
이번 포스팅에서는 Selenium라이브러리를 활용하여 다양한 컨텐츠를 스크래핑 해보겠습니다.
Selenium 기초
먼저 Selenium 및 웹 드라이버를 설치해야합니다.
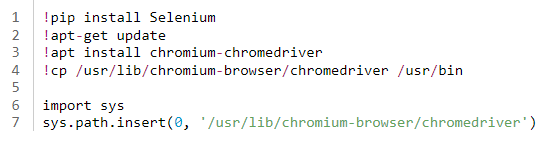
다음으로 웹 드라이버를 설정하고 웹 드라이버 객체를 생성합니다.

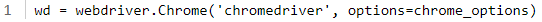
네이버 웹툰 스크래핑
기본설정이 끝났으면 Selenium을 활용하여 네이버 웹툰 사이트에서 정보를 스크래핑 해봅시다.
네이버 만화 페이지 홈에서 장르별 추천웹툰의 html구성을 보면 다음과 같습니다.
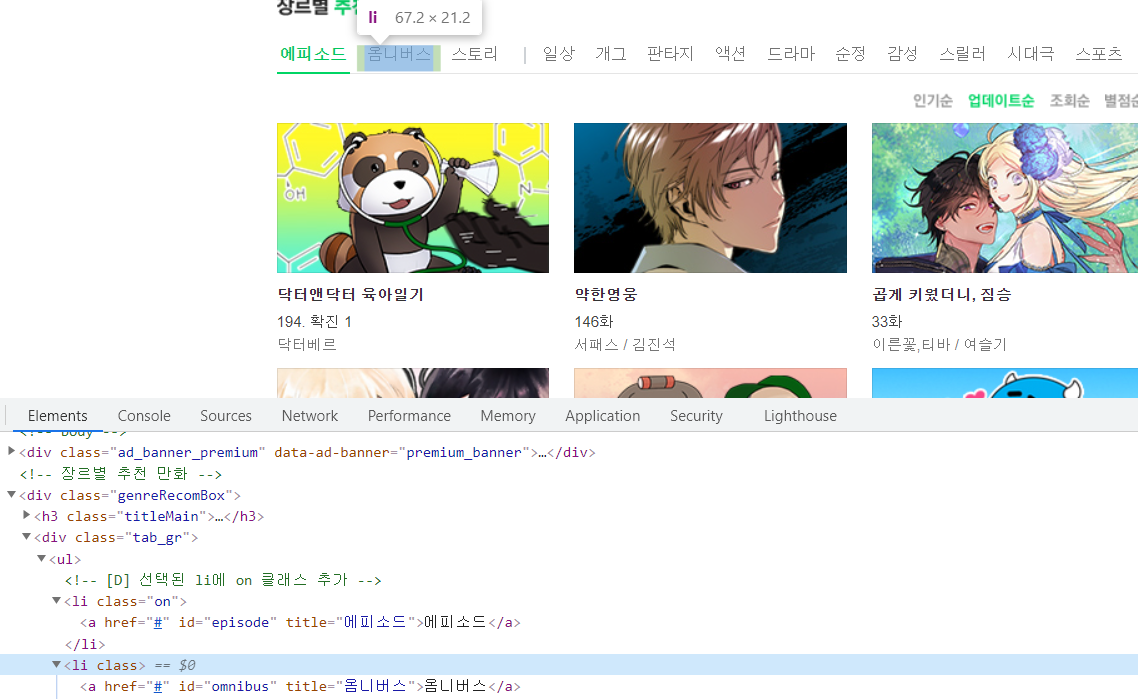
카테고리별로 구성된 웹툰이 다르고 url이 바뀌지 않기 때문에 각각을 클릭하면서 바뀌는 정보를 스크래핑해와야 합니다. BeautifulSoup과는 다르게 Selenium은 웹 드라이버가 클릭과 같은 동작들을 수행할 수 있습니다.
우선 각 카테고리 제목을 스크래핑 해봅시다.

카테고리 제목은 div.tab_gr > li > a에 들어있습니다.
클래스 이름으로 div내용을 가져오고 그 안에서 태그 이름을 통해 카테고리 제목을 추출합니다.
각 카테고리를 클릭하면서 카테고리별 작품명과 작가명을 추출해봅시다.
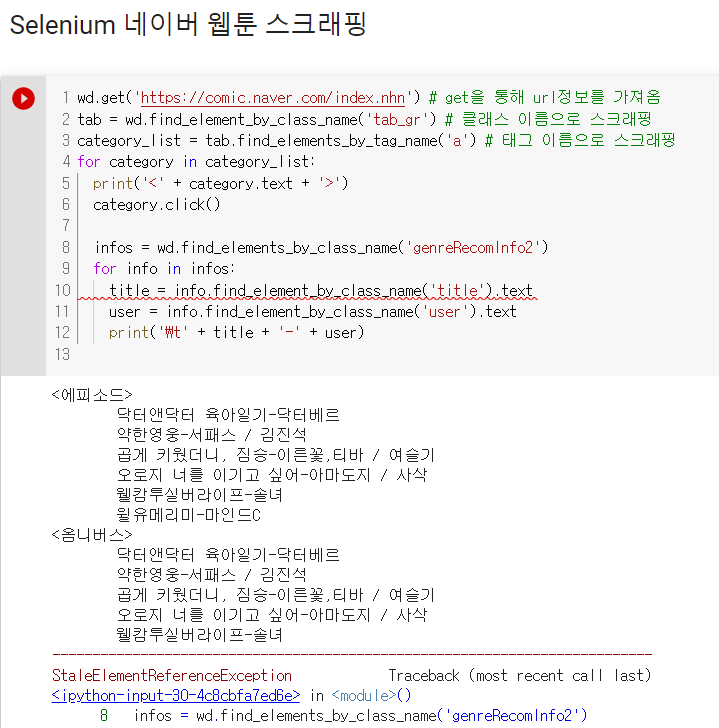
결과값이 잘 나오다가 중간에 오류가 발생했습니다.
이는 링크를 클릭한 결과를 전달받기 전에 정보를 추출하려고해서 발생한 오류입니다. 링크를 클릭하고 코드를 잠깐 멈춘 후 정보를 추출해봅시다.
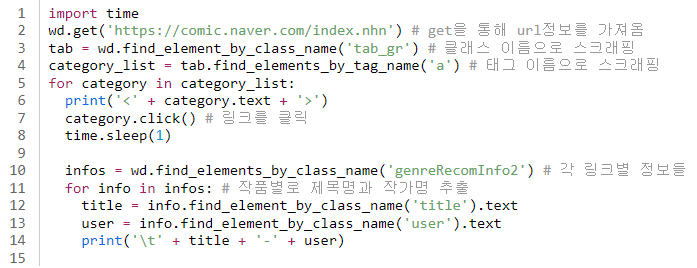

코드는 오류 없이 돌아가지만 출력 결과를 보니 '컷툰'때문에 원하는 대로 출력되지 않았습니다.
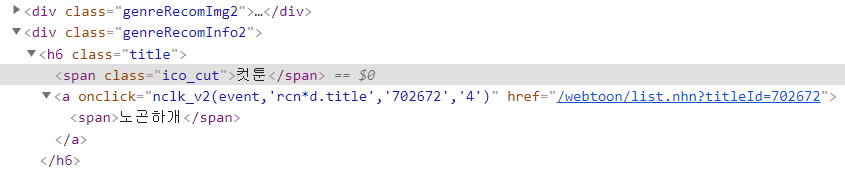
html구성을 보니 컷툰은 다른 작품과 다르게 h6.title 아래에 span태그가 하나 더 있어서 문제가 발생했습니다. 코드를 수정해줍시다.

정상적으로 출력됩니다.
