썸네일 화질 문제를 셀레니움으로 해결한 경험
seoltab books 프로젝트
이 서비스는 교재를 쇼핑처럼 고르고 결제하면 실물 책 + PDF 파일까지 같이 주는 그런 구조였고, 나는 어드민 페이지 개발을 담당했다.
배포 이후 슬랙에 이런 피드백이 올라왔다
책 썸네일 이미지 화질이 너무 안 좋아요
썸네일이 보여지는 영역은 사용자용 서비스의 프론트였고, 내 담당 범위는 아니었다. 하지만 썸네일이 지나치게 뿌연 것이 눈에 띄었고 — 직접 개선해볼 수 있을 것 같았다.
처음엔 next/image 문제인 줄 알았다
처음엔 Next.js의 next/image 컴포넌트에서 quality 기본값(75)이 낮아서 그런 줄 알았다.
그래서 quality={100}으로 바꿔봤지만, 여전히 화질이 좋지 않았다.
알고 보니, 원본 이미지 자체가 저화질
조금 더 파보니, 썸네일 이미지는
알라딘 Open API에서 받아와 DB에 저장된 것이었고, 이 API가 기본적으로 해상도가 낮은 이미지를 제공하고 있었다.
그래서 직접 알라딘 웹사이트에 들어가
개발자 도구로 목록과 상세 페이지에서 불러오는 이미지 크기를 비교해봤다.
- 목록 페이지: 이미지 원본 크기 200x267
- 상세 페이지: 이미지 원본 크기 500x687
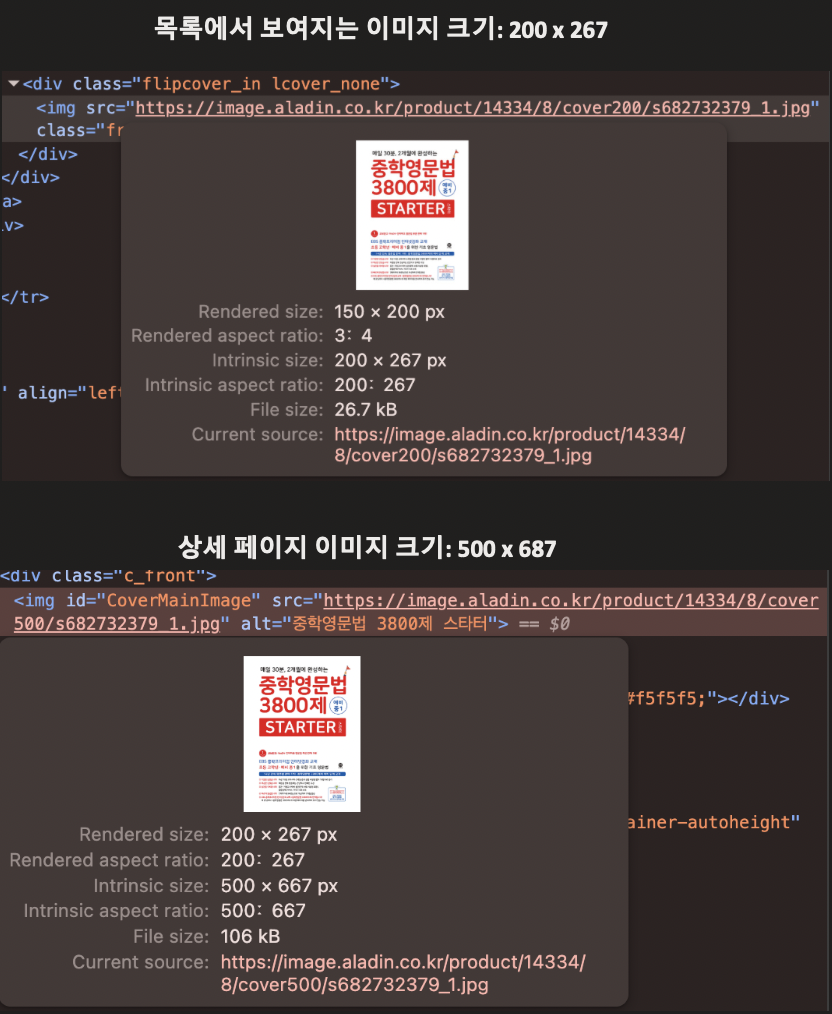
즉, 같은 책 데이터인데도 목록과 상세 페이지에서 불러오는 이미지 품질이 달랐다.
우리가 쓰고 있던 API는 목록 페이지 기준 이미지만 내려주고 있었던 셈이다.
그래서 상세 페이지로 이동해 원본 이미지 URL을 추출하는 방식으로 크롤링을 진행하기로 했다.
셀레니움으로 고화질 이미지 크롤링
예전에 pyautogui나 selenium으로 매크로 작업을 해봤던 경험이 있어서
고화질 이미지를 크롤링하는 자동화 코드를 직접 짜보기로 했다.
크롤링 흐름은 다음과 같았다
- ISBN으로 알라딘에서 책 검색
- 책 상세 페이지로 이동
<img>태그에서 고화질 이미지 URL 추출- 약 3,000권 순차 처리
- 중간 예외 처리, sleep 간격 조정, 로그 저장 등 안정성 확보
크롤링 결과는 엑셀로 정리
크롤링한 데이터를 나중에 다시 확인하거나 공유하기 쉽게 pandas로 데이터프레임으로 정리한 뒤 .xlsx 파일로 저장했다.
import pandas as pd
df = pd.DataFrame(results) # title, isbn, image_url 등 포함
df.to_excel("book_thumbnails.xlsx", index=False)
썸네일 화질 개선 완료
이후 교체된 썸네일은 눈에 띄게 선명하고 깔끔해졌다.
기존엔 저해상도 이미지를 강제로 키워서 보여주던 탓에 뿌연 느낌이 있었는데,
이제는 고화질 원본 이미지로 교체되어 훨씬 또렷했다. next/image의 quality 값을 100으로 하면 더 좋아질 수도 있겠지만, 로딩 시간이 길어질 수 있어서 그건 판단해서 써야 한다고 말씀 드렸다.
그래도 담당 개발자분은 기존처럼 75로 유지하셨고 이미 원본 이미지가 고화질로 바뀐 덕에 그 정도도 충분히 괜찮았다.
마무리하며
내가 직접 담당한 영역은 아니었지만,
눈에 띈 문제를 보고 주도적으로 해결해본 경험이라는 점에서 의미 있었다.
단순히 스타일이나 UI 문제가 아니라 데이터 소스 품질 자체가 사용자 경험에 얼마나 큰 영향을 주는지 느낄 수 있었고,
셀레니움 같은 자동화 툴로 현실적인 해결책을 만든 것도 유익한 경험이었다.
