JPA와 ORM 개요
JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준으로, 자바 객체와 관계형 데이터베이스 간의 매핑을 처리하는 인터페이스 모음입니다. ORM(Object-Relational Mapping)은 객체 지향 패러다임과 관계형 데이터베이스 패러다임 간의 불일치를 해소하는 기술입니다.
JPA를 사용하면 개발자는 SQL 쿼리를 직접 작성하는 대신 자바 객체를 통해 데이터베이스를 조작할 수 있으며, 이를 통해 생산성을 높이고 유지보수성을 개선할 수 있습니다.
JPA 네이밍 전략
JPA에서는 자바 객체의 이름을 데이터베이스의 테이블과 컬럼 이름으로 변환하는 과정에서 두 가지 네이밍 전략을 사용합니다.
암시적 네이밍 전략(Implicit Naming Strategy)
암시적 네이밍 전략은 명시적으로 이름을 지정하지 않은 경우 적용되는 전략입니다.
- JPA 기본값:
ImplicitNamingStrategyJpaCompliantImpl- 이 전략은 엔티티에 설정된 이름을 그대로 사용합니다.
- 일반적으로 카멜 케이스(camelCase) 형태로 작성된 변수명을 그대로 사용합니다.
- Spring에서 제공하는 전략:
SpringImplicitNamingStrategyImplicitNamingStrategyJpaCompliantImpl을 상속받아 구현되어 있습니다.- 조인 테이블 이름을 결정하는 로직이 추가되어 있습니다.
물리적 네이밍 전략(Physical Naming Strategy)
물리적 네이밍 전략은 암시적/명시적 네이밍 전략 이후에 적용되는 최종 변환 규칙입니다. 즉, 암시적/명시적으로 이름을 지정해도 마지막에는 물리적 네이밍 전략이 적용됩니다.
SpringPhysicalNamingStrategy(Spring Boot 기본값)- 카멜 케이스를 스네이크 케이스(snake_case)로 변환합니다.
- 예:
userId→user_id
PhysicalNamingStrategyStandardImpl- 엔티티 변수명을 그대로 사용합니다.
- 예:
userId→userId
CamelCaseToUnderscoresNamingStrategy- 카멜 케이스를 소문자 스네이크 케이스로 변환합니다.
- 예:
userId→user_id
엔티티 매핑 기본 어노테이션
@Entity
@Entity 어노테이션은 해당 클래스가 JPA 엔티티임을 나타냅니다.
Copy@Entity
public class User {
// 클래스 내용
}
- 기본적으로 JPA의 엔티티 이름은 클래스 이름을 따라갑니다.
- 엔티티 클래스는 기본 생성자(public 또는 protected)가 필수입니다.
- final 클래스, enum, interface, inner 클래스는 엔티티로 사용할 수 없습니다.
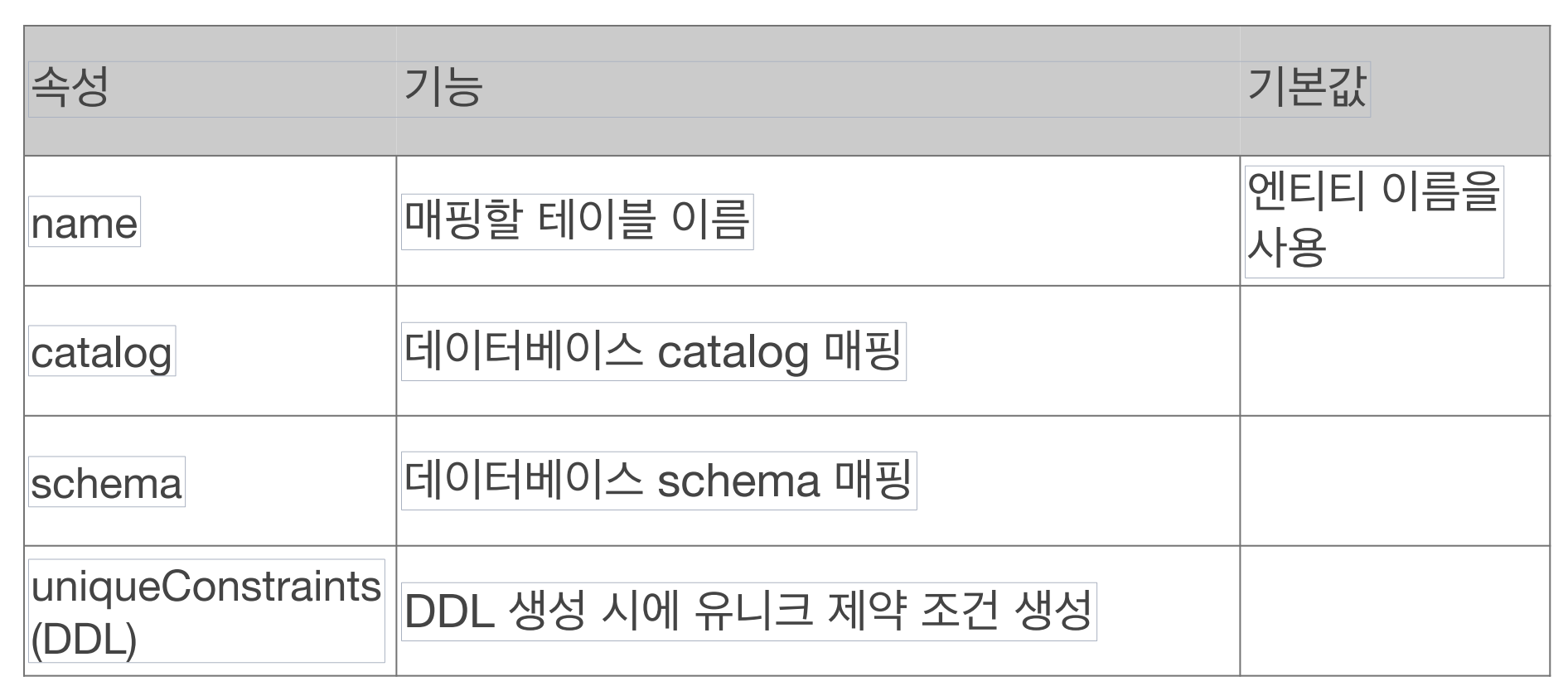
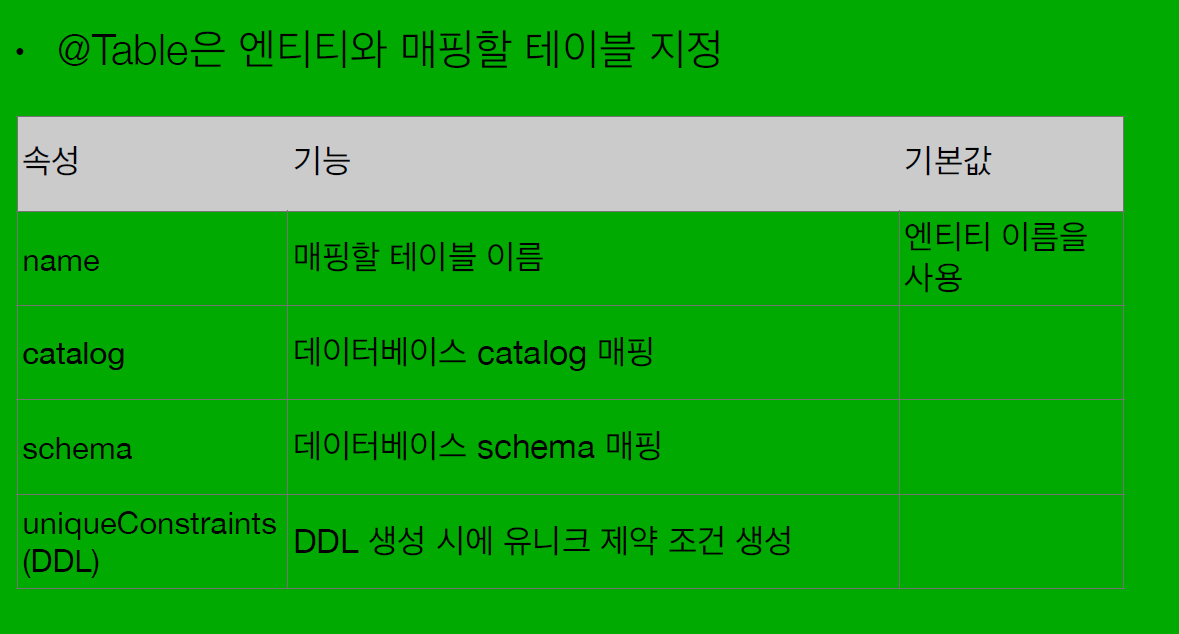
@Table
@Table 어노테이션은 엔티티와 매핑할 테이블을 지정합니다.
Copy@Entity
@Table(name = "USERS")
public class User {
// 클래스 내용
}
주요 속성:
name: 매핑할 테이블 이름catalog: 데이터베이스 catalogschema: 데이터베이스 schemauniqueConstraints: DDL 생성 시 유니크 제약 조건 생성
@Column
@Column 어노테이션은 필드와 테이블의 컬럼을 매핑합니다.
Copy@Entity
public class User {
@Id
private Long id;
@Column(name = "username", length = 100, nullable = false)
private String name;
}
주요 속성:
name: 매핑할 컬럼 이름insertable,updatable: 등록, 변경 가능 여부nullable: null 값 허용 여부unique: 유니크 제약 조건columnDefinition: 컬럼 정의를 직접 지정length: 문자 길이 제약조건precision,scale: 숫자 자릿수 제약조건
기본키 매핑 전략
JPA에서는 기본키를 매핑하기 위해 @Id와 @GeneratedValue 어노테이션을 사용합니다.
Copy@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 다른 필드들...
}
@GeneratedValue의 주요 전략:
-
GenerationType.IDENTITY
- 기본키 생성을 데이터베이스에 위임
- MySQL의 AUTO_INCREMENT와 같은 기능
- JPA는 INSERT SQL 실행 후 기본키 값을 얻어옴
-
GenerationType.SEQUENCE
- 데이터베이스 시퀀스 객체를 사용
- 주로 Oracle에서 사용
@SequenceGenerator와 함께 사용
Copy@Entity @SequenceGenerator( name = "USER_SEQ_GENERATOR", sequenceName = "USER_SEQ", initialValue = 1, allocationSize = 1) public class User { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "USER_SEQ_GENERATOR") private Long id; } -
GenerationType.TABLE
- 키 생성용 테이블을 사용
- 모든 데이터베이스에서 사용 가능
@TableGenerator와 함께 사용
-
GenerationType.AUTO
- 데이터베이스에 따라 자동으로 전략 선택
데이터 타입 매핑
@Enumerated
Enum 타입 매핑에 사용됩니다.
Copypublic enum Role {
ADMIN, USER
}
@Entity
public class Member {
@Enumerated(EnumType.STRING)
private Role role;
}
EnumType.ORDINAL: enum 순서를 저장 (권장하지 않음)EnumType.STRING: enum 이름을 저장 (권장)
@Temporal
날짜 타입(Date, Calendar) 매핑에 사용됩니다. Java 8 이상의 LocalDate, LocalDateTime을 사용할 경우 생략 가능합니다.
Copy@Entity
public class Member {
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
}
TemporalType.DATE: 날짜만 저장TemporalType.TIME: 시간만 저장TemporalType.TIMESTAMP: 날짜와 시간 저장
@Transient
데이터베이스에 저장하지 않을 필드에 사용합니다.
Copy@Entity
public class Member {
@Transient
private String tmpValue;
}
명명 규칙 커스터마이징
프로젝트 요구사항에 맞게 네이밍 전략을 커스터마이징할 수 있습니다. 예를 들어, 모든 테이블명과 컬럼명을 대문자 스네이크 케이스로 변환하고 싶다면 다음과 같이 구현할 수 있습니다.
Copypublic class UpperCaseNamingStrategy implements PhysicalNamingStrategy {
@Override
public Identifier toPhysicalCatalogName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return this.apply(name, jdbcEnvironment);
}
@Override
public Identifier toPhysicalSchemaName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return this.apply(name, jdbcEnvironment);
}
@Override
public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return this.apply(name, jdbcEnvironment);
}
@Override
public Identifier toPhysicalSequenceName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return this.apply(name, jdbcEnvironment);
}
@Override
public Identifier toPhysicalColumnName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return this.apply(name, jdbcEnvironment);
}
private Identifier apply(Identifier name, JdbcEnvironment jdbcEnvironment) {
if (name == null) {
return null;
}
StringBuilder builder = new StringBuilder(name.getText().replace('.', '_'));
for(int i = 1; i < builder.length() - 1; ++i) {
if (this.isUnderscoreRequired(builder.charAt(i - 1), builder.charAt(i), builder.charAt(i + 1))) {
builder.insert(i++, '_');
}
}
return this.getIdentifier(builder.toString(), name.isQuoted(), jdbcEnvironment);
}
protected Identifier getIdentifier(String name, boolean quoted, JdbcEnvironment jdbcEnvironment) {
if (this.isCaseInsensitive(jdbcEnvironment)) {
name = name.toUpperCase(Locale.ROOT);
}
return new Identifier(name, quoted);
}
protected boolean isCaseInsensitive(JdbcEnvironment jdbcEnvironment) {
return true;
}
private boolean isUnderscoreRequired(char before, char current, char after) {
return Character.isLowerCase(before) && Character.isUpperCase(current) && Character.isLowerCase(after);
}
}
application.yml 설정:
Copyspring:
jpa:
hibernate:
naming:
physical-strategy: com.example.config.UpperCaseNamingStrategy
결론 및 권장사항
JPA 네이밍 전략을 선택할 때 고려해야 할 사항들:
- 일관성 유지: 모든 테이블과 컬럼에 동일한 네이밍 규칙을 적용하세요.
- 기존 DB와의 통합: 기존 데이터베이스와 통합해야 하는 경우, 물리적 네이밍 전략을 커스터마이징하는 것이 좋습니다.
- 네이밍 규약 선택:
- 카멜 케이스(camelCase): Java 코드와 일관성 유지 (변수명 스타일)
- 스네이크 케이스(snake_case): 데이터베이스 관례와 일치
- 대문자 스네이크 케이스(UPPER_SNAKE_CASE): 일부 레거시 데이터베이스 시스템에서 선호
- 명시적 이름 지정 최소화: 물리적 네이밍 전략으로 일관성을 유지하고,
@Table,@Column으로 이름을 명시적으로 지정하는 경우를 최소화하세요. - Enum 타입:
EnumType.STRING을 사용하세요.ORDINAL은 enum 순서 변경 시 데이터 불일치 문제가 발생할 수 있습니다. - 테스트: 실제 프로덕션 환경에서 사용하기 전에 테스트 환경에서 네이밍 전략이 예상대로 동작하는지 확인하세요.
JPA의 네이밍 전략을 적절히 활용하면 자바 코드와 데이터베이스 간의 일관성을 유지하고, 개발자의 생산성을 향상시킬 수 있습니다. 프로젝트의 요구사항과 기존 데이터베이스 환경에 맞는 전략을 선택하는 것이 중요합니다.
참고 자료
