https://school.programmers.co.kr/learn/courses/30/lessons/42576
난이도
Level 1
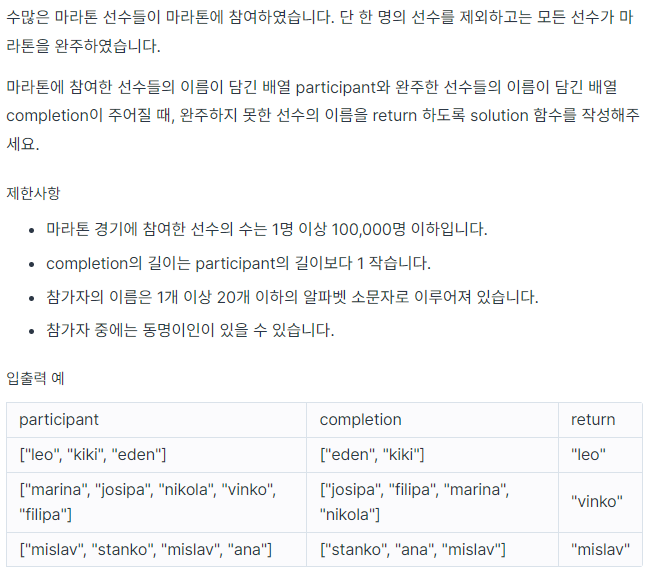
문제
코드
import java.util.*;
class Solution {
public String solution(String[] participant, String[] completion) {
HashMap<String, Integer> hm = new HashMap<>();
for(int i = 0; i < participant.length; i++){
hm.put(participant[i], hm.getOrDefault(participant[i], 0) + 1);
}
for(int i = 0; i < completion.length; i++){
hm.put(completion[i], hm.get(completion[i]) - 1);
}
for(String name : hm.keySet()){
if(hm.get(name) != 0){
return name;
}
}
return participant[participant.length - 1];
}
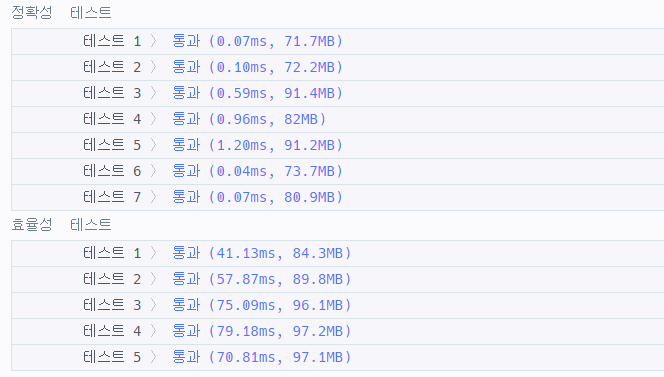
}예전에는 각각의 배열을 정렬한 뒤, 두 배열을 반복문으로 하나씩 비교하면서 다른 이름이 나오면 반환하는 방식으로 구현했다.
이번에 다시 풀어보다가 위 방식으로 똑같이 제출을 했는데 시간초과가 났다. 이 방식은 정렬 과정에서 O(n log n) 의 시간이 걸리기 때문에, 데이터가 많아지면 시간 초과가 발생할 수 있었던 것 같다.
그래서 이번에는 HashMap으로 구현을 해보았다. 정렬을 하지 않아도 되기 때문에 확실히 빠른 것 같다.
HashMap은 정렬 과정이 필요 없고, 내부적으로 해시 함수와 배열 기반 저장 구조를 사용하여 평균적으로 O(1) 시간에 탐색과 삽입이 가능하기 때문에 데이터를 훨씬 빠르게 처리할 수 있었고, 실제로 성능도 더 좋은 것 같다.