1. 단어 수준으로 토큰화
# 토큰화
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("en_core_web_sm")
tokenizer = Tokenizer(nlp.vocab)# 문장 리스트 토큰화
sent1 = "I am a student."
sent2 = "J is the alphabet that follows i."
sent3 = "Is she a student trying to become a data scientist?"
sent_lst = [sent1, sent2, sent3]
total_tokens = []
for i, sent in enumerate(tokenizer.pipe(sent_lst)):
sent_token = [token.text for token in sent]
total_tokens.extend(sent_token)
print(f"sent {i} : {sent_token}")
token_set = set(total_tokens)
print(f"""
total_tokens : {token_set}
#_of_total_tokens : {len(token_set)}
""")sent 0 : ['I', 'am', 'a', 'student.']
sent 1 : ['J', 'is', 'the', 'alphabet', 'that', 'follows', 'i.']
sent 2 : ['Is', 'she', 'a', 'student', 'trying', 'to', 'become', 'a', 'data', 'scientist?']total_tokens : {'student', 'scientist?', 'alphabet', 'that', 'to', 'she', 'student.', 'Is', 'the', 'follows', 'data', 'J', 'is', 'a', 'become', 'I', 'trying', 'i.', 'am'}
#_of_total_tokens : 19
# 단어 인덱스화
def word2idx(sent, total):
sent_token = sent.split()
return [1 if word in sent_token else 0 for word in total]
sent1_idx = word2idx(sent1, token_set)
sent2_idx = word2idx(sent2, token_set)
sent3_idx = word2idx(sent3, token_set)
# 인덱스화된 단어 데이터 프레임
import pandas as pd
dtm = pd.DataFrame([sent1_idx, sent2_idx, sent3_idx], columns=set(total_tokens))
dtm2. 같은 단어들을 합침(대소문자 등)
import re
def lower_and_regex(sentence):
"""
모든 대문자를 소문자로 변경 후
정규식을 이용하여 알파벳 소문자 이외의 구두점 삭제
"""
sentence = sentence.lower()
sentence = re.sub(r"[^a-z ]", "", sentence)
return sentence
prep_sent_lst = [lower_and_regex(sent) for sent in sent_lst]
total_tokens_prep = []
for i, prep_sent in enumerate(tokenizer.pipe(prep_sent_lst)):
sent_token_prep = [token.text for token in prep_sent]
total_tokens_prep.extend(sent_token_prep)
print(f"sent {i} : {sent_token_prep}")
token_set_prep = set(total_tokens_prep)
print(f"""
total_tokens : {token_set_prep}
num_of_total_tokens : {len(token_set_prep)}
""")sent 0 : ['i', 'am', 'a', 'student']
sent 1 : ['j', 'is', 'the', 'alphabet', 'that', 'follows', 'i']
sent 2 : ['is', 'she', 'a', 'student', 'trying', 'to', 'become', 'a', 'data', 'scientist']total_tokens : {'become', 'student', 'is', 'follows', 'the', 'a', 'scientist', 'trying', 'i', 'am', 'alphabet', 'she', 'that', 'to', 'j', 'data'}
num_of_total_tokens : 16
# 또 다른 소문자화 방법(apply 사용)
df['column'] = df['column'].apply(lambda x: x.lower())# 인덱스화 및 데이터프레임
sent1_idx_prep = word2idx(lower_and_regex(sent1), token_set_prep)
sent2_idx_prep = word2idx(lower_and_regex(sent2), token_set_prep)
sent3_idx_prep = word2idx(lower_and_regex(sent3), token_set_prep)
dtm_re = pd.DataFrame([sent1_idx_prep, sent2_idx_prep, sent3_idx_prep], columns=set(total_tokens_prep))
dtm_re3. 정규표현식 (신중하게 사용해야함)
import re
# 정규식
# []: [] 사이 문자를 매치, ^: not
regex = r"[^a-zA-Z0-9 ]"
# 치환할 문자
subst = ""
def tokenize(text):
"""text 문자열을 의미있는 단어 단위로 list에 저장합니다.
Args:
text (str): 토큰화 할 문자열
Returns:
list: 토큰이 저장된 리스트
"""
# 정규식 적용
tokens = re.sub(regex, subst, text)
# 소문자로 치환
tokens = tokens.lower().split()
return tokens
df['tokens'] = df['column'].apply(tokenize)# 전체 단어의 개수, 순위 등의 정보를 담은 데이터프레임 리턴 함수
def word_count(docs):
""" 토큰화된 문서들을 입력받아 토큰을 카운트 하고 관련된 속성을 가진 데이터프레임을 리턴합니다.
Args:
docs (series or list): 토큰화된 문서가 들어있는 list
Returns:
list: Dataframe
"""
# 전체 코퍼스에서 단어 빈도 카운트
word_counts = Counter()
# 단어가 존재하는 문서의 빈도 카운트, 단어가 한 번 이상 존재하면 +1
word_in_docs = Counter()
# 전체 문서의 갯수
total_docs = len(docs)
for doc in docs:
word_counts.update(doc)
word_in_docs.update(set(doc))
temp = zip(word_counts.keys(), word_counts.values())
wc = pd.DataFrame(temp, columns = ['word', 'count'])
# 단어의 순위
# method='first': 같은 값의 경우 먼저나온 요소를 우선
wc['rank'] = wc['count'].rank(method='first', ascending=False)
total = wc['count'].sum()
# 코퍼스 내 단어의 비율
wc['percent'] = wc['count'].apply(lambda x: x / total)
wc = wc.sort_values(by='rank')
# 누적 비율
# cumsum() : cumulative sum
wc['cul_percent'] = wc['percent'].cumsum()
temp2 = zip(word_in_docs.keys(), word_in_docs.values())
ac = pd.DataFrame(temp2, columns=['word', 'word_in_docs'])
wc = ac.merge(wc, on='word')
# 전체 문서 중 존재하는 비율
wc['word_in_docs_percent'] = wc['word_in_docs'].apply(lambda x: x / total_docs)
return wc.sort_values(by='rank')
wc = word_count(df['tokens'])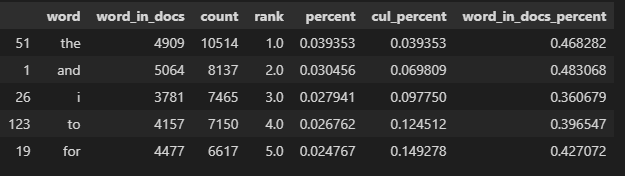
# 단어 개수 순위에 따른 단어 누적 분포 그래프
import seaborn as sns
sns.lineplot(x='rank', y='cul_percent', data=wc);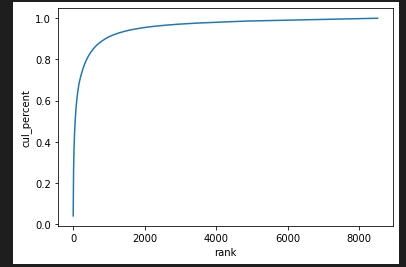
# 등장 비율 상위 20개 단어 시각화
import squarify
import matplotlib.pyplot as plt
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()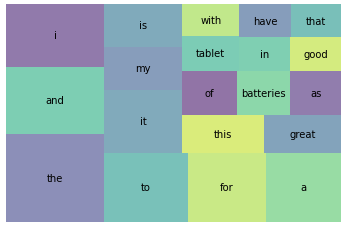
4. SpaCy를 이용하여 쉽게 처리하기
- Spacy는 문서 구성요소를 다양한 구조에 나누어 저장하지 않고 요소를 색인화하여 검색 정보를 간단히 저장하는 라이브러리로, 실제 배포단계에서 기존에 많이 사용된 NLTK 라이브러리보다 SpaCy가 더 빠르다.
# 필요한 모듈을 import
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("en_core_web_sm")
tokenizer = Tokenizer(nlp.vocab)
# 토큰화를 위한 파이프라인 구성
tokens = []
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens = [re.sub(r"[^a-z0-9]", "", token.text.lower()) for token in doc]
tokens.append(doc_tokens)
df['tokens'] = tokens
# word_count 함수를 사용하여 단어의 분포를 나타내어 봅시다.
wc = word_count(df['tokens'])5. 불용어(Stop words) 처리
- 학습에 도움되지 않는 단어 제거 (I, and of 등)
# Spacy 불용어 모음
print(nlp.Defaults.stop_words)- 불용어를 제외하고 토크나이징
#
tokens = []
# 토큰에서 불용어 제거, 소문자화 하여 업데이트
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens = []
# A doc is a sequence of Token(<class 'spacy.tokens.doc.Doc'>)
for token in doc:
# 토큰이 불용어와 구두점이 아니면 저장
if (token.is_stop == False) & (token.is_punct == False):
doc_tokens.append(token.text.lower())
tokens.append(doc_tokens)
df['tokens'] = tokens
df.tokens.head()- 불용어 커스터마이징
# 추가할 불용어
STOP_WORDS = nlp.Defaults.stop_words.union(
['batteries','I', 'amazon', 'i', 'Amazon', 'it', "it's", 'it.', 'the', 'this'])
# 불용어 제거
tokens = []
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens = []
for token in doc:
if token.text.lower() not in STOP_WORDS:
doc_tokens.append(token.text.lower())
tokens.append(doc_tokens)
df['tokens'] = tokens6. 통계적 Trimming
wc = word_count(df['tokens'])
# 단어 빈출정도가 1%이상인 단어만
wc = wc[wc['word_in_docs_percent'] >= 0.01]
sns.displot(wc['word_in_docs_percent'], kind='kde');7. 어간 추출(Stemming), 표제어 추출(Lemmatization)
- 어근(root) 추출 = 텍스트 데이터 정규화
- Spacy는 Lemmatization만 제공
# Stemming
from nltk.stem import PorterStemmer
ps = PorterStemmer()
words = ["wolf", "wolves"]
for word in words:
print(ps.stem(word))wolf
wolv
# Lemmatization
lem = "The social wolf. Wolves are complex."
nlp = spacy.load("en_core_web_sm")
doc = nlp(lem)
# Lemmatization에선 wolves도 wolf로 변형됨
for token in doc:
print(token.text, " ", token.lemma_)The the
social social
wolf wolf
. .
Wolves wolf
are be
complex complex
. .
- Lemmatization 함수화
def get_lemmas(text):
lemmas = []
doc = nlp(text)
for token in doc:
if ((token.is_stop == False) and (token.is_punct == False)) and (token.pos_ != 'PRON'):
lemmas.append(token.lemma_)
return lemmas
df['lemmas'] = df['reviews.text'].apply(get_lemmas)