Evaluation Metric
Perplexity (PPL)
주요 사용 Task
- 언어 모델링
정의
- 주어진 문장(sequence)에서 확률을 기반으로 언어 모델의 성능을 평가하는 지표
- 낮은 값일수록 모델이 토큰 확률 분포를 잘 예측함. 즉, 낮을수록 성능이 좋음
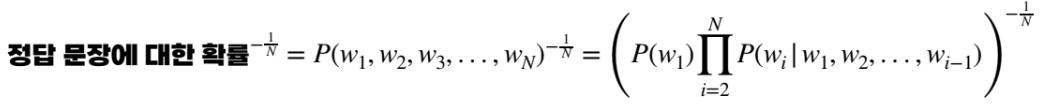
수식
- N : 문장 내 단어의 개수
- Wi : 문장 내 i 번째 단어
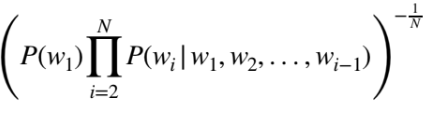
계산과정
- 이전 단어들 (w1,w2,...)이 주어졌을 때 wi가 나올 조건부 확률들을 모두 곱함
- 곱셈 결과에 N제곱근의 역수를 취해줌.
예제
N=3, P=1/100 이라고 가정하자.
이는 문장 내 단어의 수가 3개이고, 각 단어의 등장 확률이 1/100 이라는 것이다. 즉, 각 단어의 후보는 100이다.
- 각 단어 등장 확률이 1/100 (P) 라면, 전체 문장의 올바른 단어 선택 확률은 P(w1) P(w2|w1) P(w3|w1,w2) = (1/100) (1/100) (1/100) = 1/1000000 이 된다.
- 곱셈 결과에 N제곱근의 역수를 취해주면 PPL = (1/1000000)^1/3 = 100 이 된다.
해석
Perplexity (PPL) 이 100이라는 것은 모델이 다음 단어를 예측할 때 평균적으로 100개의 가능한 선택지 중에서 하나를 고른다는 의미임. 즉, 불확실성이 100. 결국 작을수록 확실하다는 것.
Cross Entropy 와의 비교
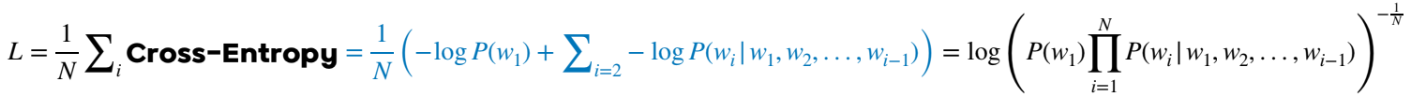
- 이전 단어들을 통해 현재 나와야할 정답 단어에 대한 확률을 loss에 사용한다.
- CELoss에 exp 취해주면 PPL이 된다!
BLEU (Bilingual Evaluation Understudy)
주요 사용 Task
- 번역, 요약
정의
- 모델이 생성한 텍스트와 정답 텍스트 간의 유사성을 측정하는 지표
- 0~1 사이값 나옴
수식
Pn : n-gram precision - 예측과 실제 텍스트 사이의 n-gram 정밀도. n-gram은 연속된 n개의 단어 seqence.
Wn : Weight, 합=1 - 각 n-gram precision의 가중치
BP : Brevity(짧음) penalty - 길이 페널티, 예측 문장이 정답 문장보다 짧을 때 페널티 적용
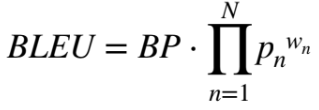
- BLEU는 n-gram 정밀도를 기반으로 짧은 길이의 벌점을 보정하는 BP를 사용하여 계산됨
예제
- 정답 텍스트 : The cat is on the mat.
- 예측 텍스트 : The cat is on a mat.
- 1-gram precision : the/a 제외하고 6개 단어 중 5개 단어 일치 -> 5/6
- 2-gram precision : "The cat", "cat is", "is on", "on a", "a mat" 5개의 연달은 단어의 조합 중 3개(on a, a mat 두개가 다름)가 일치 -> 3/5
- BP 계산 - 예측길이=정답길이 이므로 BP=1
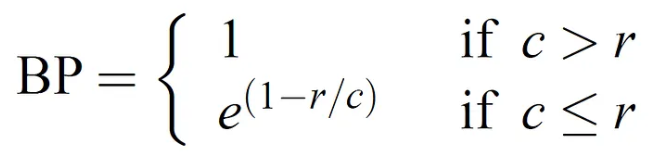
- 여러 문장에 대한 BLEU score를 계산하는 경우

GLUE, SuperGLUE
- General Language Understanding Evaluation benchmark
- 다양한 자연어 처리 문제 데이터셋의 묶음이며, 해당 task에 대한 종합 성능을 보여줌
- GLUE는 표준 난이도의 NLU 능력을 종합적 평가 가능
- SuperGLUE 는 어려운 난이도의 NLU 능력을 종합적 평가 가능
Downstream Dataset
- 각 문제에 대한 데이터셋
- NLI(문장 관계 추론), QA, Sentense Similarity, Classification 등 Downstream task 존재
1. NLI task
- 두 문장 사이의 관계를 판단하는 task (분류문제)
- MNLI, QNLI, SNLI, RTE 등 다양한 데이터셋 존재
SNLI
- The Stanford Natural Language Inference 의 약자
- Text는 이미지의 캡션, Hypothesis는 Text를 보고 만든 문장
- 5명이 E, C, N 중 판단하고, 다수결로 label 결정됨
- Entailment(E) - Text를 봤을 때, Hypothesis가 진실
- Contradiction(C) - Text를 봤을 때, Hypothesis가 모순
- Neutral(N) - Hypothesis가 진실인지 모순인지 알수 없는, Text와 Hypothesis이 관계가 없는 경우

QNLI
- Question NLI
- 질문에 대한 답변을 포함(Entailment) 하고 있는지 그렇지 않은지 판단

MNLI
- MultiNLI
- SNLI와 같으나 출처가 이미지 캡션이 아니라 소설, 공식문서 등 다양함.
- MNLI-m 은 matched, MNLI-mm 은 mismatched를 의미
- e.g) train 데이터와 test 데이터가 같은 장르 vs 다른 장르
2. QA task
- 사용자의 질문에 대한 답변 제공
RACE
- ReAding Comprehension dataset from Examinations
- 영어 시험 문제 본문과 질문 및 선택지를 보고 답을 찾는 다중 분류 데이터셋

Story Cloze
- 이야기가 주어지고 거기에 맞는 두개의 결말 문장이 있을 때 Right Ending이 무엇이지 고르는 문제를 푸는 데이터셋
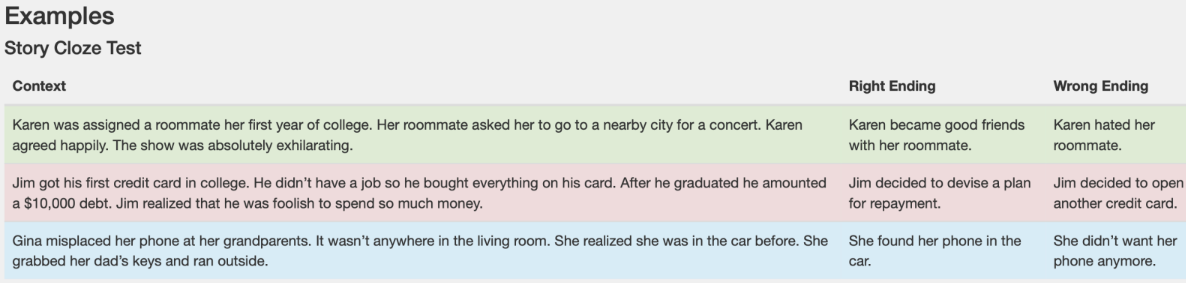
Sentense Similarity
- 두 문장이 얼마나 유사한지를 측정
MRPC
- MSR(Microsoft Research) Paraphrase Corpus
- Paraphrase 란 동일한 의미의 다른 문장을 의미
- 두 문장의 유사도를 평가하는 이진 분류 데이터셋

QQP
- Quora Question Pairs
- Quora(해외 지식in) 에 올라온 두 질문이 중복되는지(1) 아닌지(0) 판별하는 이진 분류 데이터셋

STS
- Semantic Textual Similarity benchmark
- 유사도 점수(label) 이 0~5 사이로 되어있음. 소수점 단위라 결국 회귀문제.

3. Sentiment Analysis
- 문장의 감성에 대한 분류
SST
- Stanford Sentiment Treebank
- 영화 감상평이 긍정적(1)인지, 부정적(0)인지 이진 분류하는 데이터셋
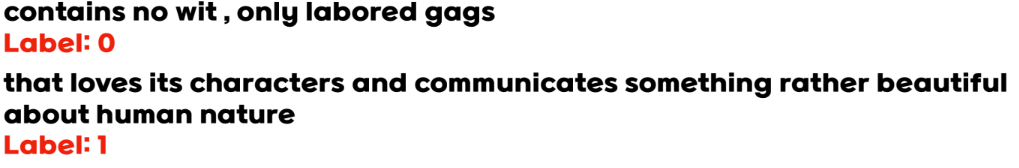
4. Sentense Classification
- 문장을 특정 조건 하에 분류하는 문제
CoLA
- Corpus of Linguistic Acceptability
- 문장이 문법적으로 옳은지(1) 틀리거나 어색한지(0) 이진 분류하는 데이터셋


고려대학교 인공지능학과 SLP Lab 석사과정생