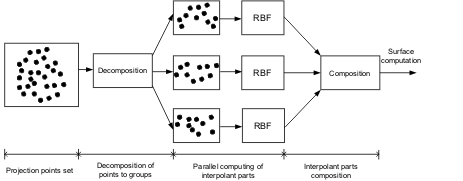
병렬 알고리즘 (parallel algorithm)
-
문제를 나누어 각 부분을 (대략)같은 시간 내에 처리 👉 결과 취합 방식
-
😇장점😇 : 분업으로 시간단축
-
👿단점👿 : 업무 분할과 취합에 시간 소요, 병렬 처리가 어렵거나 불가능한 알고리즘도 있음.
-
일을 독립적인 단위로 분할 + 취합 👉 효율성🔥
-
무엇이 더 효율적인 방식인지 잘 생각해야 함🌞🌈
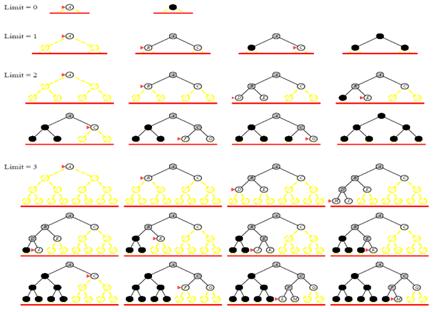
반복 심화 탐색 (iterative deepening)
-
깊이 우선 탐색의 변형
-
깊이가 제한된 깊이 우선 탐색을 반복해서 수행
-
k번째 반복 때 탐색할 수 있는 최대 깊이를 k로 제한해서 깊이 제한 탐색을 수행
-
😇장점😇 : 메모리 용량이 적게 듦(깊이 우선 탐색 장점) + 최악의 경우를 피하고 최단 거리 서치(너비 우선 탐색 장점)
-
👿단점👿 : 탐색 진행할수록 더 멀리 + 회를 반복할수록 여러 번 중복해서 탐색 👉 시간과 노력이 많이 듦
역 인덱스 (inverted index)
- 책 뒷면에 용어와 페이지를 실은 인덱스와 비슷한 역할을 하는 자료구조

-
목푯값들의 위치 알림 👉 탐색 목표가 데이터의 여러 곳에 등장할 때 유용
-
실행 시간과 메모리 사용 사이에 존재하는 하나를 얻으면 다른 하나를 잃는 상충관계
-
😇장점😇 : 인덱스가 추가되어 새로운 기준으로 훨씬 효과적으로 탐색가능 👉 탐색 실행 시간 단축
-
👿단점👿 : 전체 복사 후 새로운 인덱스를 추가 👉 메모리 사용량, 시간적 비용 증가
cf. 지출기입장 역인덱스
기록된 순번으로 오름차순 정렬된 지출기입장은 특정 장소 또는 금액을 찾는 데는 도움이 되지 않음.
지출한 곳을 기준으로 항목들 재정렬 또는 해당 기준으로 새로운 자료구조 추가 👉 "역인덱스"

유연하고 의연하게, 꾸준히