Goal
Multi AZ k8s cluster 환경에서 프로메테우스를 사용한 모니터링 환경을 구성하기 이전에 모니터링, 프로메테우스, k8s 모니터링에 대한 개념을 정리한다.
덧 붙여 무엇을 모니터링하면 좋을지 미리 정리해본다.
Monitoring
쿼리 카운트, 에러 카운트, 처리 시간, 서버의 활성 시간과 같은 시스템에 관련된 정량적 수치를 실시간으로 수집, 처리, 집계, 보여주는 모든 행위
- Signal, Telemetry, Trace 등을 수집하고 집계하는 행위 (Logging 포함)
- 임계점을 넘어가는 상태에 대한 알림 및 조치
ex) DB 디스크 사용량 임계점 초과시 알람 발생 및 통지 -> 스토리지 확장Metrics: 응용 프로그램 및 서비스의 성능과 품질을 측정하는 데 도움이 되는 정량 데이터
- 컨테이너 인프라 환경에서 metric 구분
- system metrics: 파드 같은 오브젝트에서 측정되는 CPU와 메모리 사용량을 나타내는 메트릭
- service metrics: HTTP 상태 코드 같은 서비스 상태를 나타내는 메트릭
Metric 수집 방식의 이해
Push
- 모니터링 주체가 서버에 정보를 보냄
- 수집 서버 정보를 알아야 함. agent에는 반드시 system agent가 설치되야 하고 agent는 중앙에 있는 서버에 metric을 보내야 하기 때문에 서버의 end-point IP를 알아야 한다. metric 정보가 변경될 때 마다 재 배포 해야 한다.
- 버퍼링 메커니즘(queue)
- 구성관리도구(CMDB) 필요
- 예) TICK Stack, Nagios
Pull (prometheus 방식)
- exporters(like agent)
- 보통 수집 서버에 대한 정보를 agent나 서비스들이 알지 못한다. 프로메테우스는 agent가 내부 metric을 노출하고, 프로메테우스 중앙 집중형 컴포넌트가 metric을 수집한 후 DB에 저장한다.
- 중앙집중식 모니터링이지만 agent는 서버에 대한 정보를 모르고 외부에서 exporter나 다른 정보들이 metric을 expose 하는 것
- Service Discovery; k8s같은 오케스트레이션 툴을 통해 리소스에 있는 정보를 다이나믹하게 가져오는 방식
- push 방식도 지원
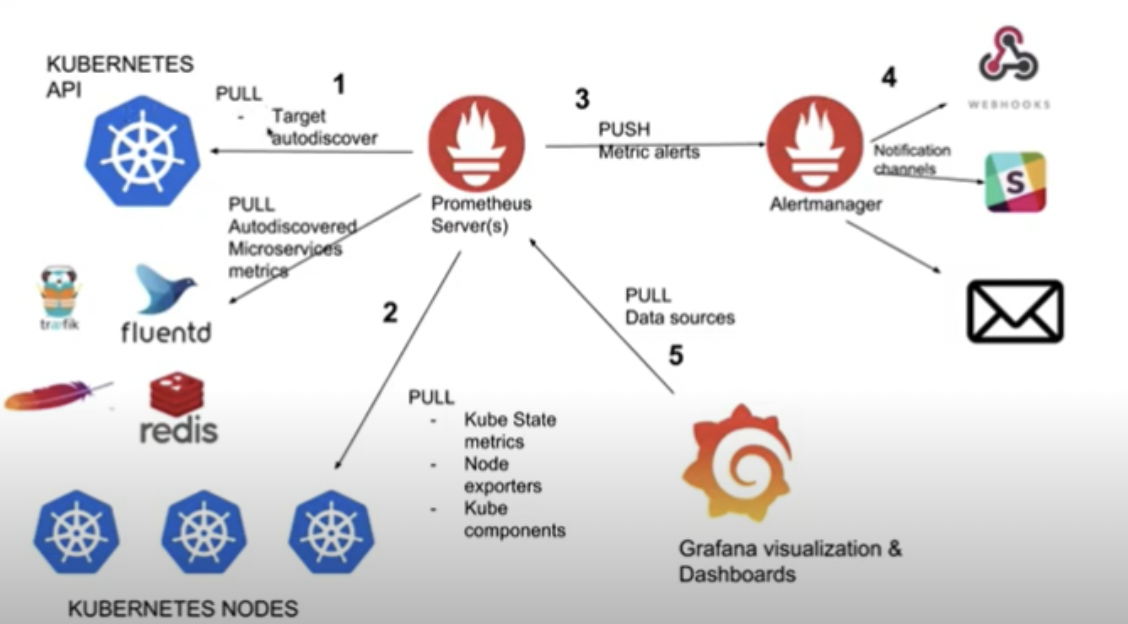
쿠버네티스 모니터링
k8s 모니터링 컨셉
쿠버네티스 노드는 kubelet을 통해 파드를 관리하며, 파드의 CPU나 메모리 같은 메트릭 정보를 수집하기 위해 kubelet에 내장된 cAdvisor를 사용. cAdvisor는 쿠버네티스 클러스터 위에 배포된 여러 컨테이너가 사용하는 메트릭 정보를 수집한 후 이를 가공해서 kubelet에 전달하는 역할.
모니터링 대상
- host(node-exporter)
노드의 CPU, 메모리, 디스크, 네트워크 사용량과 노드 OS와 커널에 대한 모니터링- container(kubelet[cadvisor])
노드에서 가동되는 컨테이너에 대한 정보. CPU, 메모리, 디스크, 네트워크 사용량 등- app
컨테이너안에서 구동되는 개별 애플리케이션의 지표를 모니터링. 애플리케이션의 응답시간, HTTP 에러 빈도 등을 모니터링- kubernetes({etcd <- api} -> kube-state-metrics)
쿠버네티스 자체에 대한 모니터링. 서비스나 POD, 계정 정보 등이 해당
쿠버네티스 모니터링 아키텍쳐
쿠버네티스 모니터링을 쿠버네티스의 컴포넌트가 직접 활용하는 정보와 이보다 많은 정보를 수집해 히스토리/통계 정보를 보여주는 모니터링 시스템 관점으로 나눌 수 있다. 이를 Resource Metrics Pipeline과 Full Metrics Pipeline 으로 나눠서 설명한다.
Resource Metrics Pipeline
쿠버네티스 컴포넌트가 활용하는 메트릭 흐름. 수집된 정보를 kubectl top 명령으로 노출해주고, 스케일링이 설정되어 있다면 오토스케일링에 활용. metrics-server를 통해 수집된 모니터링 정보를 메모리에 저장하고 API 서버를 통해 노출해 kubectl top, scheduler, HPA와 같은 오브젝트에서 사용. 쿠버네티스의 일부 기능은 Metric Server의 정보를 사용. 다만, 순간의 정보를 가지고 있고 장시간 저장하지도 않기 때문에 Full Metrics Pipeline이 필요하다.Full Metrics Pipeline
다양한 메트릭을 수집하고, 이를 스토리지에 저장. 프로메테우스를 통해 서비스 디스커버리, 메트릭 수집(Retrieval) 및 시계열 데이터베이스(TSDB)를 통한 저장, 쿼리 엔진을 통한 PromQL 사용과 Alertmanager를 통한 통보가 가능.
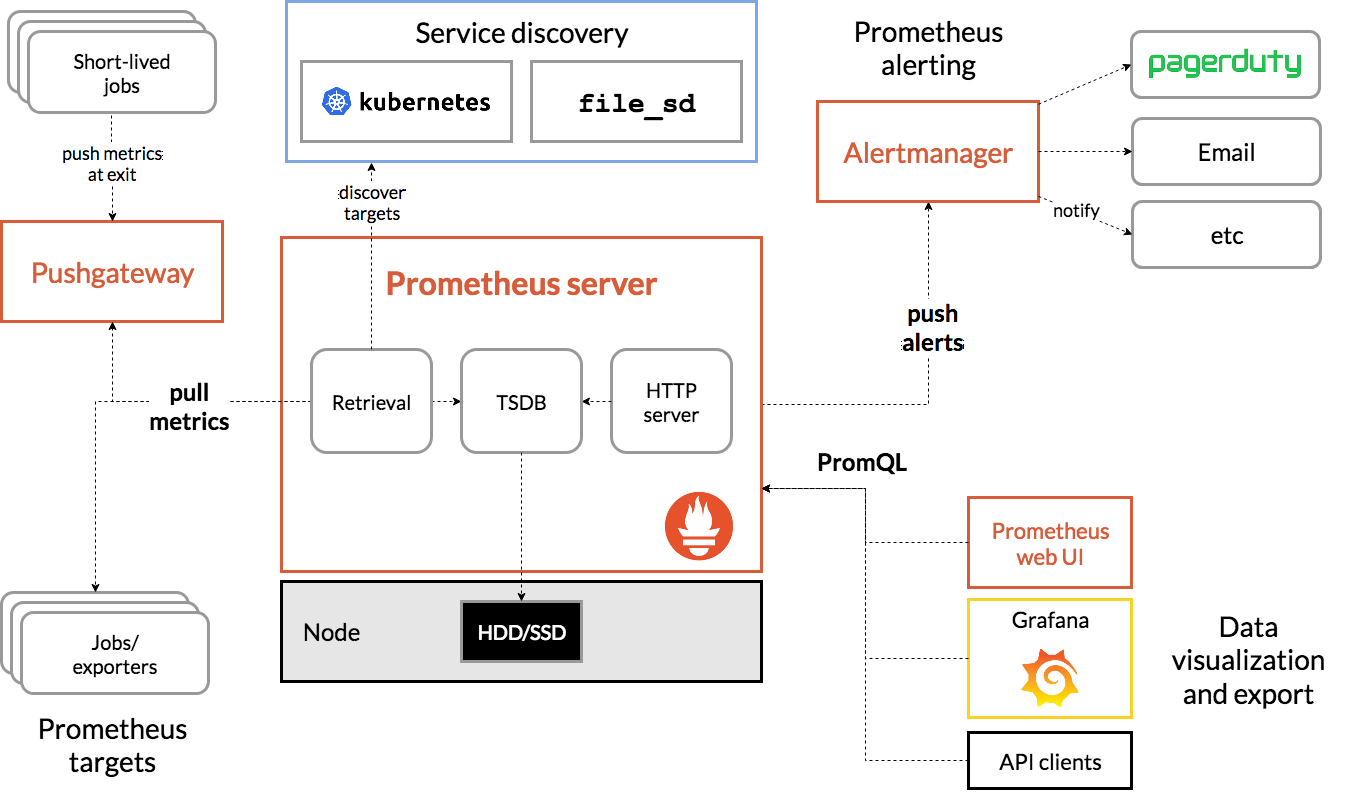
Prometheus
Metric Collector + Metric Database
Opensource Monitoring/ alerting tool
실제 프로덕션에서 사용하는 비율이 70% - 2020
왜 프로메테우스를 사용하는가?
1. 메트릭 수집을 위한 서버나 컨테이너 구성/설치 불필요
2. 애플리케이션에서 메트릭 푸시를 위해 CPU 사용이 불필요
3. 중앙 집중식 구성 및 관리 콘솔 제공
4. 서비스 장애 및 비가동 상황을 gracefully 처리 가능
5. 수천, 수만개의 메트릭을 직접 보지 않고 쿼리를 통해 그때그때 보기 때문에 트래픽 및 오버헤드 감소
6. pull 방식이 불가능할 경우 Pushgateway로 Push 방식 수집 가능
Prometheus Metrics
Labels: multi-dimensional data (Key-Value)
metadata 존재.
- #HELP: 메트릭 이름, 간단한 설명
- #TYPE: 메트릭 데이터 타입
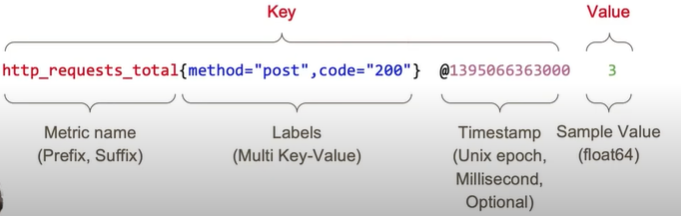
PromQL
메트릭을 검색(retrive)하기 위한 고유한 쿼리 언어
Instance: single unit/process (ex:서버 단위, CPU 사용량)
Prometheus Metric Collections
Metric Source
- Directly: Metric endpoint. 서비스에서 메트릭을 제공하는 경우(k8s, istio, docker)
- Exporter: Official & 3rd Party
Prometheus-server
프로메테우스의 주요 기능을 수행하는 요소로, 3가지 역할을 맡는다. Node Exporter 외 여러 대상에서 공개된 메트릭을 수집해 오는 수집기, 수집한 시계열 메트릭 데이터를 저장하는 시계열 데이터베이스, 저장된 데이터를 질의하거나 수집 대상의 상태를 확인할 수 있는 웹 UI.Node Exporter
노드의 시스템 메트릭 정보를 HTTP로 공개하는 역할. 설치된 노드에서 특정 파일들을 읽고, 이를 프로메테우스 서버가 수집할 수 있는 메트릭 데이터로 변환한 후에 노드 익스포터에서 HTTP 서버로 공개.
- HW, OS 메트릭 수집
- CPU, Memory, Disk, FileSystem
- vmstat, netstat, iostat, /proc/~
kubelet (cAdvisor)
- 개별 컨테이너 메트릭
kube-state-metric
- API 서버를 통해 오브젝트 상태에 관한 메트릭을 생성하는 도구 (deployment, Pod 등)
Exporter
- 코드를 직접 수정할 수 없는 패키징 소프트웨어 메트릭이 노출시킬 때 사용
- 네트워크, 스토리지, 데이터베이스 솔루션 또는 시스템 계측 시
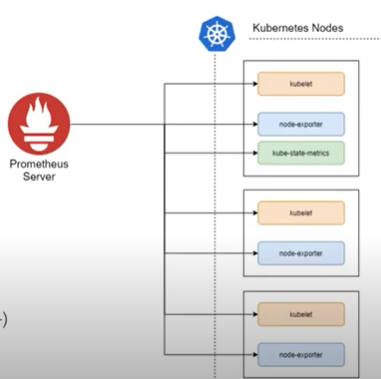
Metric Collections 외 Object
alert manger: alert 규칙을 설정하고 이벤트가 발생하면 메시지를 대상에게 전달하는 기능
pushgateway: 배치와 스케줄 작업 시 수행되는 일회성 작업들의 상태를 저장하고 모아서 프로메테우스가 주기적으로 가져갈 수 있도록 공개
Prometheus Metric Target
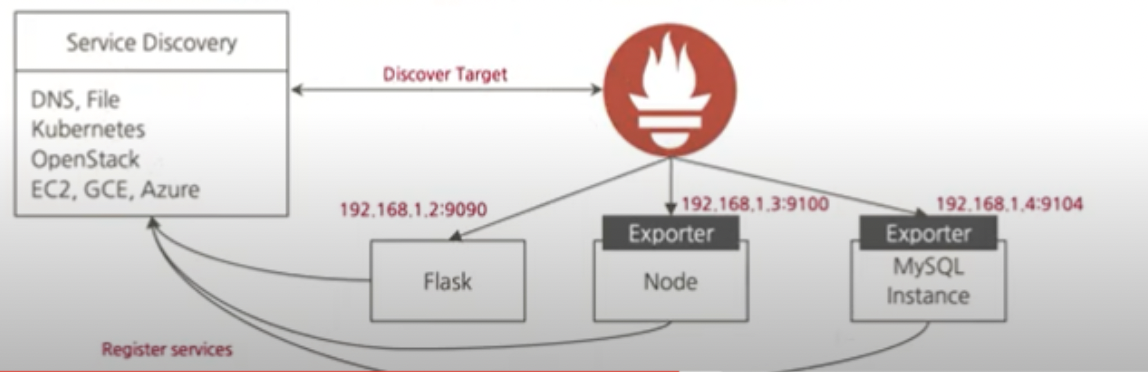
Service Discovery
프로메테우스는 수집 대상을 자동으로 인식하고 필요한 정보를 수집. 정보를 수집하려면 일반적으로 에이전트를 설정해야 하지만, 쿠버네티스는 사용자가 에이전트에 추가로 입력할 필요 없이 자동으로 메트릭을 수집할 수 있다.
SD 작동순서
1. 프로메테우스 서버는 컨피그맵에 기록된 내용을 바탕으로 대상을 읽어온다.
2. 읽어온 대상에 대한 메트릭을 가져오기 위해 API 서버에 정보 요청
3. 요청을 통해 알아온 경로로 메트릭 데이터를 수집
- Static Target
- Service Discovery
- File-based Discovery
- Automated Discovery (DNS, Consul, Cloud Provider, Kubernetes...)
쿠버네티스가 나온 후 dynamic한 리소스 관리를 프로메테우스가 할 수 있어서 폭발적으로 성장 가능했다.
Kubernetes Components Metrics
ETCD 포함 Kubernetes의 모든 컴포넌트는 Prometheus의 metric 형태로 엔드포인트 제공. Prometheus 의 scrape 설정만으로 metric 수집이 가능

Prometheus Alerting & Alertmanager
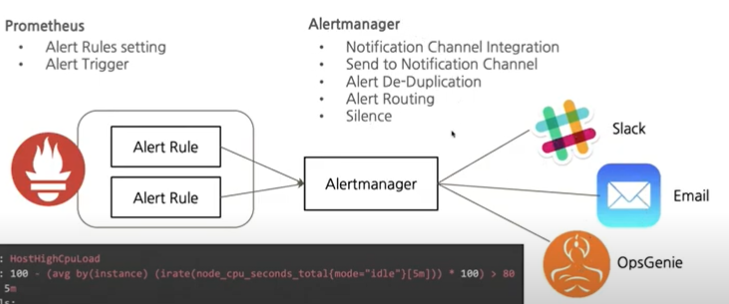
Prometheus Visualization
Grafana Dashboard - Many Wellmade Charts
Prometheus Flow
프로메테우스 제약 조건
- 원시 로그 / 이벤트 수집 불가: Loki, Elastic Stack
- 요청 추적 불가: OpenMetrics, OpenCensus
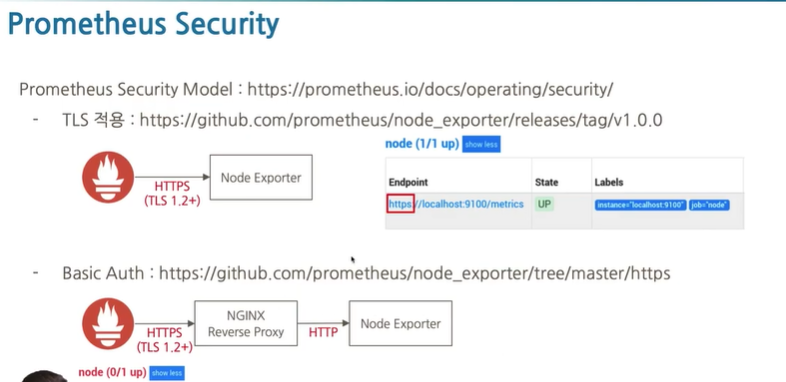
Prometheus Security
- TLS 적용
[참고] 쿠버네티스 환경에서 노드가 추가/삭제될 때마다 관리자가 에이전트를 설치/삭제해야 하나요?
→ 노드도 추가/삭제될 수 있지만 매번 관리자가 에이전트를 설치/삭제하지 않습니다. 보통 데몬셋(DaemonSet) 형태의 모니터링 컴포넌트가 사용되는데, 데몬셋은 모든 노드에 배포되는 애플리케이션을 나타내는 오브젝트로 보통 관리 목적의 구성요소를 배포하기 위해 사용됩니다.
무엇을 모니터링해야 할까?
쿠버네티스 환경에서 발생할 수 있는 이슈 상황 예시
- 특정 노드가 다운되거나 Ready 상태가 아닌 경우
- 컨트롤 플레인의 주요 컴포넌트 상태가 비정상적인 경우
- 노드의 가용한 리소스보다 리소스 요청량(Request)가 커서 파드가 배포되지 않는 경우
- 노드 리소스가 부족하여 컨테이너의 크래시(혹은 eviction)가 발생한 경우
- 특정 컨테이너가 OOMKilled나 그 밖의 문제로 인해 반복적으로 재시작하는 경우
- PV로 할당하여 마운트된 파일시스템의 용량이 부족한 경우
클러스터 구성요소(노드 및 주요 컴포넌트)의 상태
쿠버네티스 자체를 모니터링. 클러스터의 주요 컴포넌트와 더불어 노드의 상태도 확인 필요. 각각 Healthy, Ready 상태여야 한다.
노드의 리소스 가용량
전체 노드에 가용한 리소스(Allocatable)가 파드의 요청량(Request)보다 부족하면 파드가 더 이상 스케줄링 되지 못한다. 필요한 경우 노드 리소스를 증설하거나, 노드를 추가해야 한다. 가장 쉬운 방법은 노드 상태를 확인하여 Allocated resources 부분의 각 CPU와 메모리 요청(Request)에 대한 퍼센티지 확인 가능
노드의 리소스 사용량
노드의 MemoryPressure, DiskPressure가 발생하는 경우 노드의 컨디션이 변경되고 파드 eviction이 발생한다. 일정 수준 이상으로 노드의 리소스가 유지되도록 모니터링이 필요하다.
Workload 이슈
애플리케이션 프로세스 다운 모니터링. 파드에 적절한 liveness probe가 설정되어 있는 경우, 혹은 OOMKilled 되는 경우는 컨테이너의 재시작 횟수(Restart Count)가 지속적으로 증가하는지 모니터링해 볼 수 있다.
Monitoring Plan
모니터링을 하는건 트러블을 관리하고 해결하기 위해서이다. 대표적인 트러블 시나리오를 작성하고 해결하는 방식으로 고도화할 계획이다.
- 모니터링에 대한 학습
- 배포
- Alerting & Altermanager
- scenario 기반 develop
- HPA
- Security - TLS 적용
Reference
- https://velog.io/@mng_jn/0809%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4-%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81-%ED%94%84%EB%A1%9C%EB%A9%94%ED%85%8C%EC%9A%B0%EC%8A%A4-%EA%B7%B8%EB%9D%BC%ED%8C%8C%EB%82%98 : 쿠버네티스 모니터링 프로메테우스, 그라파나
- https://www.youtube.com/watch?v=_bI_WcBc4ak: Prometheus Project Journey
- https://devthomas.tistory.com/24: 쿠버네티스에서 모니터링 시스템 운영기
- https://leoh0.github.io/post/2018-10-09-kubernetes-prometheus-metric-aggregation-by-daemonset-statefulset-deployment-walkthrough/: Kubernetes Prometheus Metric Aggregation by Daemonset, Statefulset, Deployment Walkthrough
- https://www.samsungsds.com/kr/insights/kubernetes_monitoring.html: 삼성SDS- 쿠버네티스 클러스터 운영자를 위한 모니터링
프로메테우스 오픈소스 모니터링 시스템
