Problem
Solve
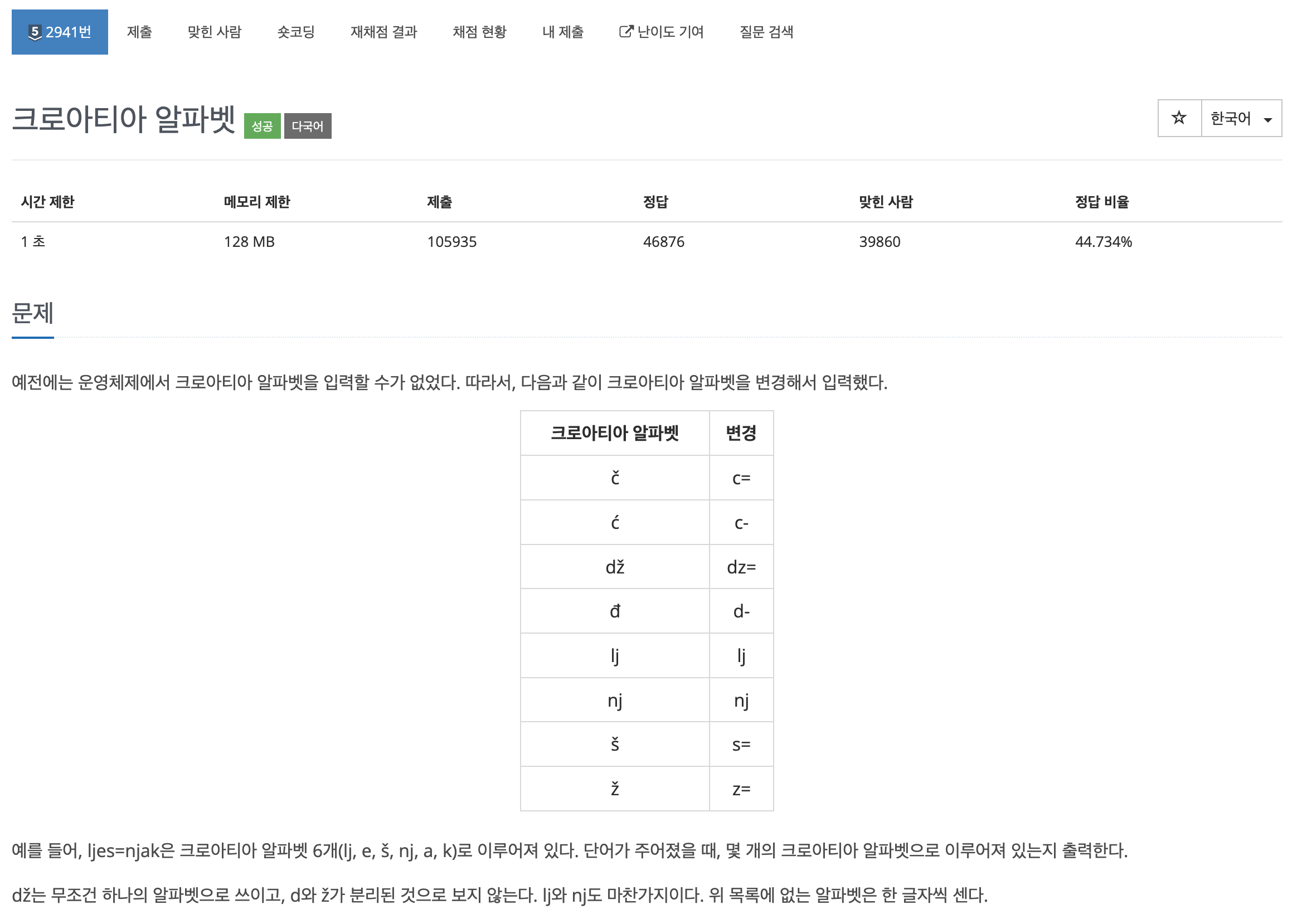
크로아티아 알파벳인 경우는 8가지가 있기 때문에 분기 처리를 통해 구현할 수 있다.
현재 단어가 'c'이고다음 단어가 '=' 또는 '-'인 경우현재 단어가 'd'이고다음 단어가 '-'인 경우또는다음 단어가 'z'이고 그 다음 단어가 '='인 경우현재 단어가 'l'이나 'n'이고다음 단어가 'j'인 경우현재 단어가 's'이나 'z'이고다음 단어가 '='인 경우
위의 경우를 분기 처리하여 하나의 알파벳으로 카운트하여 크로아티아 알파벳 개수를 구할 수 있다.
Code
public class 크로아티아알파벳 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String word = br.readLine();
int count = 0;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
//현재 단어가 'c'이고 다음 단어를 비교하기 위해 i 다음에 1개의 비교 index가 필요하다.
if (c == 'c' && i<word.length()-1) {
char nextC = word.charAt(i + 1);
if (nextC == '=' || nextC == '-')
i++;
}
//현재 단어가 'd'이고 다음 단어 비교를 위해 다음 index가 필요하다.
else if (c == 'd' && i < word.length() - 1) {
char nextC = word.charAt(i + 1);
if (nextC == '-')
i++;
//'dz'인 경우 다음 단어를 비교해야 하기 때문에 i 다음에 2개의 비교 index가 필요하다.
else if (nextC == 'z' && i < word.length() - 2) {
if (word.charAt(i + 2) == '=')
i+=2;
}
}
//현재 단어가 'l'이나 'n'이고 다음 단어 비교를 위해 다음 index가 필요하다.
else if ((c == 'l' || c == 'n') && i < word.length() - 1) {
if (word.charAt(i + 1) == 'j')
i++;
}
//현재 단어가 's'이거나 'z'이고 다음 단어 비교를 위해 다음 index가 필요하다.
else if ((c == 's' || c == 'z') && i < word.length() - 1) {
if (word.charAt(i + 1) == '=')
i++;
}
count++;
}
bw.write(String.valueOf(count));
bw.flush();
bw.close();
}
}Result
Reference

내 꿈은 좋은 개발자