
속닥속닥 팀 프로젝트를 진행하면서 HikariCP 커넥션풀 설정을 진행했다. 진행하면서 고민한 내용과 과정을 정리해보자.
HikariCP란?
HikariCP 커넥션풀을 설정하기 전에 HikariCP가 무엇인지 짚고 가자.
HikariCP는 JDBC의 커넥션 풀 프레임워크이다. SpringBoot2.x부턴 커넥션 풀 관리를 위해 HikariCP를 사용한다.
Connection Pool이란?
그렇다면 connection pool이란 무엇일까?
Connection pool이란 WAS가 실행 될 때 DB연결을 위해 미리 일정수의 connection을 만들어 두는것이다. 사용자의 요청이 발생하면 Pool에 생성되어 있는 connection을 꺼내쓰고, 사용이 끝나면 다시 Pool에 반환한다.
Connection pool을 사용하는 이유?
Connection 생성은 비용이 크다.
Java에서 DB connection을 생성하는 과정은 비용이 크다. 사용자가 요청을 보냈을때 connection을 만든다면 요청에 대한 응답이 늦을 수 밖에 없다. 만약 미리 만들어놓은 connection을 사용한다면 그 만큼 더 빠르게 응답할 수 있는 장점이 있다.
Connection이 무한정 생성되는 것을 막을 수 있다.
동시에 수 많은 사용자가 요청을 보내면 어떻게 될까? 그 만큼의 connection이 생성될 것이다. 너무 많은 connection이 생성되면 컴퓨터의 한정적인 자원이 모두 고갈되어 더 중요한 일을 하지 못하게 된다.
Connection pool을 사용해 개수를 제한시킨다면 이런 자원고갈 문제를 해결할 수 있다.
적절한 connection pool의 개수는?
딱 떨어지는 개수는 말하기 어려울거 같다. WAS의 성능, DB서버의 성능, 요청한 api의 무거움 정도, 그리고 그 외에도 여러 요인이 존재하기 때문이다. 결국 우리는 최적의 connection pool 개수를 실제 성능테스트를 통해 추론할 수 밖에 없다.
성능테스트
우리의 목적은 성능테스트를 통해 적절한 HikariCP의 maxPoolSize를 구하는 것이다. 성능테스트를 어떻게 진행해야 할까? 성능테스트에 대해 찾아보니 생각보다 성능테스트의 종류는 많았다. 어떤 성능테스트를 진행해야 우리의 목적을 이룰 수 있는지 고민해보았다.
우리에게 필요한 성능테스트는?
여러 성능테스트 중 우리에게 가장 적합한 테스트는 Load Test이다. Load Test는 사전에 결정된 Peak지점의 부하 상황에서 시스템의 성능을 검증하는 것으로 Peak Hour Traffic을 감당할 수 있는지 확인하는 것이라고 한다. 우리서비스에 가장 많은 트래픽이 걸렸을때 부하를 지속적으로 주고 HikariCP의 maxPoolSize를 튜닝해 언제가 가장 최적값인지 알아보자.
성능테스트에 사용할 도구
성능테스트에 사용할 도구를 찾아보았다. 생각보다 성능테스트용 도구가 많더라.
우리는 JMeter, nGrinder, k6 중 하나를 선택하기로 했다.
JMeter
무료이고 많은 플러그인이 존재한다. 하지만 러닝커브가 높다는 단점이 있다.
nGrinder
무료이고 groovy로 스크립트를 짤 수 있다. java와 문법이 비슷해 스크립트 짜기가 쉽다. 시각화도 나름 잘되어 있다.
k6
스크립트가 JS로 짜여져있다. JS에 익숙하지 않은 팀원(특히 성능테스트를 수행할 백엔드 팀원)이 많아 사용이 꺼려졌다. 무엇보다 시각화를 하려면 유료 서비스를 사용하거나 CLI로 쓰고 그라파나와 결합해야 한다.
결론
따라서 무료이면서 시각화도 나름 잘 되어있고 무엇보다도 java와 문법이 비슷한 groovy로 스크립트를 작성할 수 있는 nGrinder를 이용해 성능테스트를 하기로 결론지었다.
nGrinder 설치
이제 성능테스트에 필요한 nGrinder를 설치해보자.
nGrinder를 실행하기 위해선 자바가 선행으로 설치되어야 한다.
아래 사이트에 접속해서 ngrinder-controller-{version}.war 를 다운받는다.
nGrinder설치
다운로드가 완료되면, war파일을 터미너롤 실행해준다. 포트번호는 적당한 것을 사용하면 된다.
java -jar ngrinder-controller-{version}.war --port=8300
브라우저에서 localhost:8300으로 접속하자

위와 같은 로그인페이지가 뜨면 성공이다.
admin/admin으로 로그인하자.
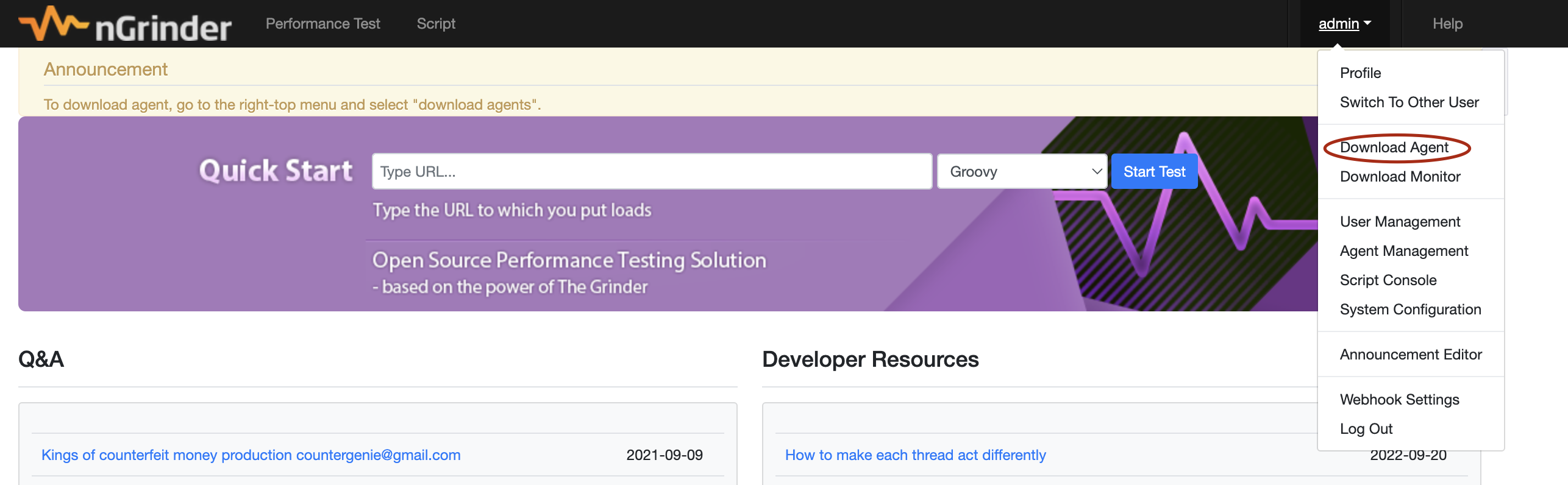
로그인에 성공하면 우측 상단에 admin이 있다. 클릭하고 Download Agent를 눌러 에이전트를 설치하자.
설치한 에이전트의 압축을 풀어주자.
tar -xvf ngrinder-agent-{version}-localhost.tar
압축이 풀린 에이전트 폴더로 이동 후 에이전트를 실행하자.
cd ngrinder-agent
./run_agent.sh
실행이 완료되었으면 에이전트 관리 탭으로 넘어가 확인해 볼 수 있다.
성능테스트를 위한 환경 세팅
HikariCP 최적 maxPoolSize를 구하기 위해 테스트를 위한 EC2 2개를 새로 띄웠다.
1개는 WAS를 위한 EC2, 다른 1개는 DB를 위한 EC2이다. nGrinder는 local에서 실행한다.
EC2는 t4g micro, 로컬은 MAC m1 air RAM 8GB이다.
테스트용 WAS 서버 세팅
테스트 WAS에 CI/CD는 모두 수동으로 진행했다.
kill -15 $(lsof -t -i:8080) || true
rm -r -f ~/2022-sokdak
echo "######기존 레포지토리 삭제 완료######"
mkdir ~/2022-sokdak
echo "######디렉토리 생성 완료######"
git clone -b search-qa --single-branch https://github.com/woowacourse-teams/2022-sokdak.git
mv 2022-sokdak ~/
echo "######깃허브 클론 완료######"
cd ~/2022-sokdak/backend/sokdak/
./gradlew bootJar
cd ~/sokdak
echo "빌드완료"
mv ../2022-sokdak/backend/sokdak/build/libs/sokdak-0.0.1-SNAPSHOT.jar ~/sokdak
echo "재배포"profiles.active는 dev로 설정했다. logging설정을 dev서버와 동일하게 가져가기 위함이다.
sudo kill -15 $(lsof -t -i:8080) || true
echo "기존 서버 중지"
BUILD_ID=dontKillMe nohup java -Dspring.config.location=/home/ubuntu/sokdak/application-perf.yml -Dspring.profiles.active=dev -Djasypt.encryptor.password=sokdakpassword1! -Duser.timezone=Asia/Seoul -jar *.jar > sudo ./nohup.out 2>&1 &
echo "서버 재실행"DB 서버 세팅
DB는 실제 운영/개발 서버와 동일하게 MySQL을 이용했다. 그리고 테이블과 인덱스를 모두 동일하게 설정해주었다.
MySQL를 설치하는 방법은 아래 포스팅에 정리했다.
MySQL설치
성능테스트를 위한 사전작업
성능테스트를 시작하기 전에 거쳐야 할 사전작업들이 있다.(몰랐다. 사실 성능테스트를 거의 다 진행했는데 이걸 늦게 알아서 다시해야했다ㅜㅜ).
사전작업을 먼저 한 후 성능테스트를 진행하도록 하자. 그래야 정확한 결과를 얻을 수 있다.
Tomcat thread 개수 설정
Tomcat thread는 접근하는 request들에 대해 thread를 할당하여 작업을 수행하도록 해준다. 이런 tomcat thread의 최적 개수를 먼저 구하는 것이 최적의 HikariCP maxPoolSize를 구하는 사전 작업이 되어야 할 것이다.
다행히 팀원들이 이전 스프린트때 최적의 Tomcat thread 개수를 찾아주었다.
따라서 Tomcat thread개수는 팀원들이 찾은 10으로 고정하도록 하겠다.
HikariCP 성능테스트는 TPS만 보면 된다?
HikariCP 성능테스트를 왜 할까? 최적의 maxPoolSize를 찾기 위함이다. 왜 최적의 maxPoolSize를 찾을까? 사용자경험을 최상으로 끌어올리기 위함이다. 그럴려면 비싼 돈 주고 구매한(빌린) 하드웨어 자원을 잘 사용해야 하지 않을까? 이런 관점에서 우린 TPS 뿐만 아니라 WAS의 cpu 점유율 또한 모니터링해야 할 것이다. 따라서 팀원들이 구축해놓은 프로메테우스와 그라파나를 이용해 cpu도 모니터링하자.
안타깝게도 DB서버는 public ip가 열려있지 않다. DB서버는 직접 접근해 cpu사용량을 확인하도록 하자.
InnoDB의 buffer pool
InnoDb엔 응답속도를 개선하기 위해 buffer pool이 있다. 자주 사용하는 데이터를 캐싱하는 것인데, 정확한 성능테스트를 하기 위해선 이것 역시 고려해야 한다. buffer pool을 고려한 테스트를 진행하기 위해 2가지 방법을 생각해보았다.
첫번째는 warm up 테스트를 진행한 후 본 테스트를 진행하는 것이다. warm up 테스트로 buffer pool에 데이터를 로딩한 후 본 테스트를 진행한다면 좀 더 정확한 결과를 얻을 수 있다.
두번째는 항상 같은 api의 동일 요청이 아닌 같은 api의 랜덤 요청을 보내는 것이다. 예를들어 특정 게시글을 조회한다면 항상 같은 글이 아닌 랜덤한 글을 조회해오는 것이다.
성능테스트를 위한 API 선정
이제 어떤 api를 통해 성능테스트를 진행할 건지 정해보자. 우리의 서비스
속닥속닥은 커뮤니티이다. 커뮤니티 사이트에서 가장 많이 일어나는 요청은 글 목록 조회이다. 실제로 제니퍼 프론트로 확인한 속닥속닥 서비스에서 가장 많이 사용되는 api 역시 글 목록 조회 기능이였다. 따라서 우선 글 목록 조회 api를 통해 성능테스트를 진행해보기로 했다.
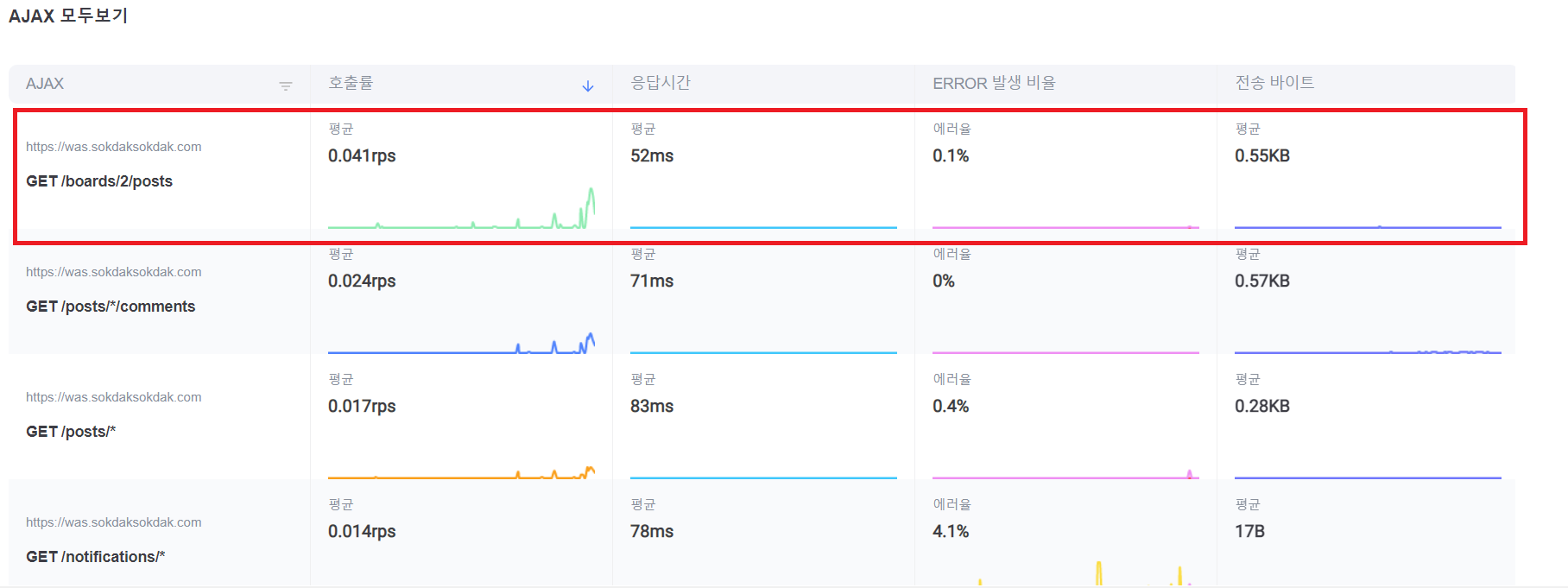
성능 테스트를 위한 더미데이터 추가
테스트를 하기 위해서 DB에 더미데이터를 추가해주어야 한다. 우선 글 목록 찾기 기능을 수행하면 어떤 쿼리가 나가는지 확인한 후 어떤 데이터를 넣을지 알아보자.
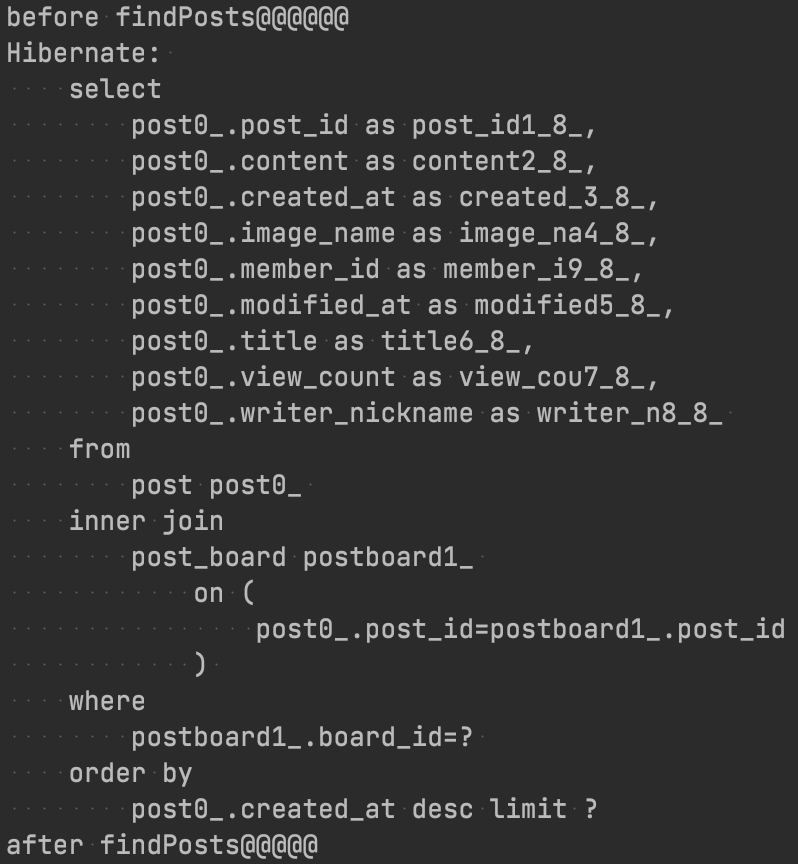
게시글에 해당하는 Post테이블과 게시글이 어떤 게시판에 속해있는지 알고있는 PostBoard테이블이 사용된다. 따라서 두 테이블에 데이터를 넣어주면 된다.
데이터를 얼마나 넣어야 할까? 성능테스트로 이룰려는 우리의 목적은 Peak time에서 가장 적절한 connection pool 개수 찾기이다. 따라서 실제 서비스와 비슷한 환경을 구축해야 한다고 생각했다. 현재 속닥속닥 서비스엔 약 1000개 정도의 게시글이 존재한다. 따라서 넉넉잡아 2000개의 게시글을 더미데이터로 추가하도록 하겠다.
⚠️ auto_increment를 설정한 테이블에 데이터를 프로시저로 넣을 땐 ID가 알맞게 잘 들어갔는지 확인해야 한다.
ALTER TABLE post AUTO_INCREMENT = 1;
DELIMITER $$
DROP PROCEDURE IF EXISTS postInsert$$
CREATE PROCEDURE postInsert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 2000 DO
INSERT INTO post(content, member_id, created_at, modified_at, title, writer_nickname)
VALUES(concat('message', 1), 1, Now(), Now(), concat('title', i), "테스트");
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;ALTER TABLE post_board AUTO_INCREMENT = 1;
DELIMITER $$
DROP PROCEDURE IF EXISTS postBoardInsert$$
CREATE PROCEDURE postBoardInsert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 2000 DO
INSERT INTO post_board(created_at, board_id, post_id)
VALUES(NOW(), 2, i);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;성능 테스트를 위한 스크립트 작성
이제 성능테스트를 위한 nGrinder의 스크립트를 작성해보자. 글 목록 조회 api를 성능테스트에 사용하기로 했다. 2000개의 글을 더미데이터로 넣었고, 한 페이지당 조회되는 글은 10개라 하면 총 200페이지가 존재하게 된다. 어떤 페이지를 api요청해야 할까? 매번 같은 페이지를 요청한다면 캐싱때문에 제대로된 결과를 얻지 못할 것이다. 모든 페이지를 랜덤하게 요청한다면 실제 서비스에 들어오는 글 목록 조회 요청과는 다른 시나리오가 될 것이다. 왜냐하면 대부분의 사용자들은 최신글을 많이 조회하지 오래된 글은 거의 조회하지 않기 떄문이다. 따라서 최신페이지가 자주 조회되는 랜덤 글 목록 조회 요청을 보내야 할 것이다. 스크립트에서 Random함수를 잘 사용해 최신 페이지가 자주 조회되는 글 목록 조회 요청을 만들어보자.
0~10페이지에 가장 많은 우선순위를 주고, 11~40페이지, 41~100페이지, 그리고 101~200페이지는 가장 적은 우선순위로 조회되도록 스크립트를 구성했다.
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import org.ngrinder.http.cookie.Cookie
import org.ngrinder.http.cookie.CookieManager
/**
* A simple example using the HTTP plugin that shows the retrieval of a single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author admin
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static Map<String, String> headers = [:]
public static Map<String, Object> params = [:]
public static List<Cookie> cookies = []
public static int count = 0;
public static Random random = new Random();
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test = new GTest(1, "54.180.199.238")
request = new HTTPRequest()
grinder.logger.info("before process.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("before thread.")
}
@Before
public void before() {
request.setHeaders(headers)
CookieManager.addCookies(cookies)
grinder.logger.info("before. init headers and cookies")
}
@Test
public void test() {
int randomFlag1 = random.ints(0,1).findFirst().getAsInt();
int randomFlag2_1 = random.ints(0,1).findFirst().getAsInt();
int randomFlag2_2 = random.ints(0,1).findFirst().getAsInt();
int randomFlag3_1 = random.ints(0,1).findFirst().getAsInt();
int randomFlag3_2 = random.ints(0,1).findFirst().getAsInt();
int randomFlag3_3 = random.ints(0,1).findFirst().getAsInt();
int randomFlag3_4 = random.ints(0,1).findFirst().getAsInt();
int randompage = random.ints(1,10).findFirst().getAsInt() +
random.ints(0,40).findFirst().getAsInt()*randomFlag1 +
random.ints(0,50).findFirst().getAsInt()*randomFlag2_1*randomFlag2_2 +
random.ints(0,100).findFirst().getAsInt()*randomFlag3_1*randomFlag3_2*randomFlag3_3*randomFlag3_4;
HTTPResponse response = request.GET("http://54.180.199.238:8080/boards/2/posts?size=10&page="+randompage, params)
if (response.statusCode == 301 || response.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", response.statusCode)
} else if (response.statusCode == 500) {
grinder.logger.warn("code 500!!! : {}.", count)
count += 1;
} else {
grinder.logger.warn("code 200!!! : {}.", count)
assertThat(response.statusCode, is(200))
}
}
}성능 테스트 시작
이제 성능테스트를 시작해보자. 우선 vUser의 개수를 결정해야 한다. 우아한테크코스 4기의 총 인원은 약 150명이다. 이 중 대략 1/3 정도가 사용한다고 가정하면 50명의 실제 유저가 존재한다. 우리 서비스는 최근 지원자들을 위한 공간을 마련했다. 지원자 역시 우아한테크코스 실 사용자만큼 사용한다 가정하면 대략 100명의 실 사용자가 존재하는 것을 알 수 있다. 실제로 피크타임때 최고 동시접속자 수가 80을 달성한 적이 있었다.
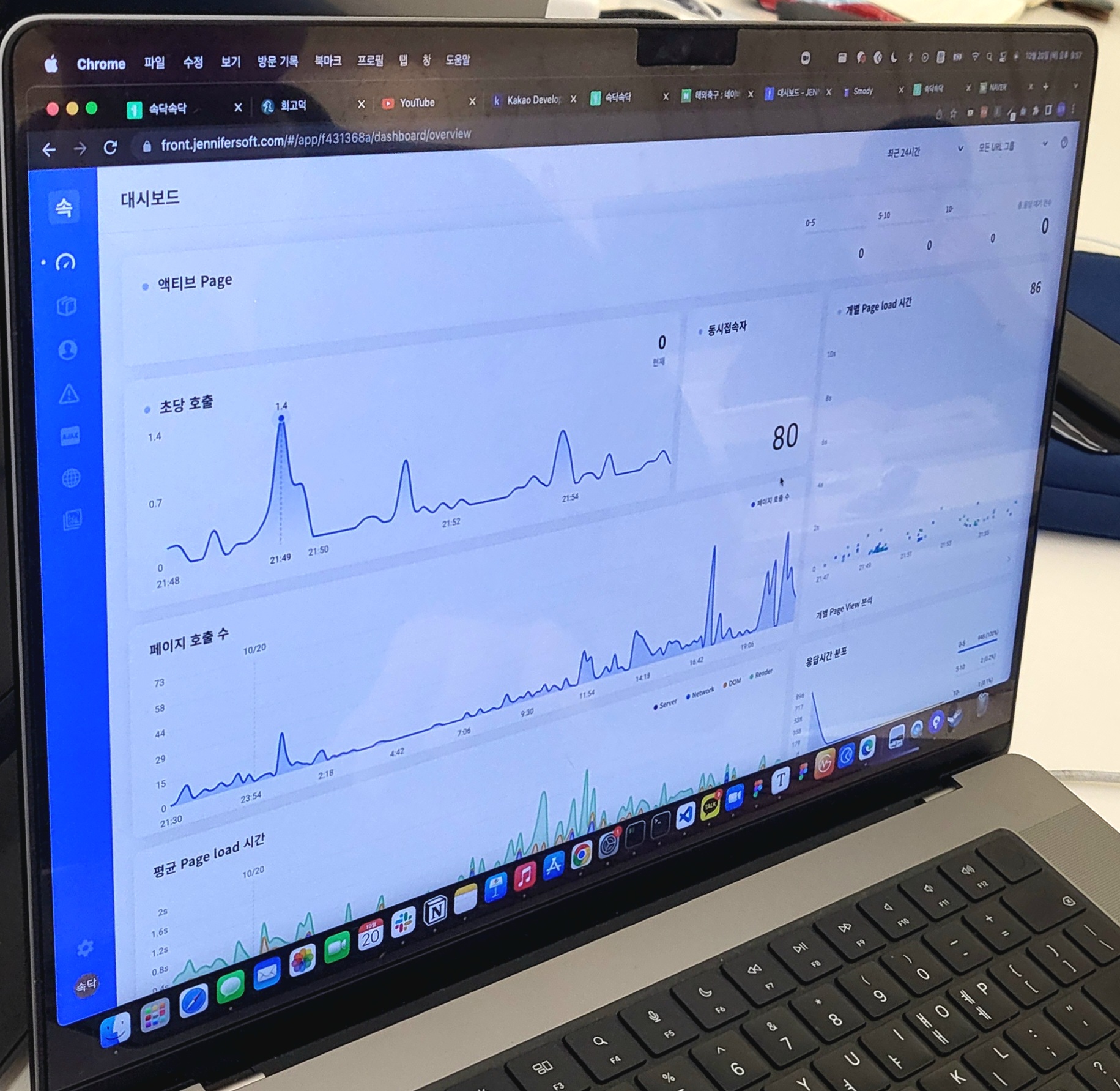
따라서 vUser는 100명에 근접한 99명으로 설정했다.(100명 설정하면 99명이 되더라..)
이제 DB warm up 테스트를 돌린 후 본 테스트를 진행하자. 모든 본 테스트 이전엔 똑같은 테스트를 warm up으로 돌려주었다.
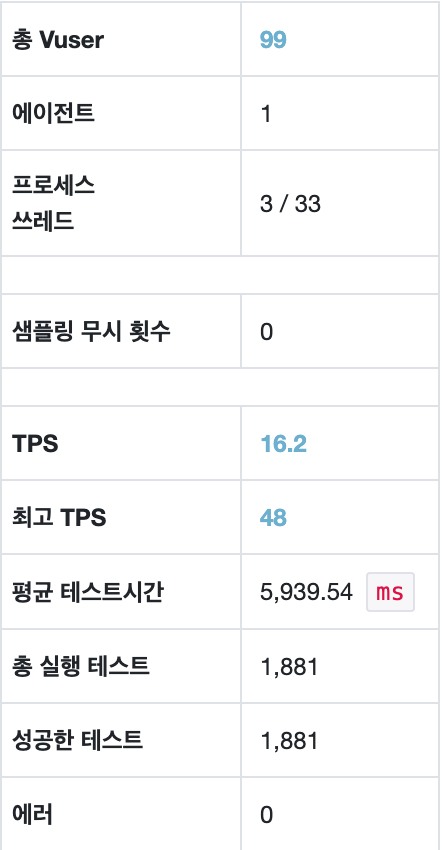
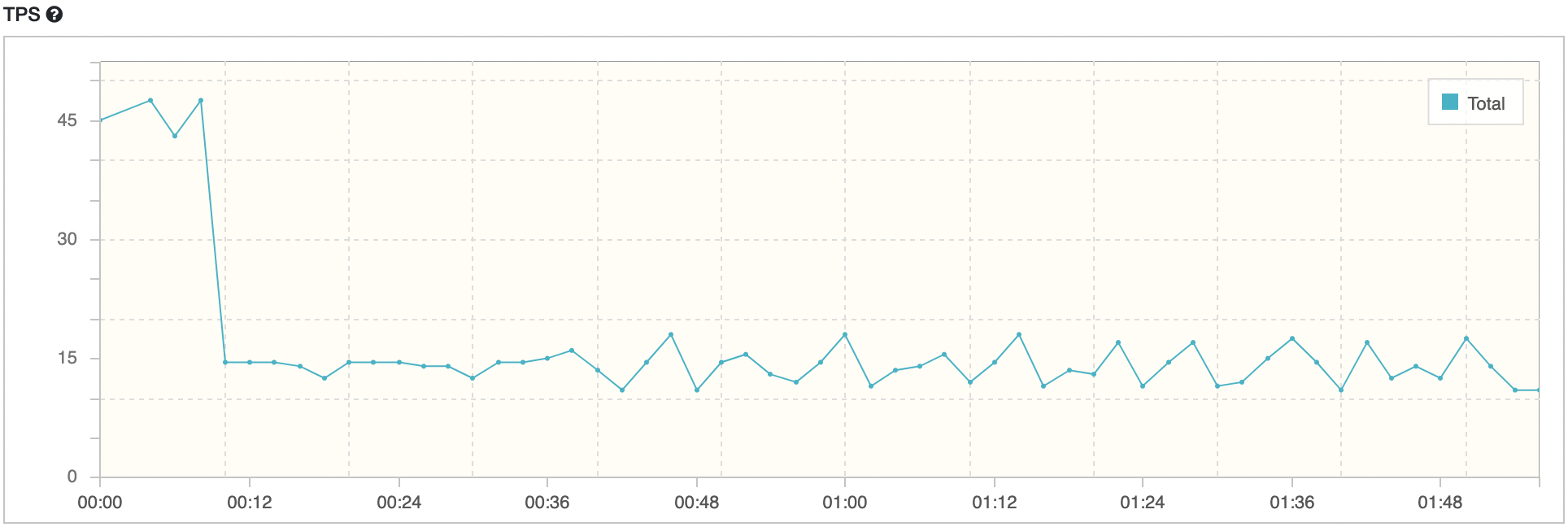
maxPoolSize = 1, Threads = 10
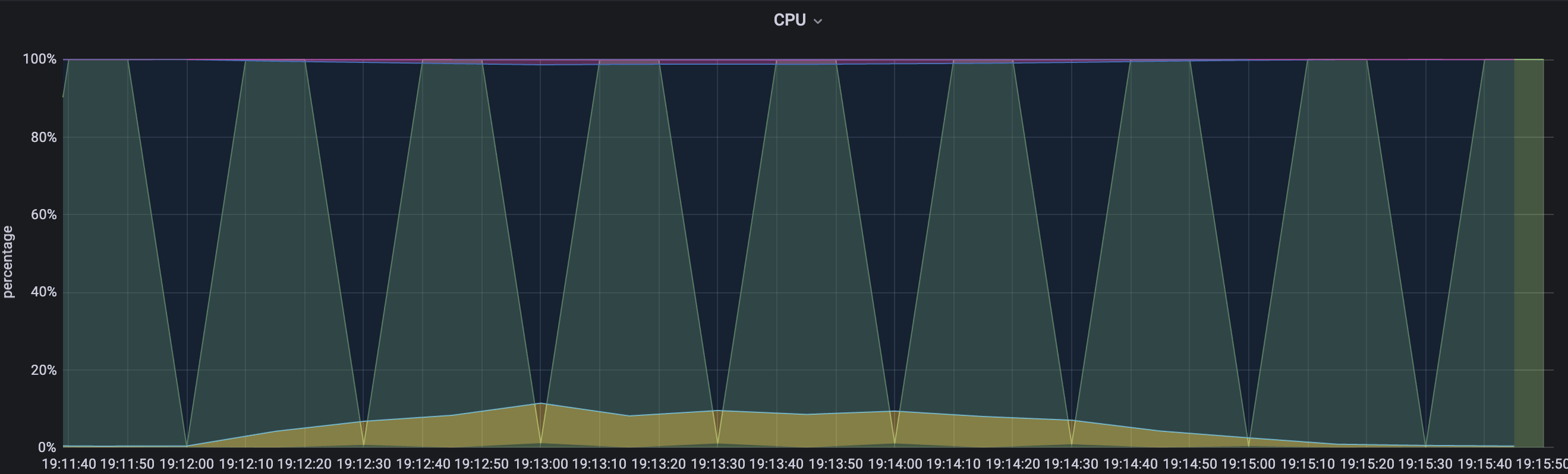
평균 TPS는 16.2, WAS cpu는 10-20%, DB서버 cpu 부하는 약 0.13 정도의 수치가 나타났다.
한 테스트만 보고는 어떻게 해야할지 판단이 서질 않는다. Thread개수 만큼 maxPoolSize를 늘려보자. 테스트하는 요청은 db connection을 1개만 맺기 때문에 성능 향상을 기대해 볼 수 있다.
nGrinder 결과
WAS cpu 모니터링
DB서버 cpu 모니터링

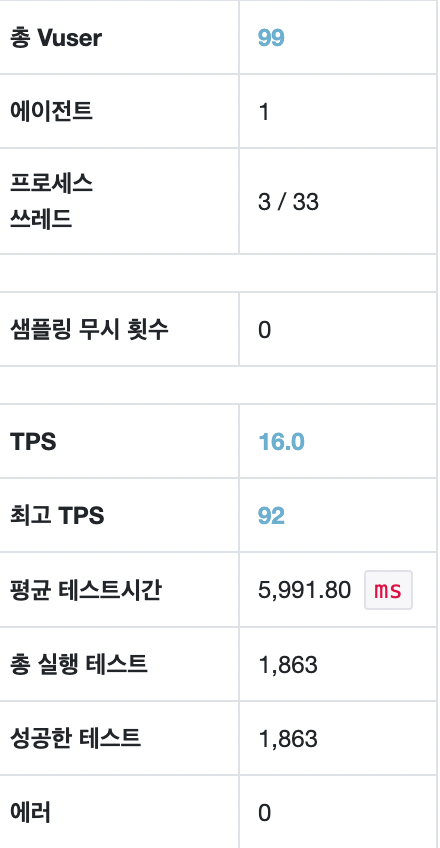
maxPoolSize = 10, Threads = 10
평균 TPS는 16, WAS cpu는 10-20%, DB서버 cpu 부하는 약 0.40 정도의 수치가 나타났다.
TPS와 WAS cpu 부하는 동일하고, DB서버의 cpu 부하만 증가했다. 아무래도 Thread 개수는 같지만 connection이 증가했기 때문에 DB 서버 cpu 부하가 증가한 거 같다. 하지만 TPS는 변함이 없다. 조금 이해하기 어려운 결과가 나왔다.
nGrinder 결과
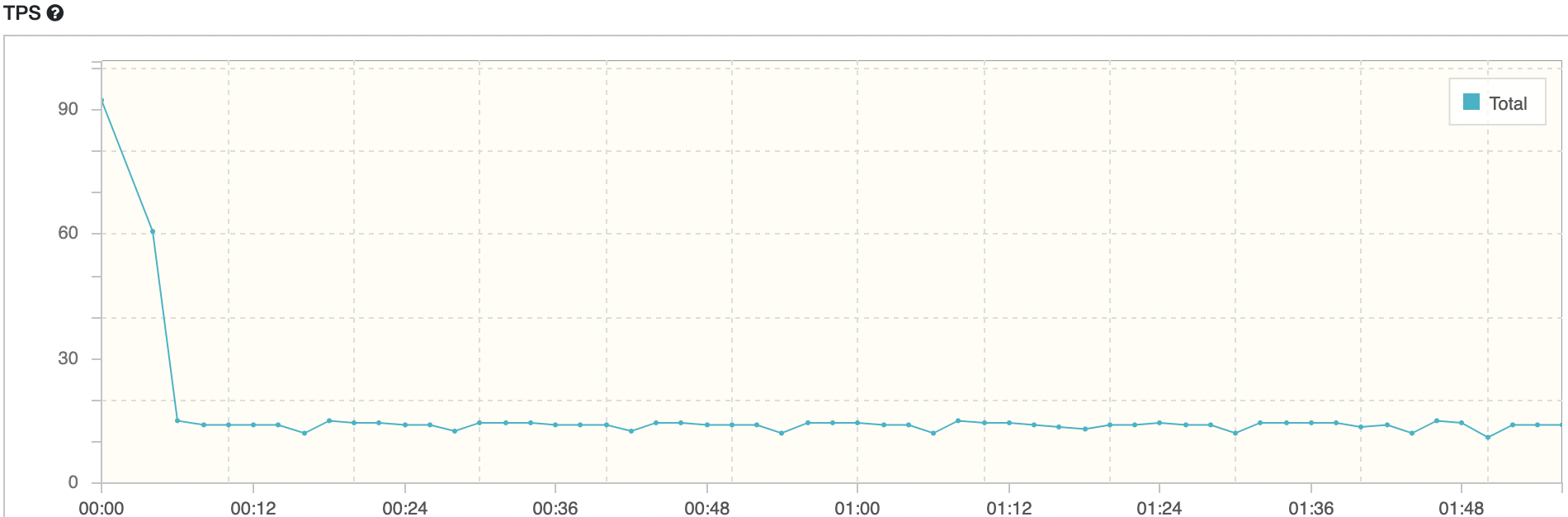
WAS cpu 모니터링
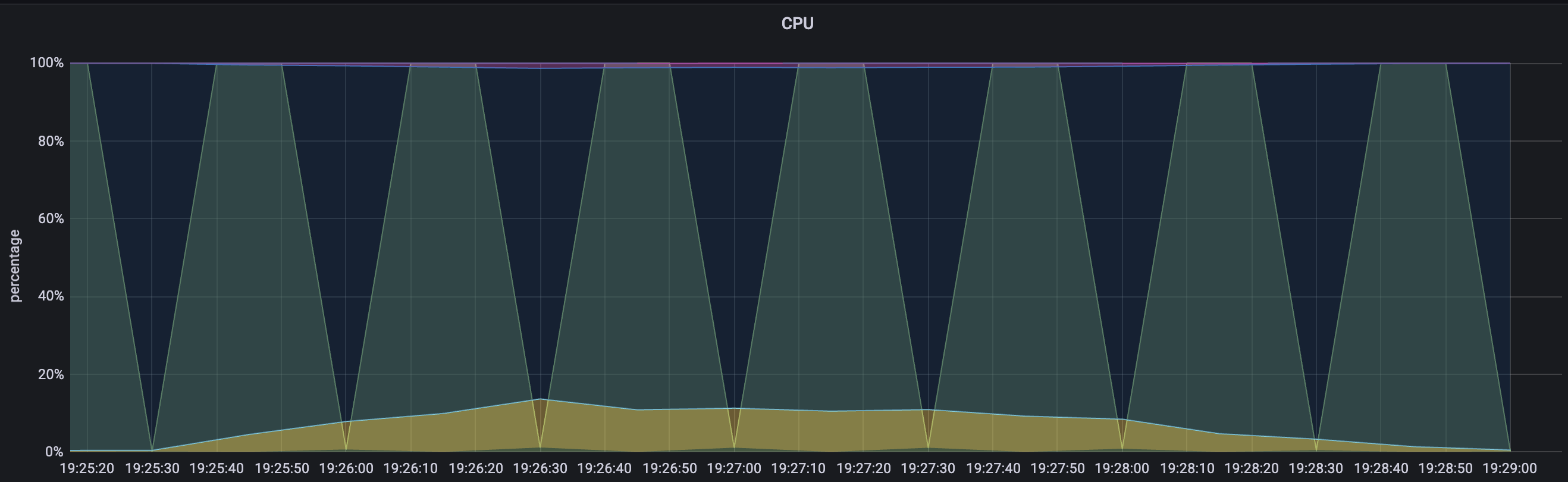
DB서버 cpu 모니터링

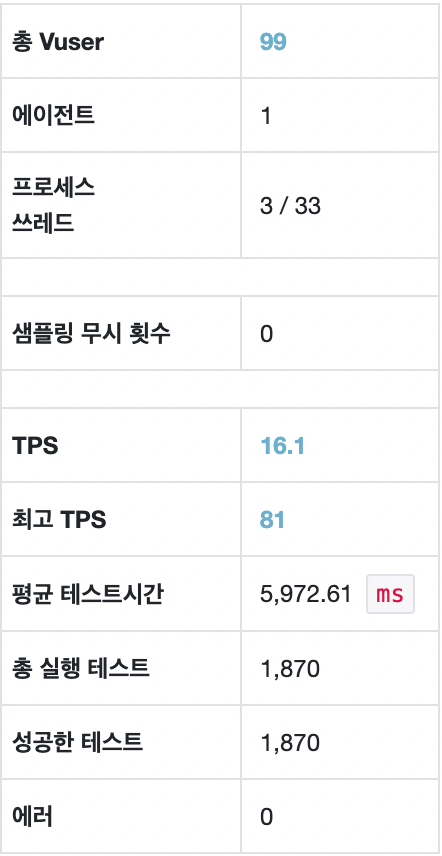
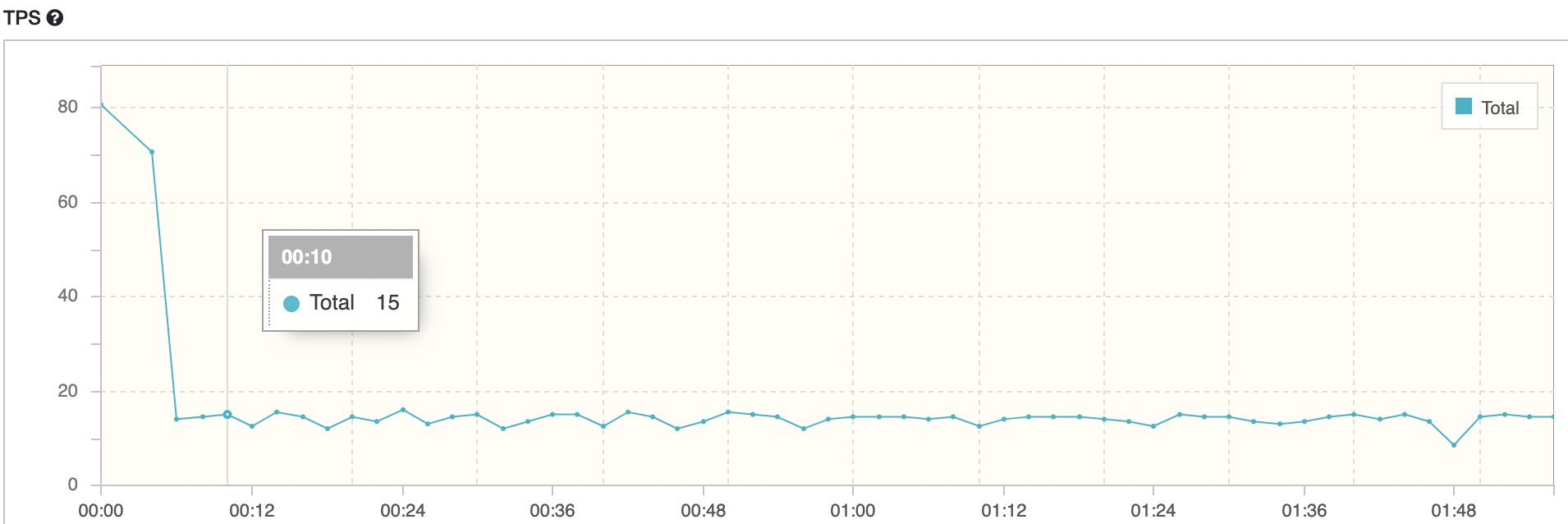
maxPoolSize = 5, Threads = 10
하나의 요청 당 DB connection이 1개만 맺어지는 api를 사용하기 때문에 Thread 이상의 connection 개수는 무의미하다 생각했다. 그래서 maxPoolSize를 5로 낮춰 다시 테스트해보았다.
평균 TPS는 16.1, WAS cpu는 약 20%, DB서버 cpu 부하는 약 0.20 정도의 수치가 나타났다.
TPS는 여전히 변화가 없다. DB서버 cpu 사용량은 maxPoolSize에 따라 나름 정직하게 변화한다. 도대체 왜 TPS에 변화가 없을까? 고정시켰던 Thread 개수를 증가시켜 다시 테스트를 해보아야 겠다.
nGrinder 결과
WAS cpu 모니터링
DB서버 cpu 모니터링

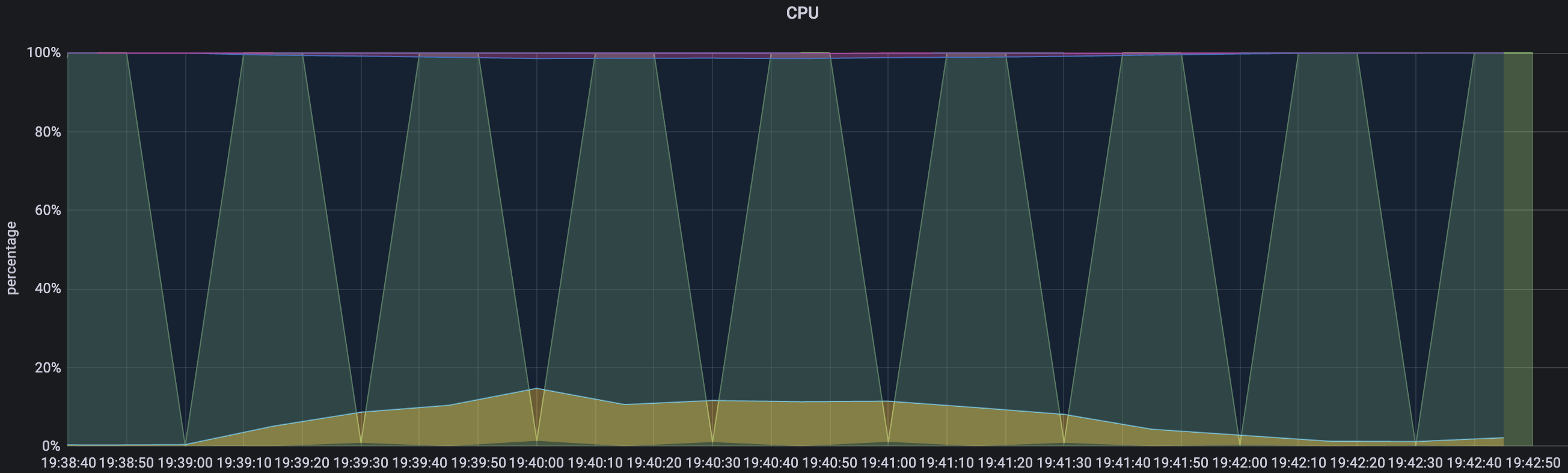
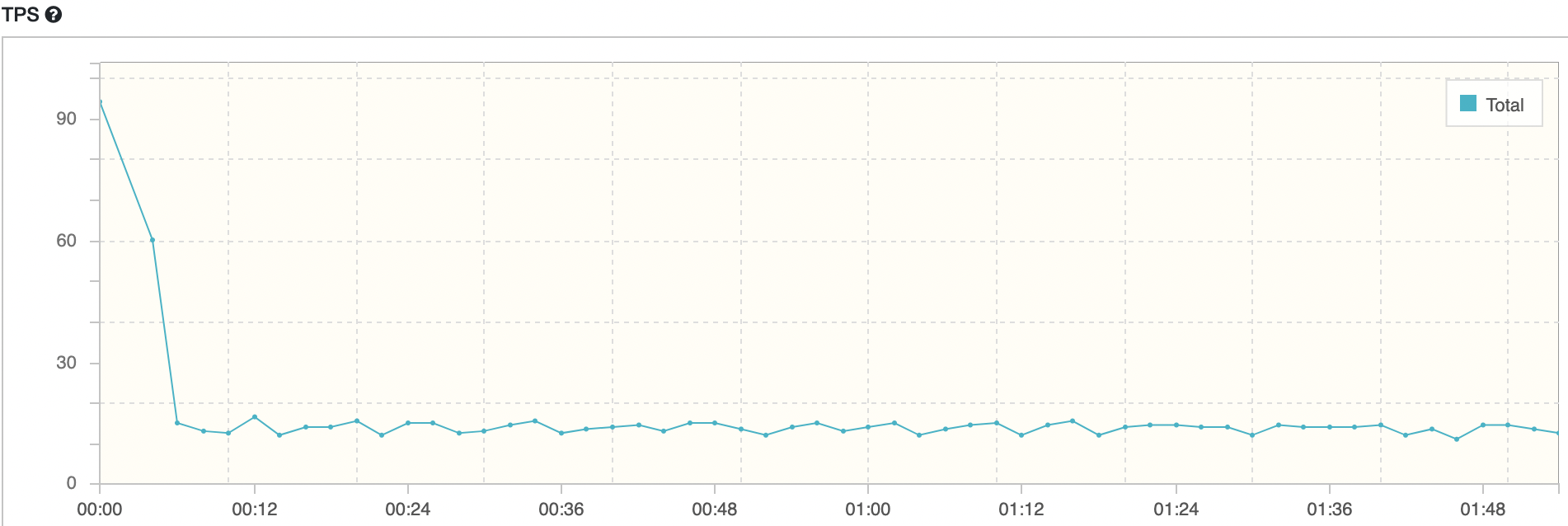
maxPoolSize = 20, Threads = 20
스레드의 개수가 늘어나면 WAS의 부하도 늘어나고, DB서버의 부하도 자연스럽게 늘어날 것을 기대했다. 따라서 maxPoolSize와 Thread개수를 20으로 설정하고 테스트해보았다.
평균 TPS는 16, WAS cpu는 20-22%, DB서버 cpu 부하는 약 0.66 정도의 수치가 나타났다.
TPS는 여전히 변화가 없다. 결과가 예상과 많이 달랐다. cpu부하가 적으니 스레드를 더 늘릴 수 있고, 스레드와 connection개수를 늘렸으니 TPS도 자연스레 높아질 줄 알았다.
nGrinder 결과
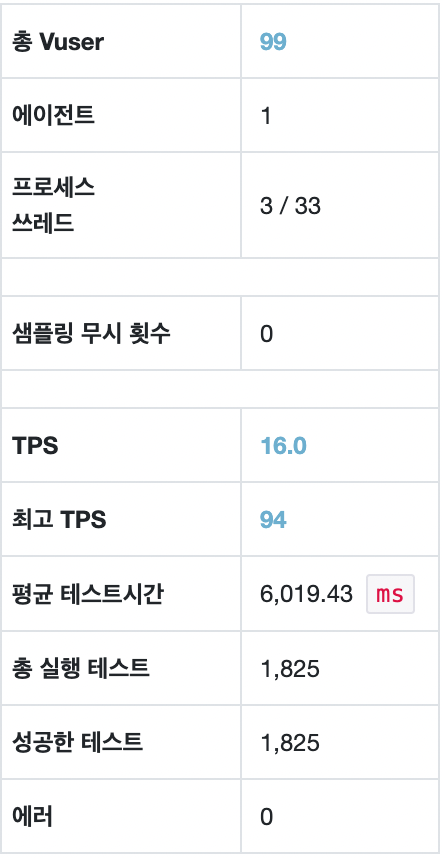
WAS cpu 모니터링
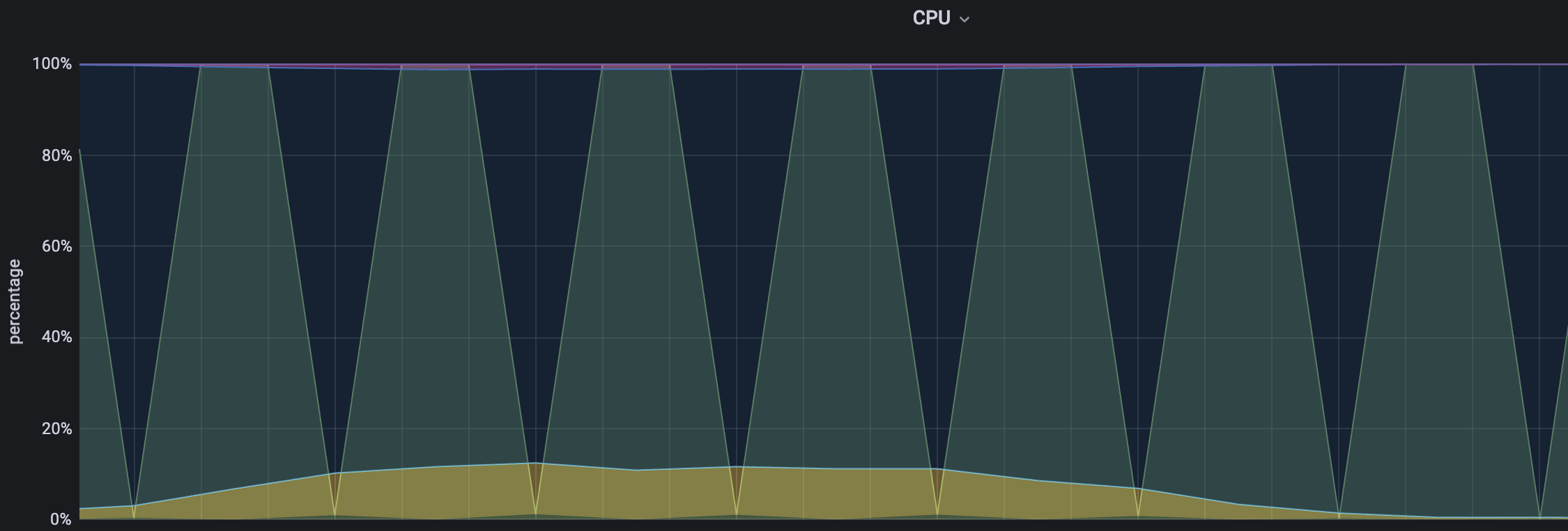
DB서버 cpu 모니터링

중간점검
도대체 왜 TPS가 개선되지 않는것일까? 한 가지 추측을 할 수 있었다. WAS의 스펙은 2core이다. 2core로 실제 동시에 실행되는 스레드는 2개뿐이다. 스레드를 10개 만들던 20개 만들던 동시에 일하는 스레드는 2개뿐이니 어느정도 이상의 스레드 개수에선 TPS가 동일할 수 밖에 없다는 것이다. 그렇다면 우리는 어떻게 최적의 값을 구해야 할까? Thread 개수를 낮추긴 부담스럽다. 이전에 팀원들이 성능테스트를 통해 구한 최적 스레드 수가 10이기 때문이다. 또한 스레드는 잠잘 수 있기 때문에 core의 개수보다 좀 더 넉넉한 스레드 개수가 적절하다고 생각한다. Thread를 10으로 고정하고 나면 딱 한 가지 지표를 통해 최적 maxPoolSize 개수를 도출해 낼 수 있다. 바로 TPS 그래프의 일관성이다. 평균 TPS가 같더라도 항상 일정한 TPS 수치를 내는 것과, 많이 튀는 TPS수치를 내는 것은 사용자 경험 측면에서 차이가 있을 것이다. TPS가 튄다는 것은 특정 시간에 따라 사용자 요청이 잘되었다 안되었다 한다는 것을 의미한다. 그것보단 항상 동일한 성능의 응답을 내는 것이 더 좋을것이다.
Thread의 수가 10일때 테스트한 모든 경우의 TPS그래프만 다시 가져와서 보자. maxPoolSize가 10일때가 가장 고른 TPS 일관성을 가진다. 따라서 Thread가 10개일땐 maxPoolSize를 10으로 설정하는게 가장 적합해 보인다.
maxPoolSize = 1, Thread = 10
maxPoolSize = 10, Thread = 10(선정)
maxPoolSize = 5, Thread = 10
추가) 우형 기술블로그 참고
https://techblog.woowahan.com/2664/
https://techblog.woowahan.com/2663/
우형 기술블로그에서 좋은 글을 발견했다. HikariCP에서 Deadlock이 발생할 수 있기 때문에 특정 조건의 경우엔 공식을 이용해 Deadlock이 발생하지 않는 HikariCP maxPoolSize를 설정해야 한다는 것이다.
어떤 조건에서 Deadlock이 발생한다는 것일까?
내가 이해한 HikariCP Deadlock 발생 조건
- connection을 동시에 얻으려는 Thread 개수가 connection의 maxPoolSize보다 많음
- 한 트랜잭션에서 2개의 connection을 사용함
우형 기술블로그를 참고해 왜 이런 조건일때 Deadlock이 발생하는지 그림으로 그려보고 이해해보자.
Thread개수와 maxPoolSize가 1개로 동일한 경우(1번 조건의 경계값)를 가정해보겠다.
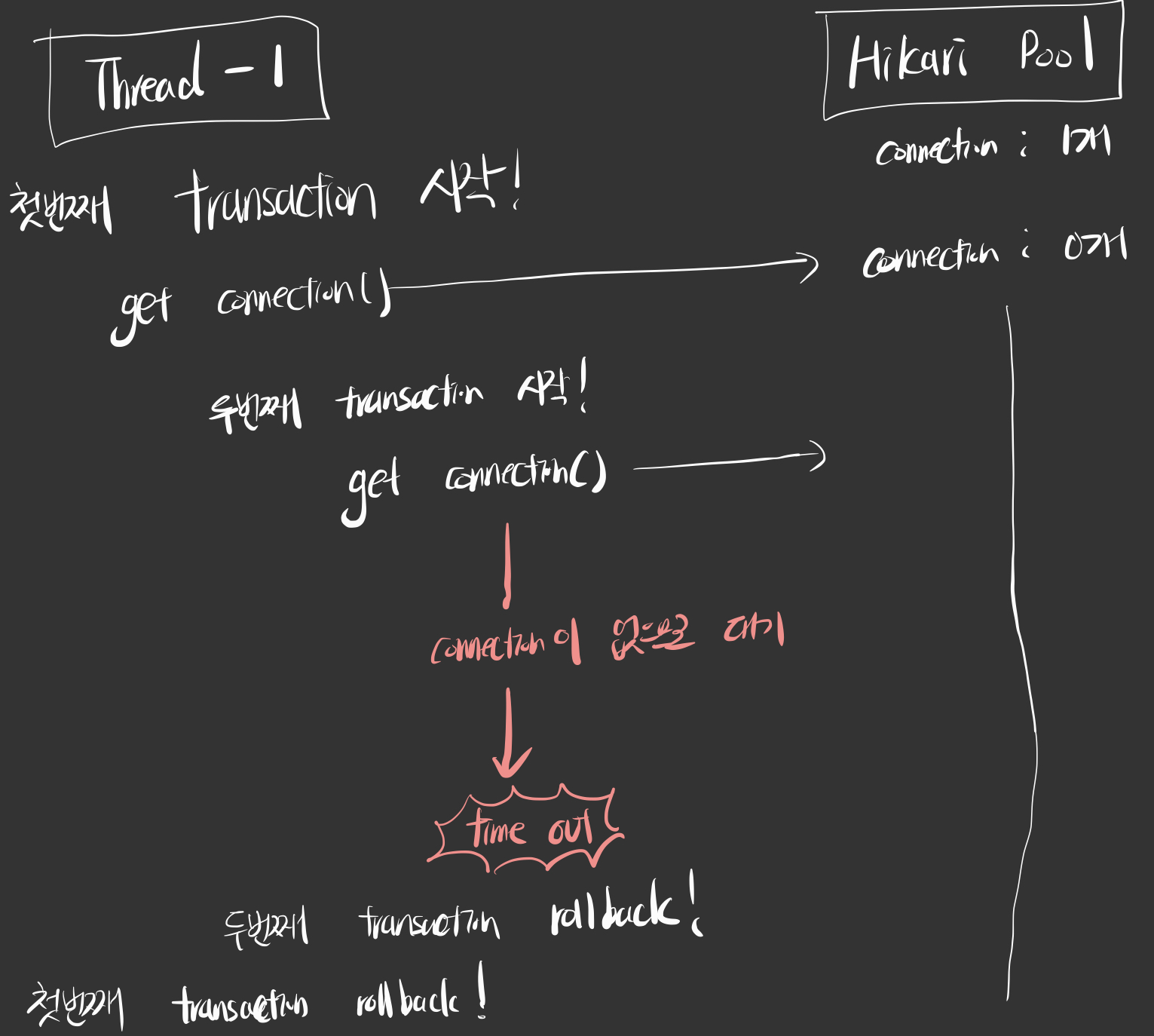
그런데 하나의 트랜잭션에서 connection을 두 번 얻어 올 일이 언제 있을까? 우형 기술블로그에 의하면 @GeneratedValue(strategy = GenerationType.AUTO)를 사용하면 id를 얻기 위해 새로운 connection을 얻게 되어있다 한다.
어라..? 우리 프로젝트에서도 @GeneratedValue를 사용하는데..?
속닥속닥 프로젝트에서도 id를 얻기위해 @GeneratedValue를 사용한다. 물론 우리는 GenerationType.IDENTITY를 사용하는데... 혹시 우리도 문제가 발생하지 않을까?
우형 기술블로그에 의하면 GenerationType.IDENTITY를 사용하고 MySQL id column에 auto_increment를 사용하면 1개의 connection으로 insert가 가능하다고 한다.
우형 기술블로그를 전적으로 믿지만, 학습목적에서 한번 테스트해보는것도 좋을거 같다. 그리고 직접 눈으로 확인해보는것이 가장 확실한 방법이지 않을까?
@GeneratedValue(strategy = AUTO)일때 Deadlock 확인
우선 @GeneratedValue(strategy = AUTO)일때 deadlock이 발생하는지 확인해보자.
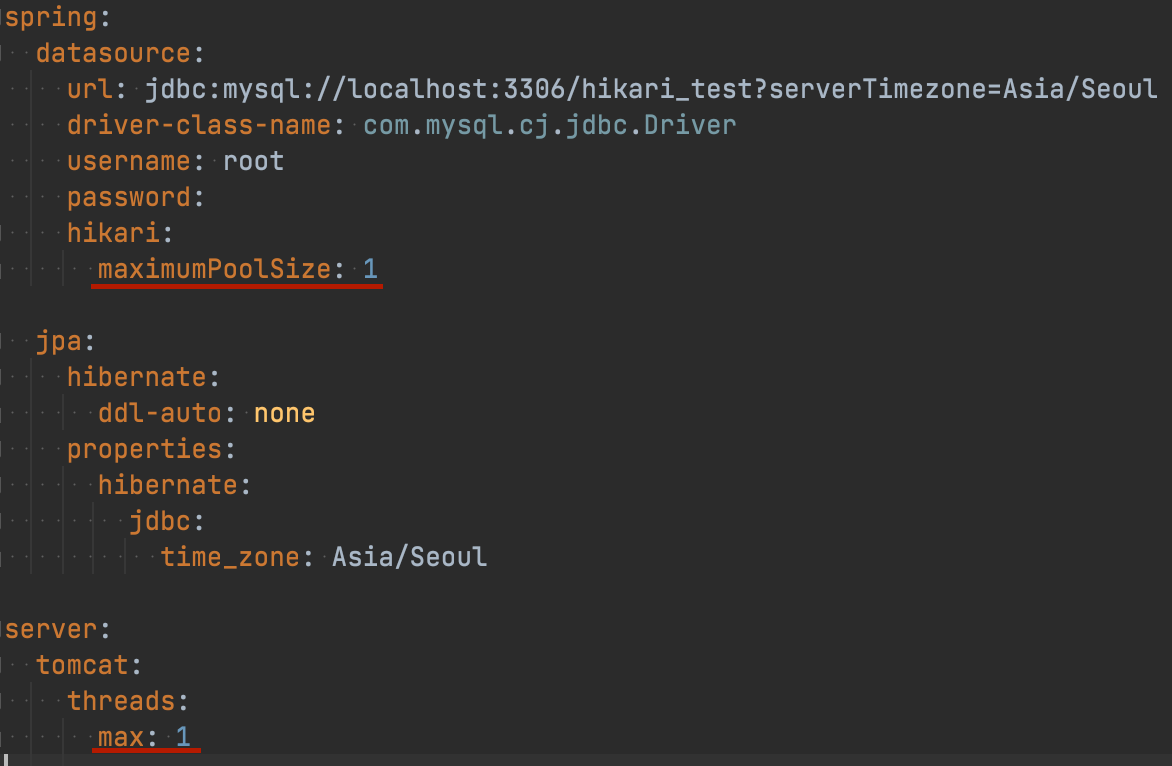
로컬환경에 간단한 코드를 작성하고 로컬db에 접근한 후 테스트해보았다.
HikariCP maxPoolSize는 1, thread 개수도 1로 설정했다.
그리고 간단한 Member엔티티를 만들고,
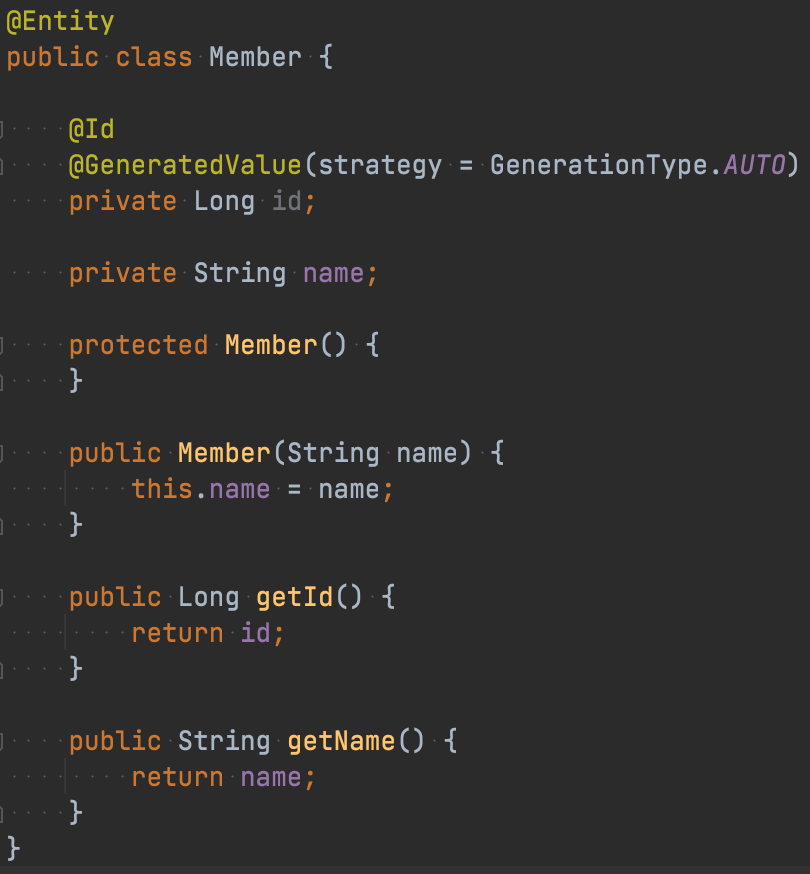
db에도 테이블을 만들어 주었다.
create table member
(
id bigint auto_increment,
name varchar(255),
primary key (id)
);서비스에 @Transactional을 붙히고 엔티티를 저장하는 로직을 테스트해보자.

테스트코드는 다음과 같다.
테스트의 결과로 timeOut이 발생했다는 메시지를 받을 수 있었다. Deadlock이 발생했다고 짐작할 수 있었다.

@GeneratedValue(strategy = IDENTITY)일때 Deadlock 확인
이제 HikariCP에서 Deadlock이 충분히 발생할 수 있다는 것을 알게되었다. 그럼 속닥속닥 프로젝트에서 사용한 @GeneratedValue(strategy = IDENTITY)에서도 Deadlock 가능성이 있는지 확인해보자. 이번에도 HikariCP maxPoolSize는 1, thread 개수도 1로 설정했다.
Member엔티티에서 @GeneratedValue(strategy = IDENTITY)로 변경하고 동일한 테스트를 실행했다.
테스트는 다행히 통과했다. 이로써 @GeneratedValue(strategy = IDENTITY)인 경우 deadlock발생 가능성이 적다는 것을 알게 되었다.

최종 결론
이전 성능테스트에서 Thread가 10개일땐 maxPoolSize가 10이 가장 적합하다는 결론을 내릴 수 있었다. 추후 알게된 HikariCP Deadlock 이슈를 고려해서 최종적으로 maxPoolSize를 11로 결정했다. 그 이유는 비록 우리 프로젝트에서 Deadlock이 걸릴 상황은 없지만, 추후 발생할지도 모르는 Deadlock 문제를 미리 방지하자는 차원이다. 팀원 중 누군가가 @GeneratedValue(strategy = AUTO) 쓸 수도 있지 않을까? 따라서 기존 10개에서 1개를 추가해 deadlock을 방지할 수 있는 maxPoolSize를 사용하기로 결정했다.
참고
https://leezzangmin.tistory.com/42
https://programmer93.tistory.com/74
https://code-lab1.tistory.com/209
https://engineering-skcc.github.io/performancetest/Performance-Testing-Terminologies/
https://velog.io/@injoon2019/%EB%B6%80%ED%95%98%ED%85%8C%EC%8A%A4%ED%8A%B8-z8jb3vvv
