시간 복잡도는 대부분 O(1)로 빠른 자료구조
-
집계가 필요할 경우
- 해시와, collections 모듈의 Counter 클래스를 사용하여 원소의 개수를 세는 문제와 접목시킬 경우 빠른 시간 내 문제 풀이가 가능
참고
(1) Hash(해시)
(2) 해시(Hash)란 무엇인가(feat. Dictionary 자료구조)
(3) 파이썬으로 해시 테이블 구현하기
