Google Bootcamp에서 Gemma Sprint 프로젝트를 진행했다. Gemma 모델을 사용하여 자유 주제로 fine-tuning 하는 것이었고, 진행했던 프로젝트 과정을 공유하려고 한다.
Subject
Reverse Dictionary
This dictionary is not a dictionary that tells you the meaning when you enter a word, but a dictionary that tells you the words corresponding to the meaning when you enter sentence.
주제는 '거꾸로 사전'으로, 기존의 사전은 단어를 검색할 시 단어의 뜻을 알려주는 것이라면, '거꾸로 사전'은 문장으로 작성하면 그에 해당하는 단어를 알려주는 것이다.
이 사전은 일상 생활에서 갑자기 단어가 생각나지 않을 때, 혹은 글을 작성하는데 해당 문맥에 딱 맞는 단어가 생각나지 않을 때 활용할 수 있다.
전체 구조는 이와 같다.
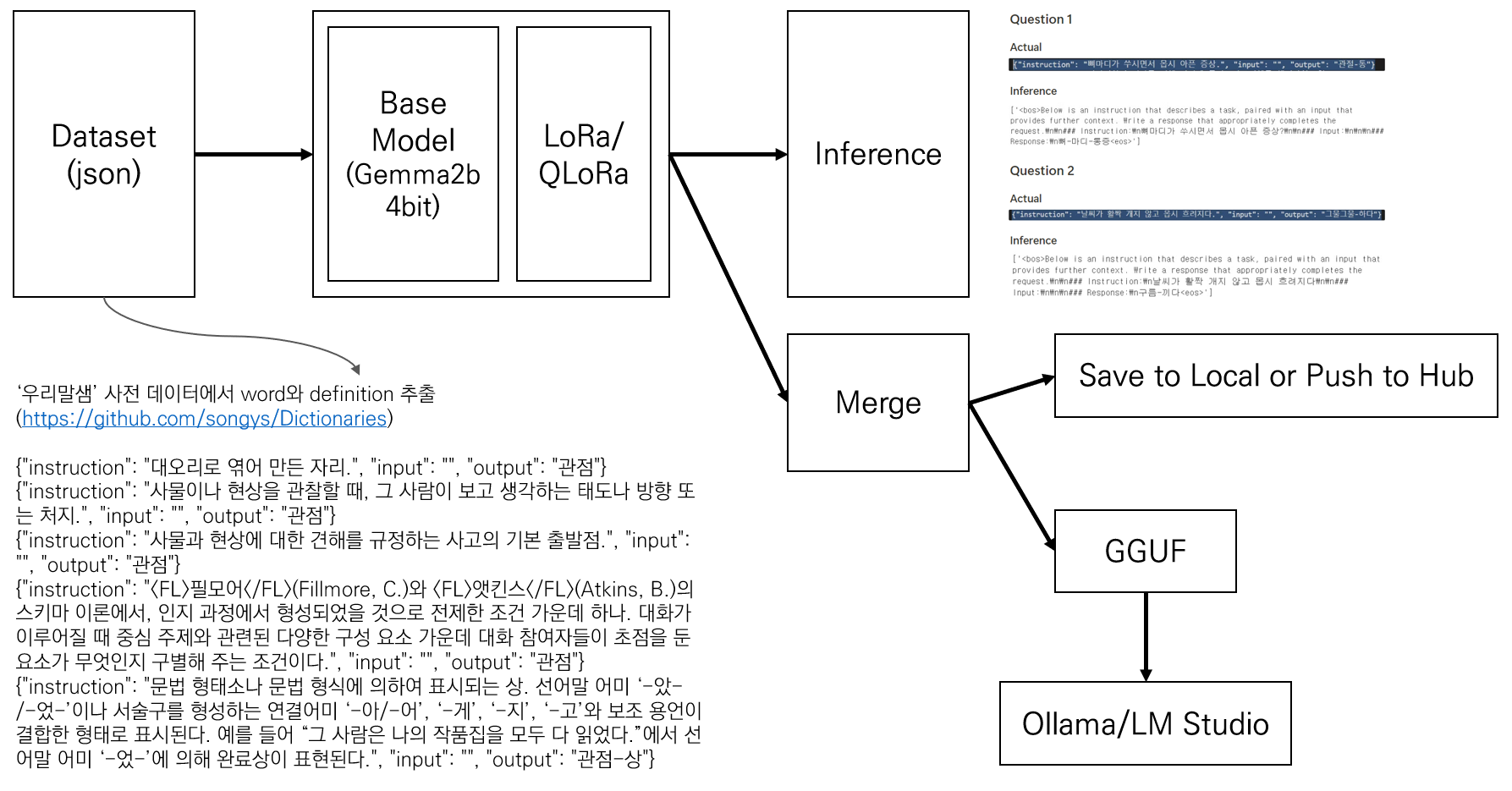
Collect Data
주제가 '사전'이라 사전에서 데이터를 가져오려고 했다. 하지만 대부분의 사전이 전체 데이터를 제공하지 않고 api로만 제공하여 한 번의 호출에 한 단어만 가져오는 형식이라 사용이 어려웠다.
그래서 위키백과나 AIhub 관련 데이터셋 기반으로 데이터셋을 직접 만들어야되나 고민하던 중 알게된 것이 우리말샘이었는데, 여기서 전체 데이터셋을 다운 받을 수 있도록 제공하고 있었다.
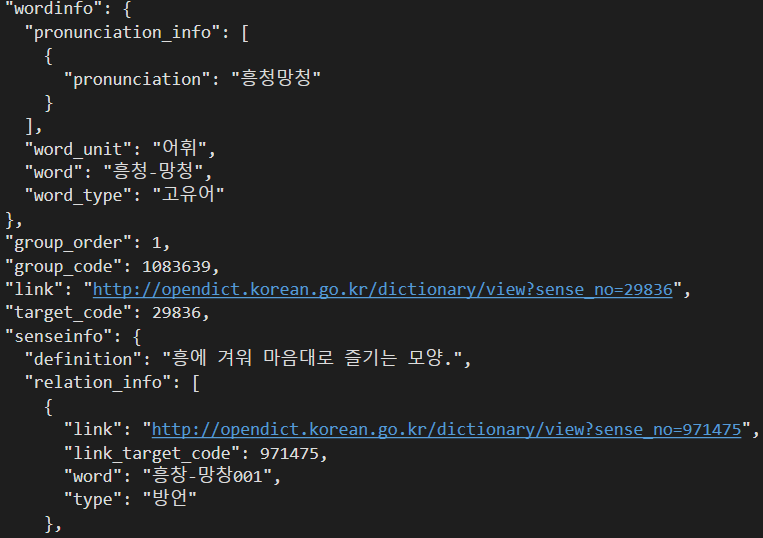
이 데이터셋은 기본적인 단어의 뜻, 단어의 타입, 유의어, 예문 등 많은 정보들로 구성되어있었다. 모델을 파인튜닝할 때 input으로 단어의 뜻을 넣고 output으로 단어를 넣어야 의도한대로 동작을 할 것 같아서 전체 데이터셋에서 word와 definition만 추출하여 fine tunning을 위해 적절한 구조로 데이터셋을 생성했다.
<프롬프트 구조>
alpaca_prompt =
"""
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}
"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass<데이터 로드>
# Load data
from datasets import load_dataset
dataset = load_dataset("json", data_files=json_file)
# Shuffle data
shuffled_dataset = dataset["train"].shuffle(seed=3407)
# Split train/test data (90:10)
train_test_split = shuffled_dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
test_dataset = train_test_split["test"]
dataset = train_dataset.map(formatting_prompts_func, batched = True,)총 단어의 개수는 1181401이고, 이후 모델을 학습하는데 전체 데이터의 90%인 1063260개의 단어를 사용하고 테스트를 위해 나머지 데이터를 사용하였다. 또한 이 데이터셋이 가나다순으로 되어있어 훈련/테스트셋을 분리할 때 무작위 셔플을 먼저 진행했다.
Model Fine-tuning
모델은 Gemma2-9b를 사용했다. Gemma 모델에는 2b, 9b, 27b 중 선택할 수 있었는데 이 숫자는 파라미터 수를 나타내어 모델의 크기와 관련되어 있다.
모델 Fine-tuning은 Unsloth를 사용하여 진행하였다.
Unsloth은 LLM의 파인튜닝을 최적화하기 위한 툴로 메모리 사용을 줄이고 학습 속도를 높여준다. Unsloth에서 Gemma2-9b과 Gemma2-27b 모델을 지원하는데 Gemma2-27b 모델을 사용하여 진행하였을 때는 GPU 메모리가 부족하여 로드가 되지 않아 Gemma2-9b 모델을 사용하였다. 또한 복잡한 주제는 아니어서 큰 모델은 적절하지 않아보였다.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gemma-2-9b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)먼저 Base model로 사용할 Gemma2-9b 모델을 지정해주고, 이때 4bit 양자화 옵션을 사용하여 메모리 사용량을 줄였다.
model = FastLanguageModel.get_peft_model(
model,
r = 32,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 64,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)다음은 LoRa adapter를 추가하는 코드인데, 이는 모델의 모든 파라미터 중 1~10%만 업데이트하여 메모리를 적게 사용하면서도 전체 fine-tuning의 표현력을 대략적으로 복구할 수 있도록 한다.
FastLanguageModel을 통해 특정 모듈에 대한 성능 향상 기법을 적용한 모델을 구성한다.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model, # 학습할 모델
tokenizer=tokenizer, # 토크나이저
train_dataset=dataset, # 학습 데이터셋
dataset_text_field="text", # 데이터셋에서 텍스트 필드의 이름
max_seq_length=max_seq_length, # 최대 시퀀스 길이
dataset_num_proc=2, # 데이터 처리에 사용할 프로세스 수
packing=False, # 짧은 시퀀스에 대한 학습 속도를 5배 빠르게 할 수 있음
args=TrainingArguments(
per_device_train_batch_size=2, # 각 디바이스당 훈련 배치 크기
gradient_accumulation_steps=4, # 그래디언트 누적 단계
warmup_steps=5, # 웜업 스텝 수
num_train_epochs=3, # 훈련 에폭 수
max_steps=100, # 최대 스텝 수
do_eval=True,
logging_steps=1, # logging 스텝 수
learning_rate=2e-4, # 학습률
fp16=not torch.cuda.is_bf16_supported(), # fp16 사용 여부, bf16이 지원되지 않는 경우에만 사용
bf16=torch.cuda.is_bf16_supported(), # bf16 사용 여부, bf16이 지원되는 경우에만 사용
optim="adamw_8bit", # 최적화 알고리즘
weight_decay=0.01, # 가중치 감소
lr_scheduler_type="cosine", # 학습률 스케줄러 유형
seed=123, # 랜덤 시드
output_dir="outputs", # 출력 디렉토리
),
)
trainer_stats = trainer.train()모델을 훈련하는 코드이다. 파라미터를 조정할 수 있는데 거의 기본으로 설정했고 학습 과정에서 evalutation을 함께 진행해보고자 eval_dataset=dataset 평가 단계를 추가해보았으나 메모리 부족으로 인해 실행이 되지 않아 제외하고 학습을 진행했다. 100 epochs까지 학습하는데 약 10분 정도 걸린 것 같다. 확실히 모델의 크기에 비해 빠른 것 같다.
Inference
추론은 앞서 데이터셋의 10%인 테스트셋을 이용하거나 간단한 단어 10개를 테스트해보는 작업을 진행했다.
테스트를 진행한 10개의 단어는 이와 같다.
비행기 - 동력으로 프로펠러를 돌리거나 연소 가스를 내뿜는 힘에 의하여 생기는 양력(揚力)을 이용하여 공중으로 떠서 날아다니는 항공기
가방 - 물건을 넣어 들거나 메고 다닐 수 있게 만든 용구
고양이 - 원래 아프리카의 리비아살쾡이를 길들인 것으로, 턱과 송곳니가 특히 발달해서 육식을 주로 한다. 발톱은 자유롭게 감추거나 드러낼 수 있으며, 눈은 어두운 곳에서도 잘 볼 수 있다. 애완동물로도 육종하여 여러 품종이 있다.
영화 - 일정한 의미를 갖고 움직이는 대상을 촬영하여 영사기로 영사막에 재현하는 종합 예술.
자동차 - 원동기를 장치하여 그 동력으로 바퀴를 굴려서 철길이나 가설된 선에 의하지 아니하고 땅 위를 움직이도록 만든 차. 승용차, 승합자동차, 화물 자동차, 특수 자동차 및 이륜자동차가 있다.
바나나 - 파초과의 상록 여러해살이풀. 높이는 3~10미터이며, 땅속의 알줄기에서 죽순 모양의 싹이 나와 긴 타원형의 녹색 잎이 8~10개가 뭉쳐나고, 긴 잎깍지가 서로 겹쳐 헛줄기를 이루면서 자란다. 초여름에 커다란 꽃줄기가 나와 엷은 누런색의 잔꽃이 이삭 모양으로 피고, 열매는 식용한다. 열대 지방이 원산지로 우리나라에서는 온실에서 재배한다.
컴퓨터 - 전자 회로를 이용한 고속의 자동 계산기. 숫자 계산, 자동 제어, 데이터 처리, 사무 관리, 언어나 영상 정보 처리 따위에 광범위하게 이용된다.
사과 - 사과나무의 열매.
책 - 종이를 여러 장 묶어 맨 물건.
학교 - 일정한 목적ㆍ교과 과정ㆍ설비ㆍ제도 및 법규에 의하여 계속적으로 학생에게 교육을 실시하는 기관.결과는 다음과 같이 나타난다.

10개의 단어 중 7개를 단어만 맞혔고, 2개의 단어는 해당 단어를 포함하는 비슷한 단어로 추론하였다.
이와 같이 반드시 사전적으로 설명을 적어야 output이 나오는 건 아니고 일상적으로 사용하는 단어를 가지고 문장을 만들어도 해당 설명과 비슷한 단어를 아래와 같이 알려준다.

하지만 문장을 입력하면 그와 가장 뜻이 비슷한 단어를 알려주는 것에서 아직 개선이 필요한 부분이 보인다. 설명에 명확하게 나와있을수록 정확한 답변을 내지만 간접적으로 설명할수록 정확도가 매우 떨어졌다.
자세한 코드나 파인튜닝된 모델을 사용해보고 싶다면,
