
이번 학기에 운영체제 수업을 듣게 되었다. 어렵다고 악명이 높은 과목이지만, 다른 과목이랑 다를게 없을 것이라고 생각을 하고 차근차근 개념부터 다져보고자 한다.
Computer System
구성 요소
- CPU (Processor)
- Main Memory - 휘발성 O (Volatile)
- System bus - CPU, Memory, I/O의 통신을 담당
- I/O Modules - 2차 저장장치, terminal, 통신 장비
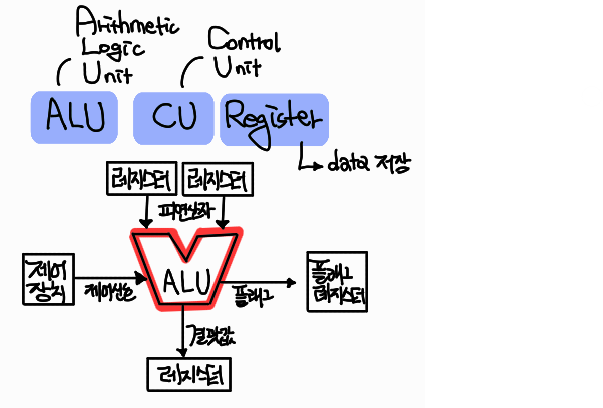
Processor Registers
크게 data I/O를 위한 레지스터, Control and Status 레지스터, User-visible 레지스터 3가지로 분류할 수 있다.
Registers for data I/O
-
MAR (Memory Address Register)
: 다음에 read (LOAD)하거나 write (STORE)할 주소를 구체적으로 정한다.Specifies the address for the next read(LOAD) or write(STORE)
-
MBR (Memory Buffer Register
1. 메모리에 적힐 예정인 data를 갖고 있을 때 : STORE
2. 메모리로부터 읽은 data를 저장할 때 : LOAD -
I/O address register, I/O buffer register
: CPU가 I/O를 하기 위해서는 memory를 거쳐야 하기 때문에 I/O 관련 레지스터가 필요하다.
Control and Status Register
: 프로세서가 프로세서의 동작을 제어하기 위해 사용되고, privileged os routine이 프로그램 실행을 제어하기 위해 사용한다.
- PC (Program Counter)
: fetch될 예정인 instruction의 주소를 갖고 있음 - IR (Instruction Register)
: 가장 최근에 fetch된 instruction을 갖고 있음 - PSW (Program Status Word)
- Condition Codes
- Operation의 결과로 processor hardware에 bit가 설정됨
- 주로
for,while,if와 같은 conditional operation에 사용된다. - 예시 : Positive, Negative, 0, Overflow ... 문제 발생시 빠르게 대처하기 위함
- Interrupt Enable / Disable
- Interrupt의 허용 여부
- Superviser / User mode
User-visible Register
프로그래머가 레지스터의 사용을 최적화함으로써 main memory에 대한 참조 횟수를 최소화한다. (main memory를 거쳐서 가게 되면 시간이 오래걸리기 때문)
-> Assembly 언어로 직접적으로 Register를 다루는 것이 가능하다
Instruction Execution
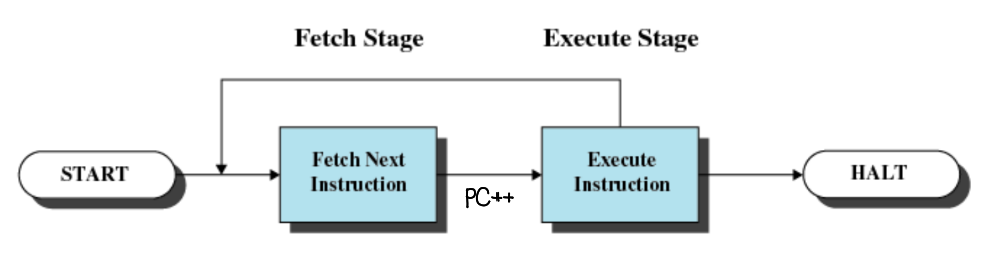
Instruction이 수행되는 과정을 다이어그램으로 그려보면 위의 그림과 같다.
Fetch와 Execute 2단계를 거치는데, 위에서 말했듯이 PC 레지스터가 다음에 fetch할 instruction을 갖고 있기 때문에 PC 레지스터에서 instruction을 가져온 다음 Execute를 하는데 더 이상 가져올 instruction이 없을 때까지 이 과정을 반복한다. 이 과정에서 PC값을 1씩 늘려주면서 PC가 다음 instruction을 가져오도록 하고 fetch된 instruction은 Instruction Register에 저장된다.
PC 값을 늘려주는 과정이 곧 process의 순차적 실행이 가능하게 하는 근본적인 이유이다.
이때, 순차적 실행의 경우 PC값을 늘려주면서 다음 instruction의 주소를 갖게 되지만, jump 같은 실행의 경우 다음 주소가 아닌 jump 했을 때의 주소값으로 대체하게 된다.
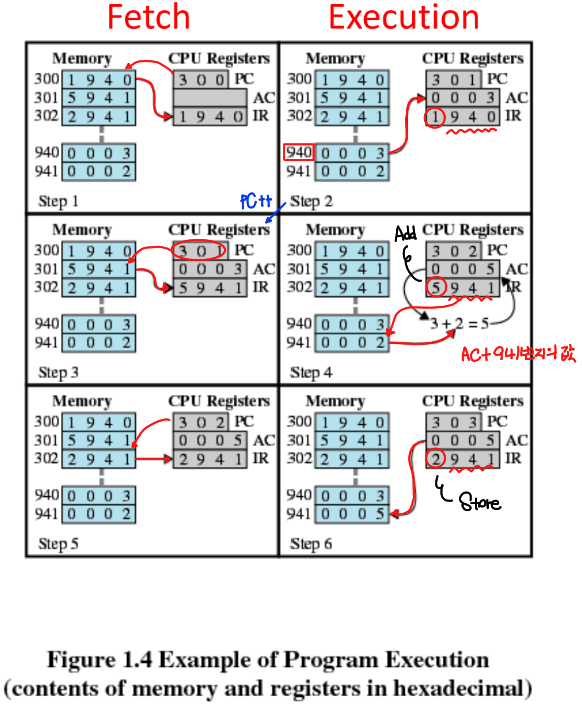
예를 들어, 위의 그림을 보면 좌상단에 PC 값으로 3 0 0이 주어져있는데, 이 경우 다음 instruction의 주소가 3 0 0번지라는 의미이므로 Memory의 300번지로 가서 1 9 4 0을 가져와서 IR에 저장을 하고 PC 값을 1만큼 늘려준다. 그 다음 앞에 있는 1 (LOAD) 을 두고 뒤에 있는 9 4 0을 통해 940번지로 가서 0 0 0 3을 가져온 뒤 AC에 저장을 한다.
그 다음 PC값이 3 0 1이 되었기 때문에 301번지로 가서 다시 이 과정을 반복한다. 이 때, IR에 저장되는 값들이 숫자 + 주소의 형태로 되어있는데 여기서 숫자에도 각각의 의미가 있다.
1인 경우 LOAD, 2인 경우 STORE, 5인 경우는 ADD의 의미이므로 뒤의 주소에 저장된 값을 불러와서 앞에 있는 숫자에 해당하는 연산을 진행하면 된다.
Interrupt & Interrupt handler
Interrupt는 운영체제가 아니더라도 컴퓨터구조나 시스템프로그래밍 과목을 들은 적이 있다면 들어보았을 것이다. 말 그대로 Interrupt (방해)를 한다는 의미인데, 조금 더 컴공스럽게 설명을 하면 "현재 CPU가 실행중인 정상 sequence를 중지하고 interrupt event를 먼저 처리한 뒤 다시 돌아와서 실행하는 mechanism"을 의미한다.
이 때 Event의 경우 2가지 case로 구분할 수 있다.
- Synchronous
: Syscall과 같이 자기 자신이 발생시킨 event이기 때문에 interrupt가 필요 없다- Asynchronous
: User가 프로그램 실행 도중 Mouse를 움직이는 행위와 같이 OS가 예상하지 못하는 Event이다. 예상을 못하기 때문에 Interrupt가 필요하다.
-
Interrupt
: Process의 정상적인 진행을 방해하는 과정
- 대부분의 I/O device들은 processor보다 느리기 때문에 processor가 device를 기다려야 한다.
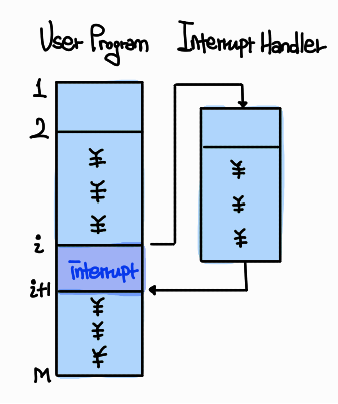
-
Interrupt handler
: 특정 I/O device를 지원하기 위한 프로그램으로 OS의 일부분이다.
이 때 interrupt의 경우 interrupt마다 번호를 부여해서 서로 다른 IR Queue에 push 함으로써 입력된 interrupt가 어떤 interrupt에 대한 것인지를 구분한다.
예를 들어, 위에서 언급한 Mouse를 움직여서 발생하는 interrupt의 경우를 interrupt_1로 지정해서 push를 한다면 Ctrl+C 같은 KeyboardInterrupt의 경우를 interrupt_2로 지정해서 push를 한다. 이렇게 되면 interrupt handler가 interrupt를 처리할 때 이 interrupt가 어떤 interrupt에 대한 내용인지를 빠르게 파악할 수 있다.
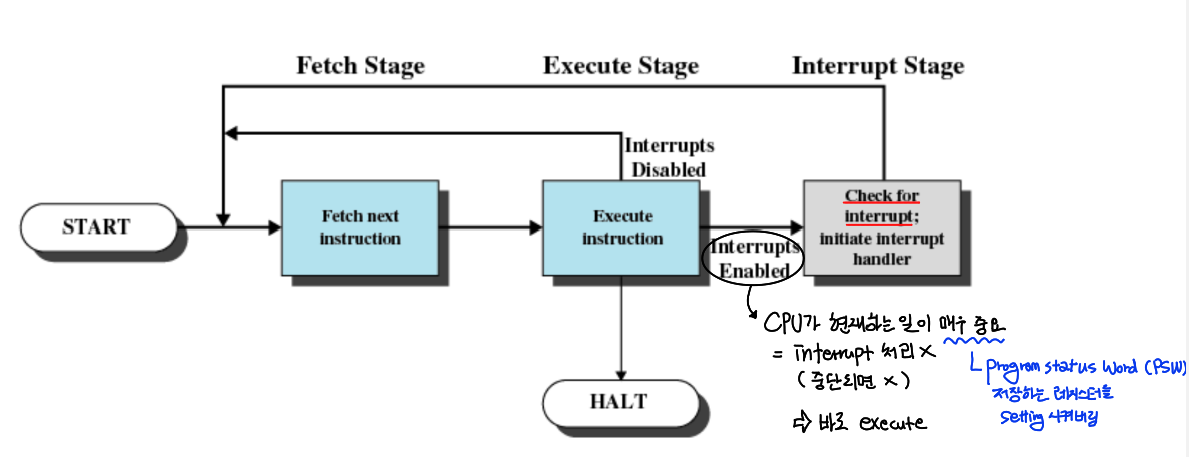
저 위에 있는 Instruction Cycle에 interrupt 과정을 추가하면 위의 그림과 같다.
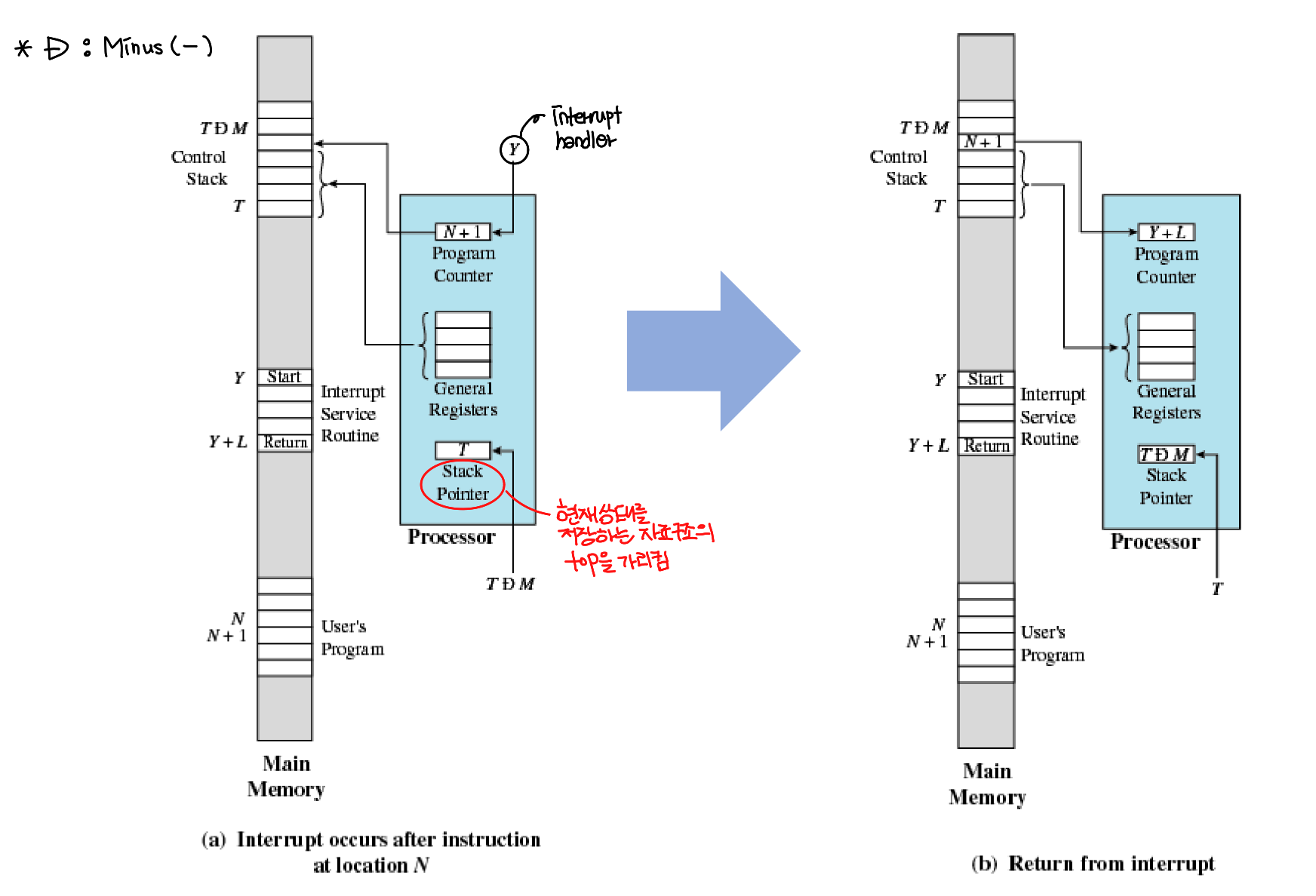
실제 interrupt 발생시 메모리와 프로세서간에 어떠한 변화가 있는지 확인을 해보면 프로세서에 있는 Stack pointer에 T-M이 들어오게 되면 Main memory로 가서 T-M 위치에 PC가 갖고 있던 다음 instruction을 올려놓게 되고 PC값이 증가함과 동시에 다음 instruction을 받는다. 이 과정에서 만약 아무 처리 없이 다음 instruction을 받게 된다면 register에 들어있는 원래 process가 interrupt에 의해 대체되기 때문에 interrupt 실행 후 다시 원래의 process를 실행하기 위해 Control Stack에 원래의 process를 push한 뒤 다음 instruction을 받는다. 그런데 이 그림에서는 다음 instruction이 interrupt handler y이므로 interrupt 처리를 하게 된다.
y가 들어오게 되면 원래 PC에 있던 N+1은 T-M 주소에 들어가게 되고 입력된 y에 의해 Interrupt Service Routine이 실행되게 되고 y+L이 return되어 PC로 들어가게 된다.
위의 그림이 조금 더 이해하기 쉬울 듯 싶다.
왼쪽 그림은 그림으로 표현을 한 것이고 오른쪽은 process의 실행 순서를 나타낸다.
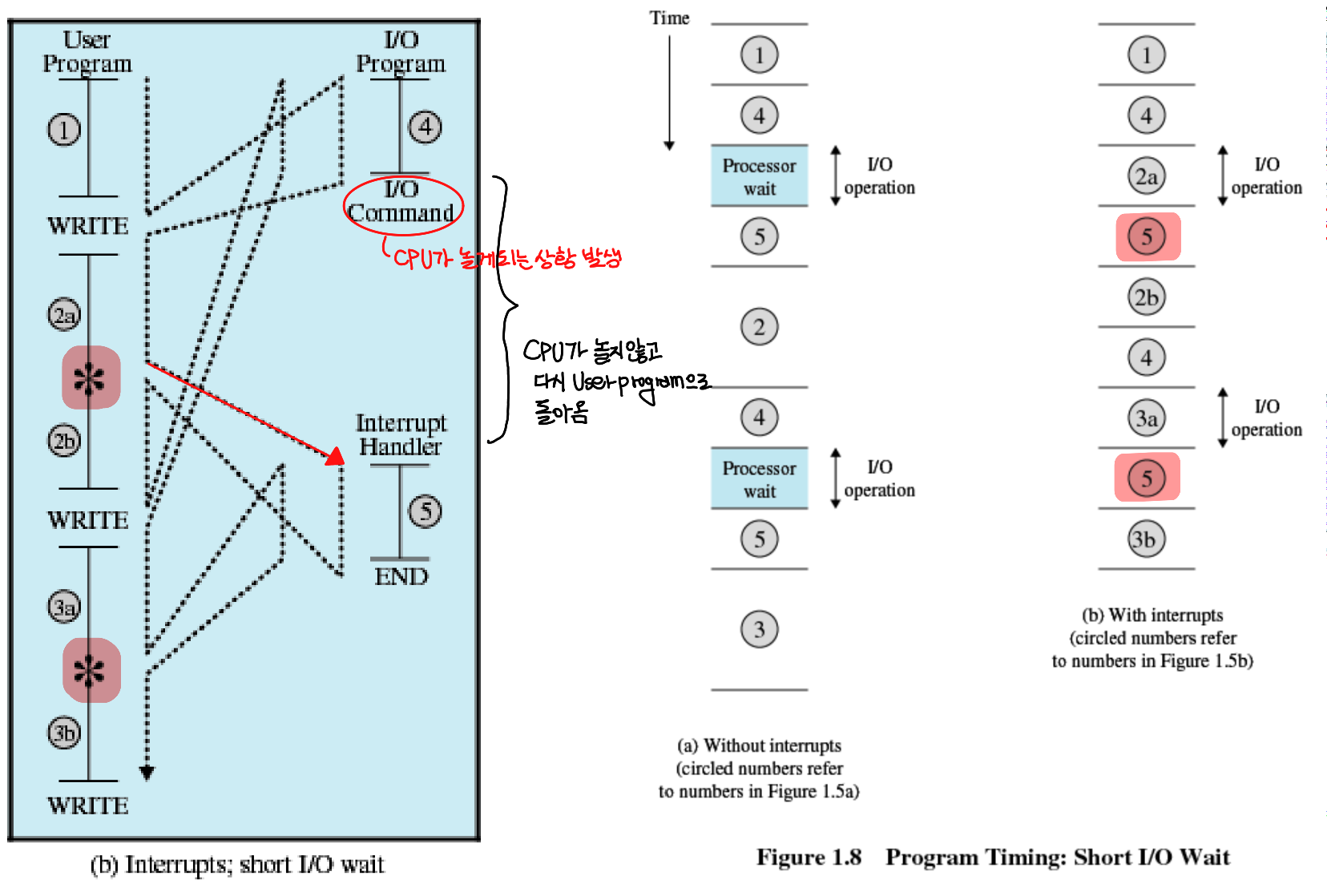
CPU가 노는 것은 죄악이다
교수님의 명언이다.
위의 표에서 processor wait이라는 부분이 존재한다. 이 시기에 program은 I/O로부터 interrupt 신호를 받고 I/O 프로그램을 실행중인데, 이 과정 동안 I/O가 다 끝날 때까지 CPU는 대기를 해야한다. CPU가 초당 어마어마한 양의 일을 하는 것을 감안하면 저렇게 기다리는 것은 시간적으로 엄청난 낭비가 아닐 수 없다.
이 문제를 해결하기 위한 방법으로 다음과 같은 방법이 존재한다.
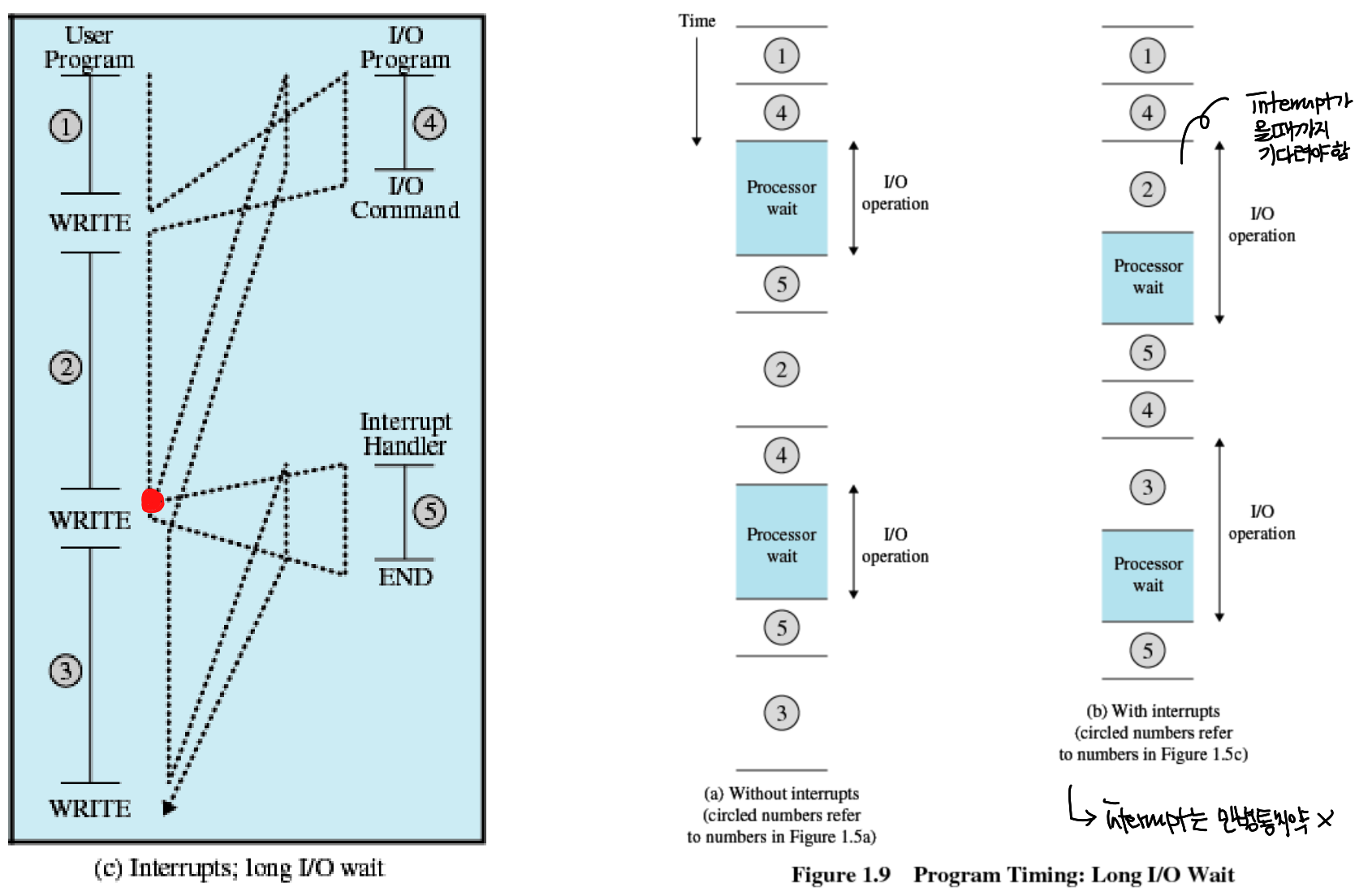
그러나, 이 방법 역시 효율적이지 못하다는 것을 알 수 있다.
예를 들어, WRITE 작업을 하고 있는데 아직 작업이 끝나지 않았음에도 불구하고 다음 WRITE를 받게 된다면 문제가 생길 수 있다.
그렇기 때문에 여기서 Multiprogramming 이라는 개념이 등장하게 된다.
- Processor가 실행해야할 프로그램 1
- 프로그램의 순서는 상대적인 우선순위와 프로그램들이 I/O를 기다리고 있는지 여부에 따라 달라진다.
- Interrupt handler가 끝난 이후에도 interrupt 당시 실행중이던 프로그램에게 control이 돌아가지 않을 수 있다.
Memory Hierarchy
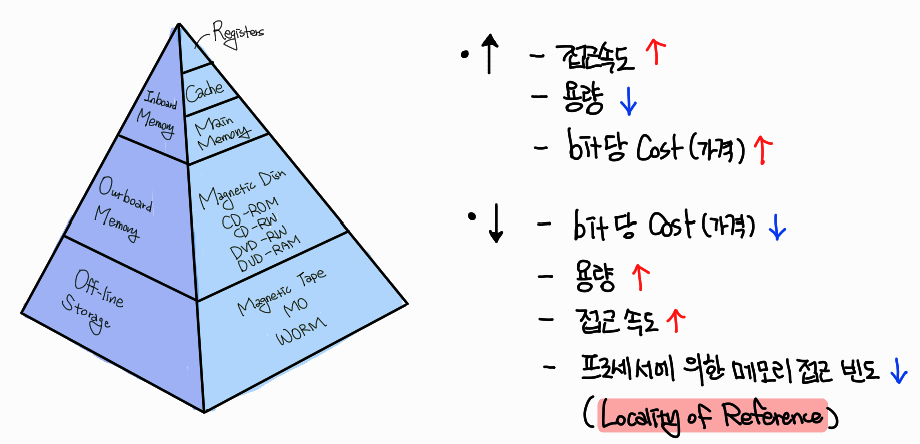
Memory Hierarchy를 보면 제일 위에가 Register가 있고 내려오면 내려올수록 컴퓨터와는 거리가 점점 멀어지는 느낌이 든다.
위로 올라갈수록 접근속도는 빨라지고 용량은 작아지고 bit당 가격이 비싸진다. 반대로 말하면 아래로 내려가면 내려갈수록 접근속도는 느려지고 용량이 커지고 가격도 저렴해진다. 여기서, 제일 중요한 부분이 processor에 의한 memory의 접근 빈도도 줄어든다는 점이다. 이를 한마디로Locality of Reference라고 하는데, 이 개념을 주목할 필요가 있다.
- Locality of Reference
: 자주 접근되는 data일수록 빠른 저장장치에 저장되고 주소가 서로 가까운 명령어에 접근하려는 경향이 높다는 의미이다.
Cache Memory
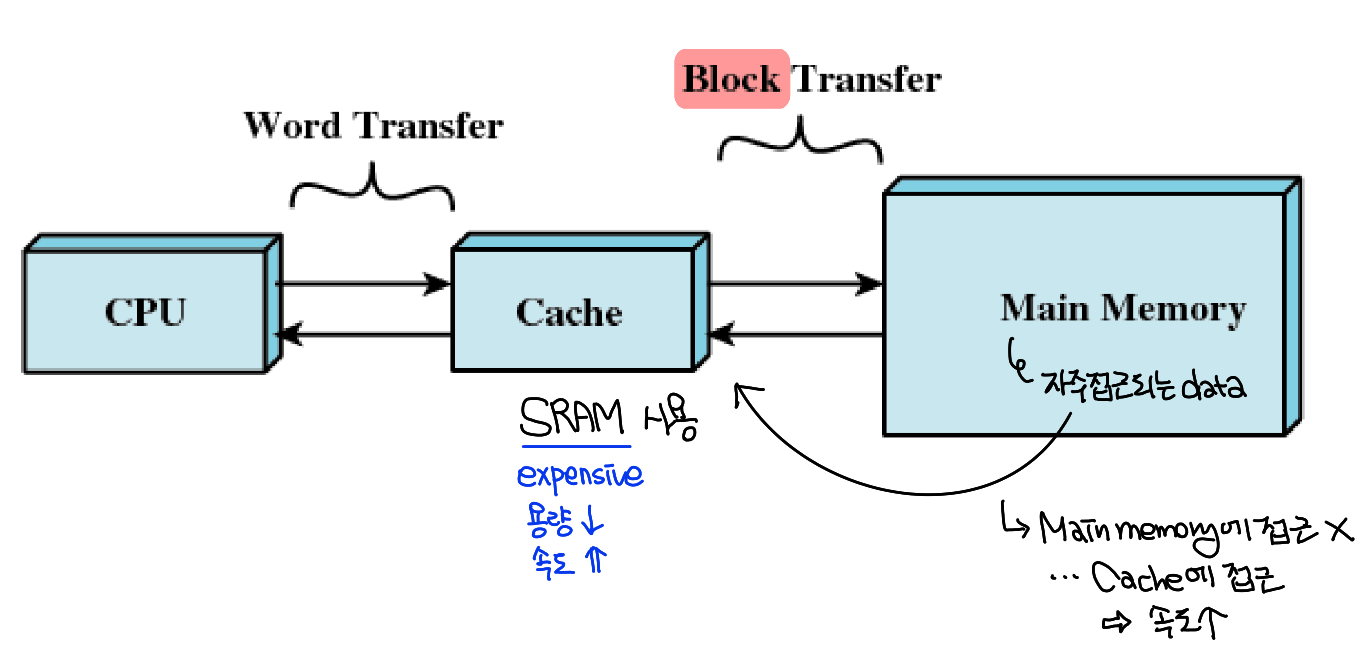
Processor가 instruction들을 실행할 수 있는 비율은 memory cycle 시간에 의해 제한되어 있기 때문에 CPU와 Memory 사이에 속도 차이 문제가 생긴다. 이를 방지하고 locality를 이용하기 위해 CPU와 Memory 중간에 속도가 빠른 메모리 하나를 집어 넣었는데 이게 Cache Memory이다. Cache Memory의 존재로 인해 Memory에 대한 접근이 최소화되어 성능이 좋아지게 된다.
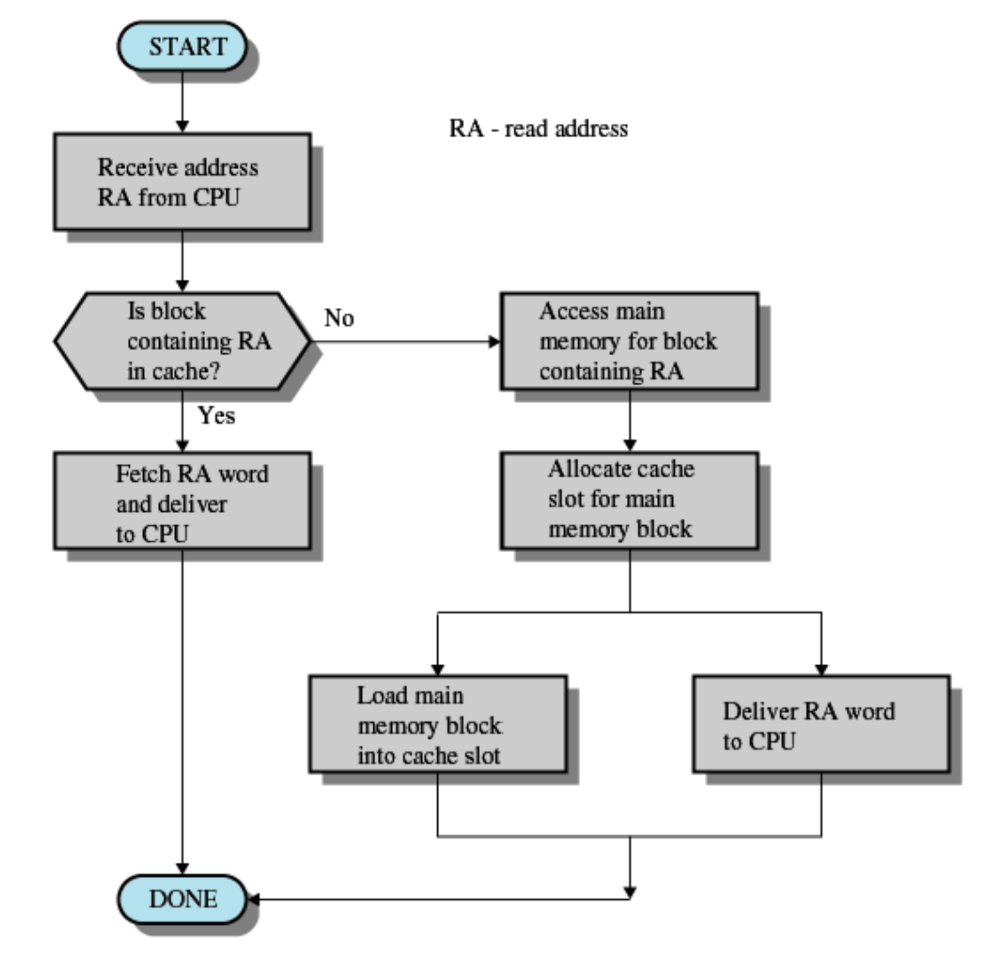
Cache Read Operation
1. Main Memory의 일부분을 복제
2. Processor가 가장 먼저 check를 하는게 Cache Memory
3. 만약 Cache에 필요한 정보가 없다면 필요한 정보가 있는 Block이 Cache로 이동한 뒤 processor에게 전달된다.
Cache Design
1. Cache Size
: Small caches have a significant impact on performance
== 크기 대비 성능이 매우 좋다
2. Block Size
: Cache와 Main memory 사이에 data가 교환되는 단위
cf) Block 단위로 data에 접근하는 이유
만약 word 단위로 하게될 경우 Block 단위일 때보다 Memory 접근 횟수가 많아지게 되어 효율성 및 성능이 저하된다. 하나의 Block은 여러 개의 Word로 구성되어 있기 때문에 Memory에 접근하는 횟수가 줄어들게 되어 시간이 단축된다.
- Block의 크기가 크면 클수록
Cache Hit의 확률이 높아지지만, Cache Memory의 사용 목적이 자주 사용되는 data에 빠르게 접근하기 위함인데 Block의 크기가 너무 커지면 Block의 크기만큼 Cache Memory의 크기도 커지게 되고 그렇게 되면 자주 사용하지 않는 data임에도 Block에 포함되어 Cache Memory에 들어가게 될 수 있다.
3. Mapping function
: Block이 Cache Memory에 어느 위치에 들어가게 될지를 결정한다.
4. Replacement Algorithm
: Cache Memory가 가득 차서 더이상 새로운 Block을 받아들이지 못할 경우 사용하는 알고리즘이다.
- Mapping function이 block이 들어갈 위치를 결정했다면, Replacement algorithm은 어느 Block이 대체 되어야 하는지를 결정한다.
- Least-Recently-Used (LRU) algorithm
5. Write policy
: Memory에 write operation이 실행될 경우 시행
(A) Block이 update 될 때마다, (B) Block이 replace 될 때마다 두 가지 경우가 있다. 즉, 바로 전달할지 아님 나중에 전달할지를 결정하는 것이다.
먼저 Block이 update 될 때마다 write policy가 실행되게 된다면, Cache에 update 할 때마다 Memory도 update가 되기 때문에 접근 횟수가 증가하게 된다.
그 다음으로 Block이 replace 될 때마다 실행이 된다면, memory write operation의 횟수가 줄어들게 되는데 첫 번째 방법과 달리 Memory는 Cache가 update 되어도 update가 되지 않기 때문에 계속 obsolete한 상태로 남아있게 된다. 더하여 multicore나 multiprogramming system에서는 cache coherence problem이 생길 가능성이 있다.
Computer System Operation
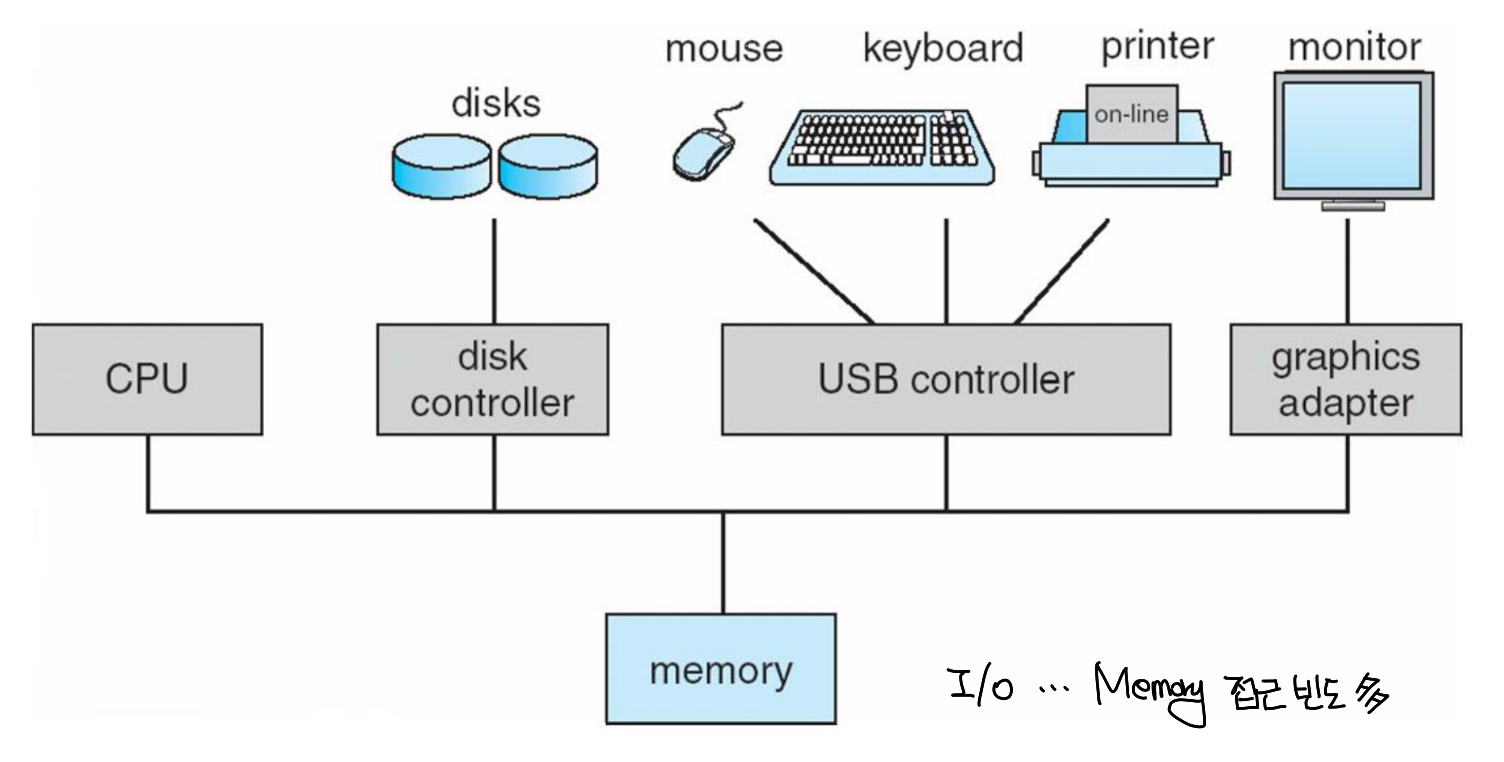
- I/O device와 CPU는 동시에 execute 할 수 있다.
- 각각의 device controller는 특정한 유형의 device를 담당한다.
- 각각의 device controller는 local buffer를 갖는다.
- CPU는 main memory와 local buffer 사이의 data를 이동시킨다.
- I/O는 device에서 시작해서 controller의 local buffer로 간다.
- Device controller는 interrupt를 불러옴으로써 operation이 끝났음을 CPU에게 알린다.
Programmed I/O
- Interrupt 발생하지 않음
- operation이 끝날 때까지 processor가 상태를 확인한다.
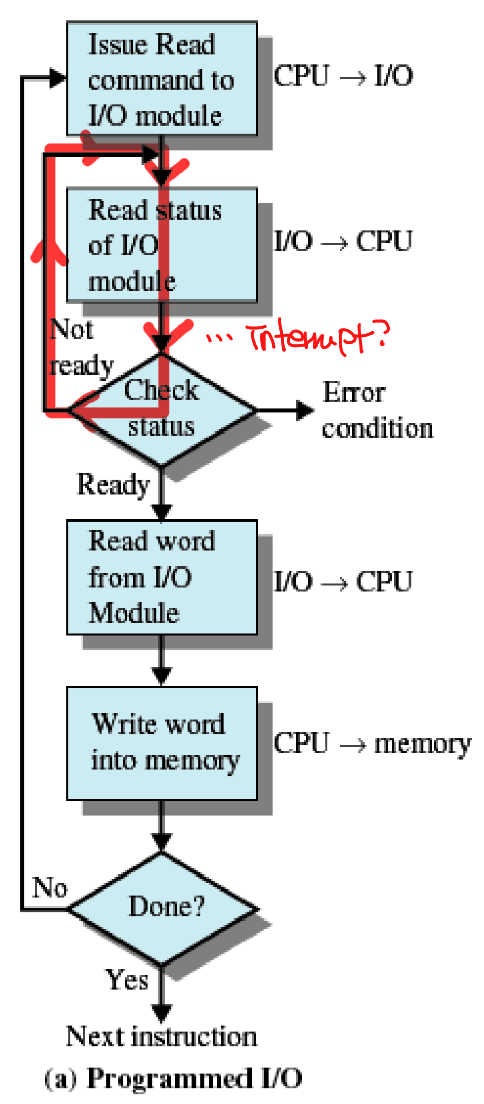
이 경우, operation이 끝날 때까지 상태 확인을 무한 반복하기 때문에 비효율적이라고 말할 수 있다.
Interrupt-Driven I/O
- I/O module이 data를 교환할 준비가 되면 processor에 interrupt가 실행된다.
- 이 때 processor는 실행중이던 program의 context를 저장하고 interrupt-handler를 실행시킨다.
- 불필요한 waiting X
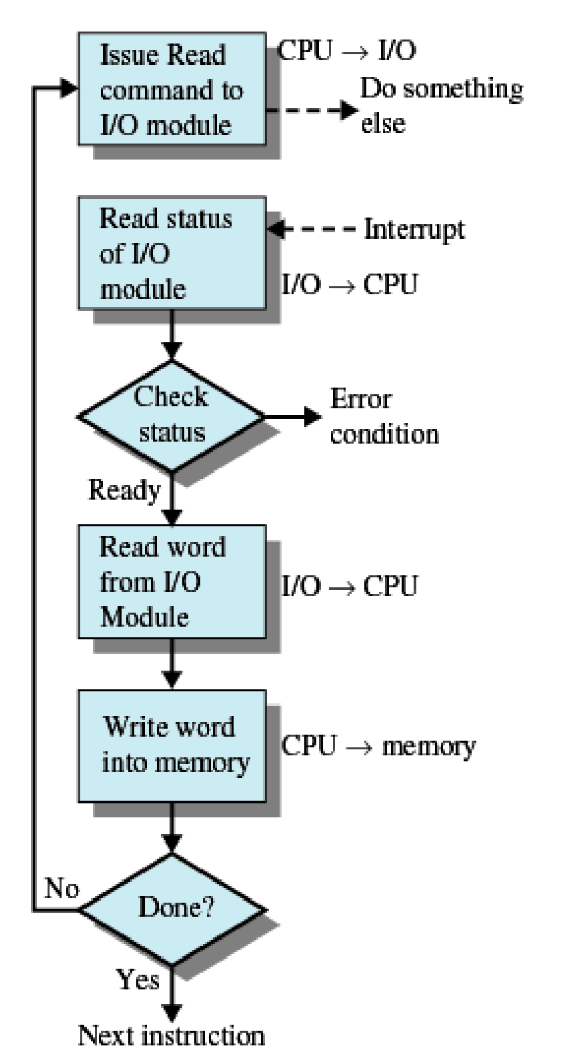
이 경우 Programmed I/O와 달리 불필요한 waiting이 없다는 점이 장점이지만 그럼에도 한 word를 읽을 때마다 모든 과정을 반복하기 때문에 시간이 오래걸린다는 문제는 해결되지 않았다.
예를 들어 1 word = 4 byte 라고 가정하였을 때 만약 4KB 크기의 데이터를 읽고자 한다면 만큼의 반복이 필요하게 된다.
이 모든 문제의 근원은 Memory 접근의 경우 device로는 불가능 하다는 이유 때문이다. CPU 입장에서 하드디스크는 어디서 만들어졌고 어떻게 쓰이는지 믿을 수 없기 때문에 주변장치에게는 Memory에 대한 접근 권한을 부여하지 않았다.
그러므로 위에서 시간이 오래 걸린다는 문제의 경우 device가 직접 접근을 할 수 있도록 하면 해결이 되지만 그렇게 하고 싶어도 할 수가 없는 상황이다.
이를 극복하기 위해 DMA라는 개념이 등장하게 된다.
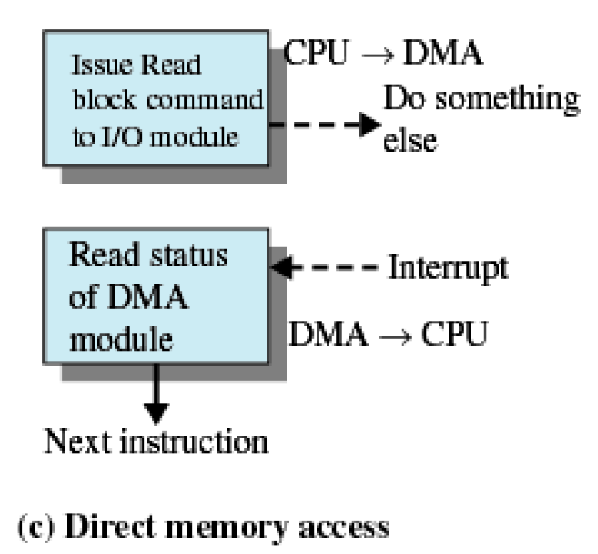
Direct Memory Access (DMA)
: CPU가 아닌 다른 장치가 직접적으로 Memory에 접근을 하는 방법이다. 원래의 I/O device의 경우 OS 입장에서는 비신뢰장치이기 때문에 OS가 신뢰영역에 대한 접근을 차단하지만, 효율의 증가를 위해 OS가 신뢰할 수 있는 Hardware를 만들어서 직접적인 접근을 허용하게 하는 방법이다.
- Processor가 I/O module에게 read/write 권한을 부여
- Exchange에 대한 processor의 임무를 위임받는다
- Memory로 block 단위의 data를 교환하거나 Memory로부터 block 단위의 data를 교환받는다
- 교환이 끝나면 interrupt가 전송된다
- Processor는 그 동안 다른 작업을 한다
Computer Start-up
메인보드에 위치한 ROM (Read-Only Memory)에 있는 bootstrap program이 Memory에 올라가게 되면 CPU가 이를 확인 후 실행을 하는데 그 과정에서 Hardware를 초기화하고 Operating System을 Memory에 올린 뒤 OS program을 실행하게 되면 booting이 끝난다.
이렇게 첫 번째 OS에 대한 글이 끝났다. OS의 경우 기술 면접 단골 주제이기도 하고 Core 과목이기 때문에 개념과 내용에 대한 이해는 말할 것도 없고 암기가 필수라고 생각한다. 면접에서 운영체제에 대한 개념을 물어보았을 때 막힘없이 술술 설명할 수 있을 정도가 될 때까지 끊임없이 보아야 할 것이다.
그렇기 때문에 알고리즘, 운영체제 같은 책을 평생을 책장에 놓고 보는 <장서>라고 부르는 이유이지 않나 싶다.
위에 정리한 내용의 경우 운영체제 강의 pdf와 Operating System Concepts (A.K.A 공룡책)을 기반으로 작성한 내용인데 직역이 아니라 이해한 내용을 바탕으로 작성을 했기 때문에 틀린 부분이 있을 수 있습니다. 저도 처음 배우는 입장이기 때문에 편하게 지적해주시면 배움에 도움이 될 것 같습니다. 감사합니다.
