X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION
1. Background
최근 연구 동향
- 학습된 ASR(STT)모델에서 latent vector 중 화자 정보 feature를 이용하여 화자 인식 Task 수행 가능
- 기존 화자인식(Speaker Recognition)에는 i-vector를 사용하였음
용어정리
- 화자인식은 i-vector, d-vector, x-vector, t-vector 등을 이용해서 수행할 수 있음
- i-vector : Acoustic Feature를 이용하여 통계적 모델링을 통해 화자정보 벡터로 압축
- x-vector : Acoustic Feature를 이용하여 DNN 모델링을 통해 화자정보 벡터로 압축
기존 화자 인식 방법 (with i-vector)
- Acoustic Feature를 UBM을 통해 고차원의 통계량을 분석함(sample에 대한 유사성)
- UBM에 의거하여, Large Projection Matrix T에 투영하여 각 화자의 저차원의 representation으로 mapping 하고, 이 압축된 벡터를 i-vector라 함. T는 Data Likelyhood를 maximize하도록 학습됨.
- i-vector에 PLDA(Probabilisitic Linear Discriminant Analysis) Classifier를 붙여서 같은 화자인지 다른 화자인지 구분.
i-vector의 한계
- i-vector는 통계적 모델링 기법이기에, 학습 데이터가 매우 많아야 함.
- 데이터가 많아야 하기에, noise를 부여하는 등 augmentation 을 수행하였지만, PLDA Classifier에서는 효과가 있었으나, 실제 feature를 더 잘 extract하지는 못했음
x-vector 제안
- (대규모 데이터셋 수집 문제 해결) DNN으로 Supervised Modeling하면 적당한 양의 데이터로도 화자정보 feature를 잘 뽑을 수 있음
- (augmentation을 통한 성능 향상 확인) 데이터에 Augmentation을 수행하였을 때, 화자정보 Feature를 잘 Extract했고, Robustness도 강화되었음
2. Baseline Method (i-vector)
1. Acoustic i-vector
-
전통적인 GMM-UBM based i-vector system을 baseline으로 이용하였음
-
기본 MFCC(20차원) + 델타(feature의 1차 차분)(20차원) + 가속(델타의 1차 차분)(20차원) = 60차원 feature 사용
-
수집 절차
- 음성 샘플에서 MFCC, Delta, Accelerate 를 추출하여 총 60차원 feature 추출
- 2048 component를 사용하여 UBM 학습
- 각 화자에 따른 Baum-Welch 통계량 계산
- 통계량을 이용하여 600차원 i-vector 추출
- i-vector를 이용하여 PLDA Classifier 학습 후 평가
-
코드 예제
- 음성 데이터 준비
def load_audio(file_path):
signal, sr = librosa.load(file_path, sr=None)
return signal, sr - 특징 추출
def extract_features(signal, sr):
mfcc = librosa.feature.mfcc(signal, sr=sr, n_mfcc=20)
delta = librosa.feature.delta(mfcc)
delta2 = librosa.feature.delta(mfcc, order=2)
features = np.vstack((mfcc, delta, delta2))
return features.T - UBM 학습
def train_ubm(features, n_components=2048):
gmm = GaussianMixture(n_components=n_components, covariance_type='full', max_iter=100)
gmm.fit(features)
return gmm - Baum-Welch 통계 계산
def compute_baum_welch_statistics(gmm, features):
responsibilities = gmm.predict_proba(features)
n_k = np.sum(responsibilities, axis=0)
f_k = np.dot(responsibilities.T, features)
s_k = np.dot(responsibilities.T, features**2)
return n_k, f_k, s_k - i-vector 추출
def extracti_vector(gmm, n_k, f_k, s_k, total_variability_matrix):
supervector_mean = gmm.means.flatten()
supervectorcovariance = np.diag(gmm.covariances.flatten())
ivector = np.dot(total_variability_matrix.T, np.linalg.inv(np.dot(total_variability_matrix, total_variability_matrix.T) + supervector_covariance))
ivector = np.dot(ivector, (f_k.flatten() - n_k * supervector_mean))
return ivector - PLDA Modeling & Evaluate
def train_plda(vectors, labels):
scaler = StandardScaler()
vectors = scaler.fit_transform(vectors)
lda = LinearDiscriminantAnalysis(n_components=150)
vectors_lda = lda.fit_transform(vectors, labels)
mean_vectors = np.mean(vectors_lda, axis=0)
cov_matrix = np.cov(vectors_lda, rowvar=False)
return mean_vectors, cov_matrix, scaler, lda
화자 인식 (유사도 계산)
# def plda_score(test_vector, mean_vectors, cov_matrix, scaler, lda): test_vector = scaler.transform([test_vector]) test_vector_lda = lda.transform(test_vector) # 유사도 계산 (간단한 Mahalanobis 거리 예제) diff = test_vector_lda - mean_vectors score = -np.dot(np.dot(diff, np.linalg.inv(cov_matrix)), diff.T) return score - 음성 데이터 준비
2. Phonetic Bottleneck i-vector
- Pretrained ASR 모델의 Hidden Feature들 중, Acoustic Feature(BNF, 60차원)를 가져와서 Feature를 생성
- 바로 위 단원의 Acoustic i-vector에서의 MFCC(20차원), 델타(20차원) 과 BNF(60차원) 을 합쳐서 총 100차원 Feature를 input feature로 사용
- 나머지 UBM, PLDA-Classifier의 구조는 위 단원과 동일
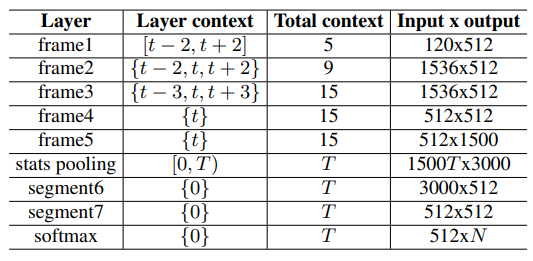
3. Method (X-vector)
# class XVectorModel(nn.Module):
# def __init__(self):
super(XVectorModel, self).__init__()
# Frame layers
self.frame1 = nn.Conv1d(in_channels=120, out_channels=512, kernel_size=5, stride=1, padding=2)
self.frame2 = nn.Conv1d(in_channels=1536, out_channels=512, kernel_size=3, stride=1, padding=1)
self.frame3 = nn.Conv1d(in_channels=1536, out_channels=512, kernel_size=3, stride=1, padding=1)
self.frame4 = nn.Conv1d(in_channels=512, out_channels=512, kernel_size=1, stride=1)
self.frame5 = nn.Conv1d(in_channels=512, out_channels=1500, kernel_size=1, stride=1)
# Stats pooling layer
self.pooling = nn.AdaptiveAvgPool1d(1)
# Segment layers
self.segment6 = nn.Linear(3000, 512)
self.segment7 = nn.Linear(512, 512)
# Softmax output layer (for training, assuming N speakers)
self.softmax = nn.Linear(512, 100) # Assuming 100 speakers for training
def forward(self, x):
x = torch.relu(self.frame1(x))
x_spliced = self.splice_context(x, left=2, right=2) # Splice context for frame2
x = torch.relu(self.frame2(x_spliced))
x_spliced = self.splice_context(x, left=2, right=2) # Splice context for frame3
x = torch.relu(self.frame3(x_spliced))
x = torch.relu(self.frame4(x))
x = torch.relu(self.frame5(x))
# Stats pooling
mean = self.pooling(x)
std = torch.sqrt(self.pooling(x**2) - mean**2)
stats = torch.cat((mean, std), dim=1)
stats = stats.view(stats.size(0), -1)
x = torch.relu(self.segment6(stats))
x = torch.relu(self.segment7(x))
x = self.softmax(x)
return x
def splice_context(self, x, left=0, right=0):
""" Splice context frames around the current frame. """
T, D = x.size(2), x.size(1)
x_spliced = [x[:, :, max(0, t-left):min(T, t+right+1)] for t in range(T)]
x_spliced = torch.cat(x_spliced, dim=1)
return x_spliced4. Result
BenchMark Dataset
SITW Dataset
- 다양한 환경에서, 다양한 장비에서, 다양한 성별과 나이, 방언을 사용하는 화자의 데이터
SRE16
- 다양한 언어와 환경에서 수집된 음성 데이터를 포함하고 있으며, 화자 인식 기술의 발전을 촉진하기 위해 사용됨
Evaluation Metrics
EER
- False Acceptance Rate (FAR)와 False Rejection Rate (FRR)가 동일한 지점의 에러율
- FAR: 시스템이 잘못된 화자를 허용하는 비율.
- FRR: 시스템이 올바른 화자를 거부하는 비율.
- EER이 낮을수록 시스템의 성능이 좋음
DCF
- 시스템의 실제 운영 환경에서 발생할 수 있는 비용을 모델링.
- 목표 화자가 있을 확률에 따라 DCF10^-2, DCF10^-3으로 설정하여 계산
- 낮을수록 좋음


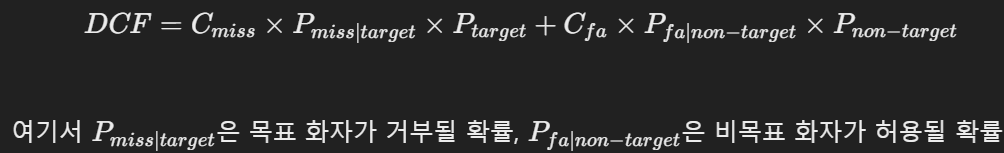
Main Result
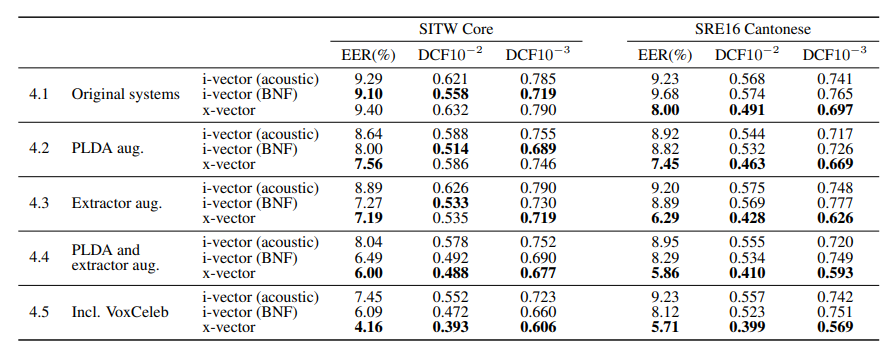
- Augmentation을 하지 않았을 때는 x-vector가 SITW 에서는 비슷하나, SRE16에서 전반적으로 좋은 성능을 보임
- PLDA Classifier만 Augmentation을 진행하여 학습한 경우도 Augmentation을 진행하지 않았던 경우와 결과가 비슷함.
- Extractor(ASR)에만 Augmentation을 진행한 경우 성능이 크게 올랐으며, 둘 다 Augmentation을 진행하여 학습했을 때 더욱 좋은 결과가 나타남.
- VoxCeleb 데이터를 추가하여 학습했을 때(데이터 추가) 더 좋은 성능
5. Conclusion
- i-vector는 transcribe된 데이터가 있어야 학습이 가능했지만, x-vector는 화자 label만 있어도 됨

고려대학교 인공지능학과 SLP Lab 석사과정생