도서 데이터 분석하고 싶으신분, 도서 데이터로 웹 만들고 싶으신분 주목!
도서정보, 음반정보, DVD, 전자책등 알라딘에서 가져올 수 있는 정보가 참 많습니다. 그리고 알라딘은 정말 카테고리가 세부적으로 분리되어 있기 때문에 도서 데이터를 분석하는데 사용하기도 굉장히 쉽습니다. 그럼 지금부터 저와 aladin api 사용해보시죠!
1. API KEY 받기
알라딘 API 블로그 바로가기!
위 링크를 타고 가서 TTB key 발급을 완료해주세요. 알라딘 아이디가 필요합니다! 여기서
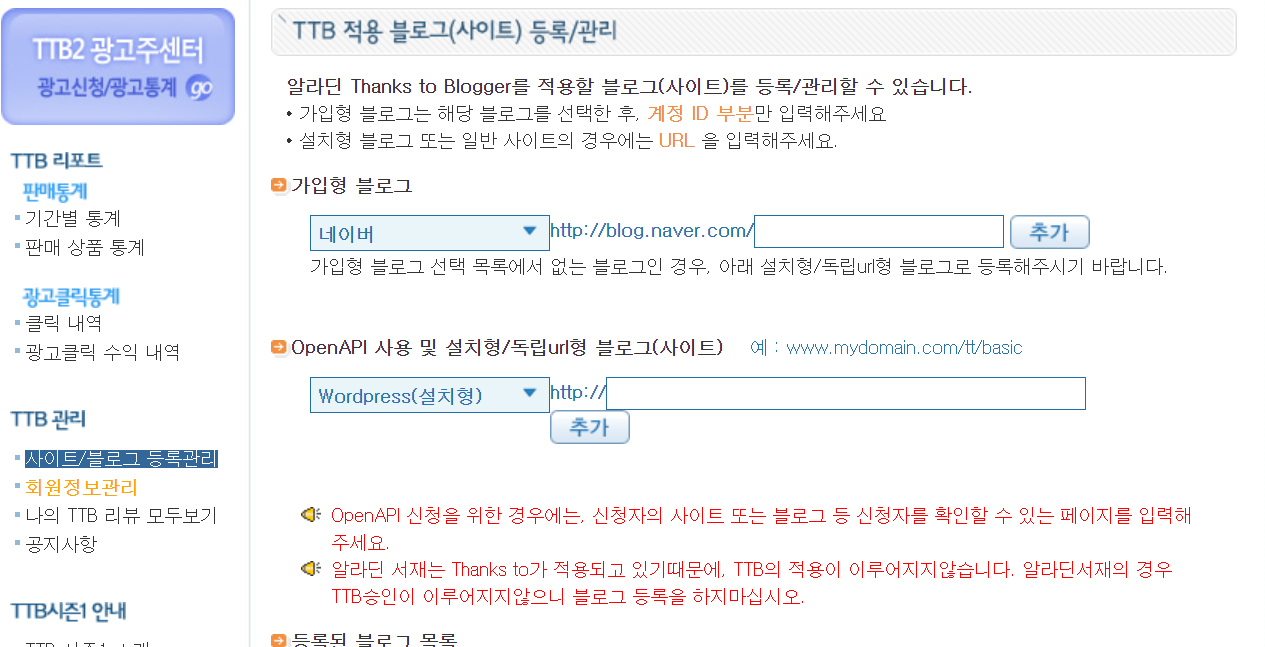
TTB 등록 칸에, 사이트/블로그 등록관리칸으로 들어가주세요. 개인 네이버 블로그 링크를 넣으면 key가 1~2일 뒤에 나옵니다.
혹은 따로 메일로 어떤 사이트를 개발하실 거라고 문의를 드리면 따로 방법이 있는걸로 압니다! 그냥 네이버 블로그 등록편이 빠르고 편해요...
2. 찾고 싶은 데이터에 맞는 API 골라보기
- 알라딘의 API 종류는 아래와 같습니다.
- 상품검색 API
- 상품리스트 API
- 상품조회 API
- 중고상품 보유 매장 검색 API
- 아래는 알라딘에서 제공하는 공식 api 메뉴얼입니다.
1.알라딘 open API 메뉴얼 바로가기!
2.알라딘 블로그에 정리된 짧은 버전!
3.알라딘 책 카테고리 설명이 되어있는 엑셀문서
들어가 보시고, 원하는 데이터가 뭔지 잘 찾아봅시다!
저는 신간 정보 리스트를 불러오고 싶어서, 상품 리스트 API를 사용해보도록 하겠습니다!
2. python으로 정보 불러와보기!
-
알라딘 API를 보면, 네이버나 카카오와 달리 header로 key를 주는 방식이 아니라, 그냥 요청 url을 보낼때, key값을 보내주면 됩니다.
-
자 이제, api를 python으로 사용해보겠습니다.
import os
import sys
import requests
import json
#키와 url 정의
key = [발급받은 키 입력]
url = f"http://www.aladin.co.kr/ttb/api/ItemList.aspx?ttbkey={key}&QueryType=ItemNewAll&MaxResults=100" \
"&start=1&SearchTarget=Book&output=js&Version=20131101&CategoryId=50993"
#request 보내기
response = requests.get(url)
#받은 response를 json 타입으로 바뀌주기
response_json = json.loads(response.text)
#확인
print(response_json)굉장히 요청 url이 긴데요. 해석해 보자면, QueryType=ItemNewAll, MaxResults=100, start=1, SearchTarget=Book, output=js, Version=20131101, CategoryId=50993은 각각 신간 도서 리스트, 최대 100페이지까지 검색, 검색은 1페이지부터 시작, 결과는 json형식으로, api버전은 20131101년걸로, 카테고리는 50993(2000년대 이후 한국소설)으로 된 데이터를 요청한 것인데요. 이러한 요청 변수들은 사이사이 &으로 이어주면 다른 서버에 한꺼번에 묶여서 요청이 갈 수 있어요.
이후, json파일에서 책 제목만 가져와 보는 과정까지 살펴보겠습니다.
title_list = []
for i in range(len(item_list)):
temp = item_list[i]['title']
title_list.append(temp)
print(len(title_list))이는 response_json를 프린트 한 결과를 보고 제가 제목만을 가져온 코드인데요. 데이터가 어떻게 생겼는지를 보시고 이 코드를 보시면 title을 가져오는 코드라는걸 바로 아시겠죠?
.png)