
🔥 Contents
- 모니터링이란?
- 로깅, 메트릭
- 모니터링 방식 Pull vs Push
- 쿠버네티스 모니터링
- 프로메테우스란
- 프로메테우스
- 쿠버네티스 환경에서 발생할 수 있는 이슈 상황
📌Monitoring
모니터링은 IT 시스템의 핵심적인 부분이다. positioning problem을 발견하고 지원하는 역할을 담당한다.
전통적인 O&M이든, SRE든, DevOps든, 개발자들은 모니터링 시스템의 구축과 최적화에 관심을 기울여야 한다.
메인프레임 운영체제와 리눅스 기본 지표부터 시작해서, 점차 발전하기 시작했다.
이제, 다음과 같이 다양한 범주로 나눌 수 있는 수백가지의 모니터링 시스템이 있다.
Monitoring System Type
Monitoring Object
범용: 일반적인 모니터링 방법, 대부분의 모니터링 대상에 적합
전용: 특정 기능에 맞게 커스터마이즈됌. Java JMX 시스템, CPU high-temperature protection, 하드디스크 전원 장애 보호, UPS 스위칭 시스템, 스위치 모니터링 시스템, private line monitoring
Data Acquistion Method
Push(CollectD, Zabbix 및 InlusionDB) vs Pull(Prometheus, SNMP 및 JMX)
Deployment Mode
- Coupled(결합형, 모니터링 시스템과 함께 구축)
- Standalone(독립적으로 실행, 단일 인스턴스 구축)
- Distributed(분산형, 수평적 확장 가능)
- SaaS(구축 불필요)
Commercial
Open-source and free of charge: (Prometheus 및 InlusionDB 독립 실행형 에디션)
open-source commercial type(InlusionDB 클러스터 에디션, Elastic Search X-Pack),
closed-source commercial type(DataDog, Splunk, AWS Cloud Watch)
모니터링의 범주
결국 대부분의 모니터링은 단 한 가지, 이벤트에 대한 것이다. 이벤트에는 다음과 같은 사항을 비롯해 거의 모든 것이 포함된다.
- HTTP 요청 수신
- HTTP 400 응답 송신
- 함수 시작
- if 문의 else에 도달
- 함수종료
- 사용자 로그인
- 디스크에 데이터 쓰기
- 네트워크에서 데이터 읽기
- 커널에 추가 메모리 요청
모든 이벤트에는 컨텍스트가 있다. HTTP 요청에는 들어오고 나가는 IP 주소, 요청 URL, 설정된 쿠기, 요청한 사용자 정보가 들어있다.
모든 이벤트에 대한 컨텍스트를 파악하면, 디버깅에 큰 도움이 되고 기술적인 관점과 비즈니스 관점 모두에서 시스템의 수행 방법을 이해할 수 있지만, 처리 및 저장해야 하는 데이터 양이 늘어난다.
따라서, 데이터의 양을 감소시킬 수 있는 방법으로 프로파일링, 트레이싱, 로깅, 메트릭의 네 가지가 있다.
✔ 로깅
Logging은 제한된 이벤트 집합을 살펴보고 각 이벤트에 대한 컨텍스트 일부를 기록한다. 예를 들면 로깅은 수신되는 모든 HTTP 요청이나 발신되는 모든 데이터베이스 호출 같은 이벤트를 살펴보고 기록한다. 자원의 낭비를 방지하려면 로그 항목별로 수백 개 정도의 필드 개수를 제한해야 한다. 이외에도 대역폭과 저장 장치가 문제가 되기도 한다.
예를 들어 초당 수천 개의 요청을 처리해야 하는 서버의 경우, 로깅을 위해서만 하루 84GB의 저장소를 사용한다.(계산 과정 생략)
로깅의 가장 큰 장점은 일반적으로 이벤트에 대한 샘플링이 없다는 점이다. 따라서 필드 개수를 제한하더라도, 시간이 오래 걸리는 요청이 특정 API 엔드포인트와 통신하는 특정 유저에게 얼마나 영향을 미치는지를 판단해야 한다.
로깅은 다음과 같이 일반적이지만 중복될 수 있는 4가지 범주로 나룰 수 있다.
트랜잭션 로그
어떠한 대가를 치르더라도 영원히 안전하게 보관해야 하는 중요한 비즈니스 기록이다. 주로 비용과 연관된 기능이나 사용자가 직접 사용하는 주요 기능이 트랜잭션 로그에 속한다.
요청 로그
모든 HTTP 요청이나 데이터베이스 호출을 추적하는 경우의 로그다. 요청 로그는 사용자 직접 사용하는 기능이나 내부 최적화의 구현에 쓰일 수 있다. 사라지지 않으면 좋겠지만 일부를 잃는다고 해서 큰 문제가 되지는 않는다.
애플리케이션 로그
모든 로그가 요청 로그인 것은 아니며, 프로세스 그 자체에 대한 로그도 있다. 시작 메시지, 백그라운드 유지보수 작업, 그리고 그 밖에 프로세스 수준의 로그들이 전형적인 애플리케이션 로그다. 이러한 로그는 주로 사람들이 직접 읽기 때문에, 정상적인 동작에서 1분당 몇 개 정도가 적절하다.
디버그 로그
디버그 로그는 굉장히 상세해서 생성과 저장에 비용이 많이 든다. 디버그 로그는 주로 매우 협소한 디버깅 상황에만 사용되며, 데이터의 양 때문에 프로파일링의 특성을 띤다. 신뢰성과 보유 요고수항이 낮은 편이며, 거의 디버그 로그는 로그가 생성된 머신에서만 유용하다.
로깅 시스템의 예로는 ELK 스택과 Graylog 등이 있다.
✔ 메트릭
메트릭은 컨텍스트를 대부분 무시하고 다양한 유형의 이벤트에 대해 시간에 따른 집계(aggregation)를 추적한다. 자원 사용을 정상적으로 유지하려면, 추적하는 메트릭의 개수를 제한해야 한다. 프로세스당 1만 개의 메트릭 처리 정도가 합리적인 상한선일 것이다.
아마도 우리가 경험할 수 있는 Metric으로는 수신된 HTTP 요청 횟수, 요청을 처리하는 데 걸린 시간, 현재 진행 중인 요청 수 등이다. 컨텍스트 정보를 제외하면 필요한 데이터 양과 처리는 합리적인 수준으로 유지된다.
메트릭을 이용하면 애플리케이션의 각 서브시스템에서의 대기 시간과 처리하는 데이터 양을 추적해서 성능 저하의 원인이 정확히 무엇인지 손쉽게 알아낼 수 있다. 로그에 많은 필드를 기록할 수는 없다. 하지만 어떤 서브시스템에 문제의 원인이 있는지를 찾아낸 다음, 로그를 통해 해당 문제에 관련된 사용자 요청을 정확하게 파악할 수 있다.
이 부분이 로그와 메트릭 사이의 균형이 가장 명확해지는 지점이다. 메트릭은 프로세스 전반에 걸쳐 이벤트 정보를 수집할 수 있지만, 일반적으로 카디널리티가 제한된 컨텍스트는 1~2개 이상의 필드를 갖지 않는다. 로그는 한 가지 유형의 이벤트에 대해 모든 정보를 수집할 수 있지만, 카디널리티가 제한되지 않은 컨텍스트에 대해 수백 개 필드만 추적할 수 있다.
심플하게 생각하면 메트릭은 특정 기준에 대한 수치를 나타낸다면 로그는 어떤 오류인지 파악하기 위해 사용하는 데이터를 의미한다. 예를 들면 어플리케이션의 레이턴시가 높아지는 상황을 메트릭을 통해 파악한다면 이로 인해 발생하는 오류에 대한 내용을 파악하기 위해서는 로그를 사용한다.
메트릭 기반 모니터링 시스템으로서 프로메테우스는 개별 이벤트 보다는 전반적인 시스템의 상태와 동작, 성능을 추적하도록 설계되었다. 다시 말해, 프로메테우스는 처리하는데 4초가 걸린 15개의 요청이 마지막 1분 동안 발생했고, 결과적으로 40번의 데이터베이스 호출과 17번의 캐시 히트와 2건의 고객 구매가 일어났다는 사실에만 주의를 기울인다. 각 호출에 걸린 비용과 코드 경로는 프로파일링이나 로깅의 관심사항일 뿐이다.
컨테이너 인프라 환경에서 metric 구분
- system metrics: 파드 같은 오브젝트에서 측정되는 CPU와 메모리 사용량을 나타내는 메트릭
- service metrics: HTTP 상태 코드 같은 서비스 상태를 나타내는 메트릭
프로파일링
프로파일링은 우리가 모든 시간에 대해 모든 이벤트의 컨텍스트를 가질 수 없지만, 제한된 기간의 일부 컨텍스트를 가질 수 있다는 방식으로 접근한다.
프로파일링은 상당히 전략적인 디버깅 방법이다. 오랜 시간 동안 프로파일링을 해야하는 경우, 다른 모니터링 방법과 함게 사용하려면 반드시 데이터의 양을 줄여야 한다.
트레이싱
Traicing은 모든 이벤트를 살펴보는 것이 아니라, 관심 기능을 통과하는 일부 이벤트처럼 수백 개의 이벤트 중 특정 이벤트에만 집중한다. 트레이싱은 스택 트레이스에서 관심 있는 부분의 함수들을 기록하고, 때때로 이러한 함수들이 얼마나 오랫동안 수행되었는지도 기록한다. 이를 통해 프로그램이 어느 부분에서 시간을 소비하고 어떤 코드 경로가 지연에 가장 큰 영향을 미치는지를 알 수 있다.
트레이싱 시스템 중 일부는 관심 지점에서 스택 트레이스에 스냅샷을 수집하는 대신, 관심있는 함수 하위의 모든 함수 호출을 추적하고 타이밍을 기록한다. 예를 들어 수백 개의 사용자 HTTP 요청 중 하나를 샘플링할 수 있고, 이 요청에 대해 데이터베이스나 캐시같은 백엔드와 통신하는 데 얼마나 오랜 시간이 소비되었는지 확인할 수 있다. 이를 통해 캐시 히트와 캐시 미스를 비교해서 타이밍이 얼마나 차이가 나는지 확인할 수 있다.
트레이싱에서 데이터 볼륨 유지 및 계측 성능에 영향을 미치는 것은 Sampling 이다.
Metric 수집 방식의 이해 Push vs Pull
pull 기반 모니터링 시스템은 능동적으로 지표를 획득하는 모니터링 시스템으로, 모니터링이 필요한 오브젝트는 원격으로 접근할 수 있어야 한다.
push 기반 모니터링 시스템은 모니터링이 필요한 오브젝트가 적극적으로 지표를 푸시한다.
두 가지 방법에는 여러 측면에서 차이점이 크다. 모니터링 시스템의 구축 및 선택을 위해서는 두 가지 방법의 장단점을 미리 이해하고 적절한 구현 방식을 선택해야 한다.
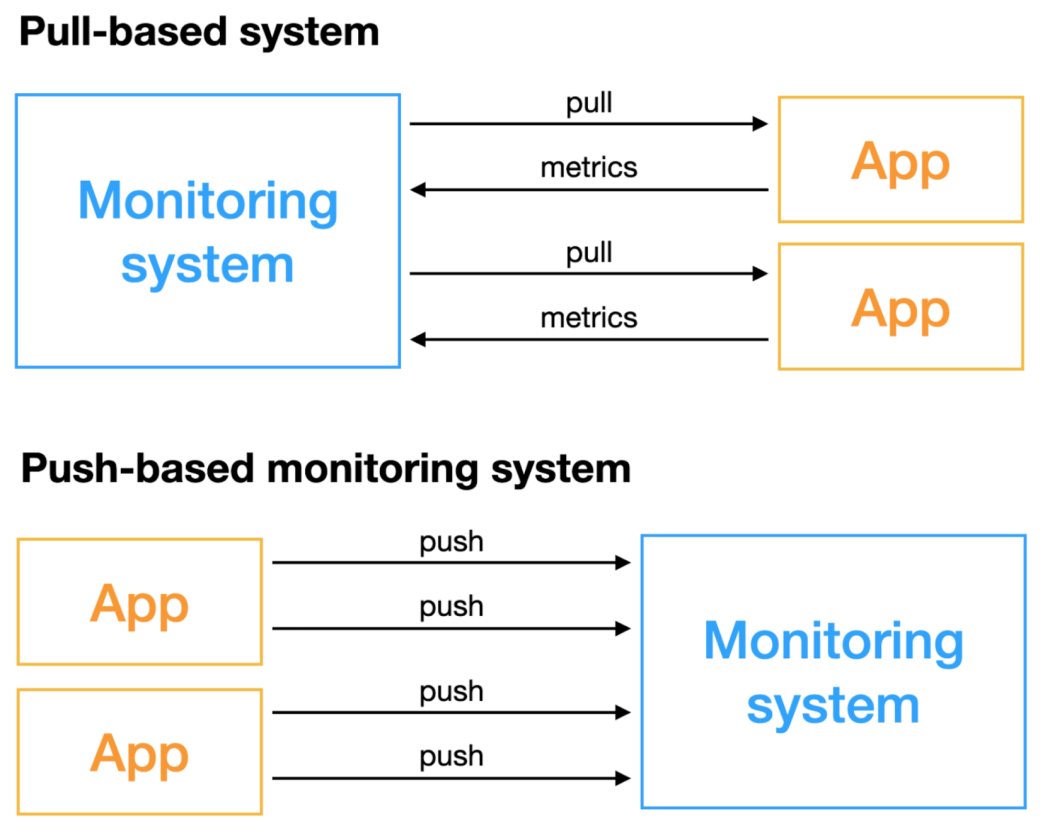
Push(CollectD, Zabbix, InfulxDB)
수집 서버 정보를 알아야 함. agent에는 반드시 system agent가 설치되야 하고 agent는 중앙에 있는 서버에 metric을 보내야 하기 때문에 서버의 end-point IP를 알아야 한다. metric 정보가 변경될 때 마다 재 배포 해야 한다.
Pull (Prometheus, SNMP, JMX)
pull 기반 모니터링 시스템은 능동적으로 지표를 획득한다. 모니터링이 필요한 오브젝트는 원격으로 접근 가능해야 한다.
보통 수집 서버에 대한 정보를 agent나 서비스들이 알지 못한다. 프로메테우스는 agent가 내부 metric을 노출하고, 프로메테우스 중앙 집중형 컴포넌트가 metric을 수집한 후 DB에 저장한다.
중앙집중식 모니터링이지만 agent는 서버에 대한 정보를 모르고 외부에서 exporter나 다른 정보들이 metric을 expose 하는 것
Service Discovery; k8s같은 오케스트레이션 툴을 통해 리소스에 있는 정보를 다이나믹하게 가져오는 방식
아래 그림은 Pull vs Push Monitoring 을 다양한 측면에서 비교한 표이다.
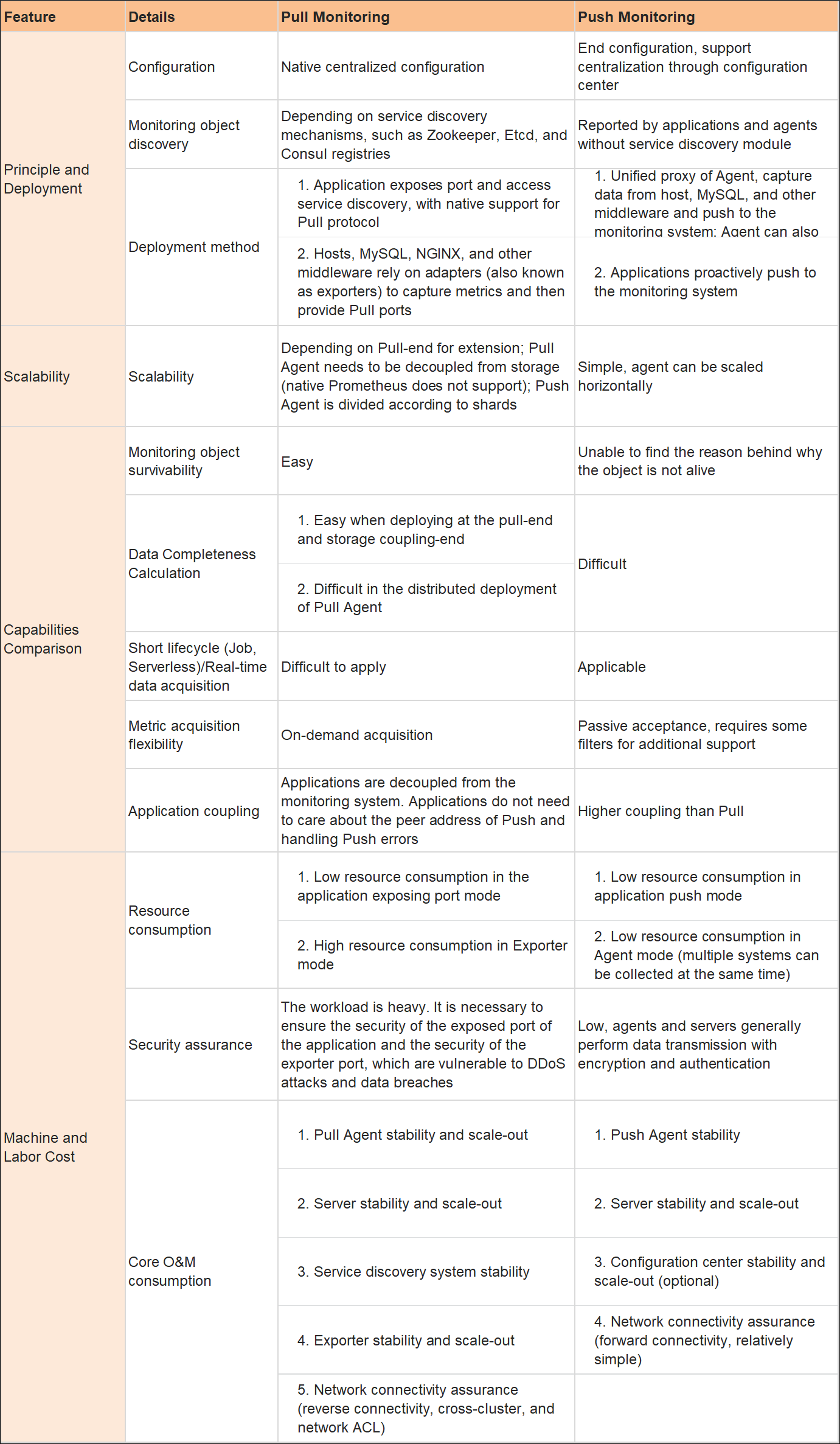
Pull과 Push 에 대한 자세한 비교는 여기에 정리 했다.
쿠버네티스 모니터링
k8s 모니터링 컨셉
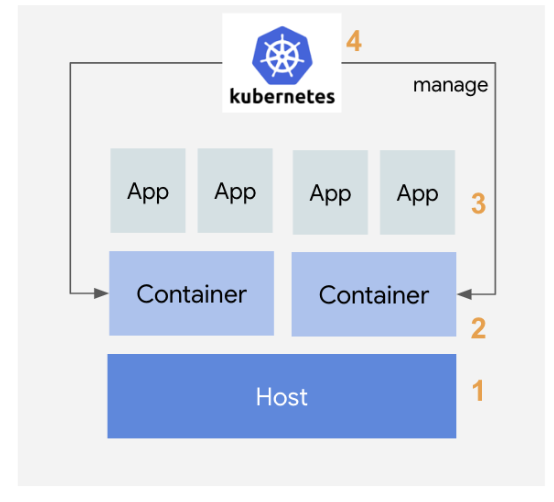
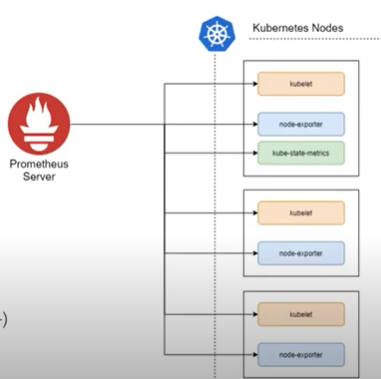
쿠버네티스 노드는 kubelet을 통해 파드를 관리하며, 파드의 CPU나 메모리 같은 메트릭 정보를 수집하기 위해 kubelet에 내장된 cAdvisor를 사용. cAdvisor는 쿠버네티스 클러스터 위에 배포된 여러 컨테이너가 사용하는 메트릭 정보를 수집한 후 이를 가공해서 kubelet에 전달하는 역할.
모니터링 대상
- host(node-exporter)
노드의 CPU, 메모리, 디스크, 네트워크 사용량과 노드 OS와 커널에 대한 모니터링- container(kubelet[cadvisor])
노드에서 가동되는 컨테이너에 대한 정보. CPU, 메모리, 디스크, 네트워크 사용량 등- app
컨테이너안에서 구동되는 개별 애플리케이션의 지표를 모니터링. 애플리케이션의 응답시간, HTTP 에러 빈도 등을 모니터링- kubernetes(etcd <- api -> kube-state-metrics)
쿠버네티스 자체에 대한 모니터링. 서비스나 POD, 계정 정보 등이 해당
쿠버네티스 모니터링 아키텍쳐
쿠버네티스 모니터링을 쿠버네티스의 컴포넌트가 직접 활용하는 정보와 이보다 많은 정보를 수집해 히스토리/통계 정보를 보여주는 모니터링 시스템 관점으로 나눌 수 있다. 이를 Resource Metrics Pipeline과 Full Metrics Pipeline 으로 나눠서 설명한다.
Resource Metrics Pipeline
쿠버네티스 컴포넌트가 활용하는 메트릭 흐름. 수집된 정보를 kubectl top 명령으로 노출해주고, 스케일링이 설정되어 있다면 오토스케일링에 활용. metrics-server를 통해 수집된 모니터링 정보를 메모리에 저장하고 API 서버를 통해 노출해 kubectl top, scheduler, HPA와 같은 오브젝트에서 사용. 쿠버네티스의 일부 기능은 Metric Server의 정보를 사용. 다만, 순간의 정보를 가지고 있고 장시간 저장하지도 않기 때문에 Full Metrics Pipeline이 필요하다.Full Metrics Pipeline
다양한 메트릭을 수집하고, 이를 스토리지에 저장. 프로메테우스를 통해 서비스 디스커버리, 메트릭 수집(Retrieval) 및 시계열 데이터베이스(TSDB)를 통한 저장, 쿼리 엔진을 통한 PromQL 사용과 Alertmanager를 통한 통보가 가능.
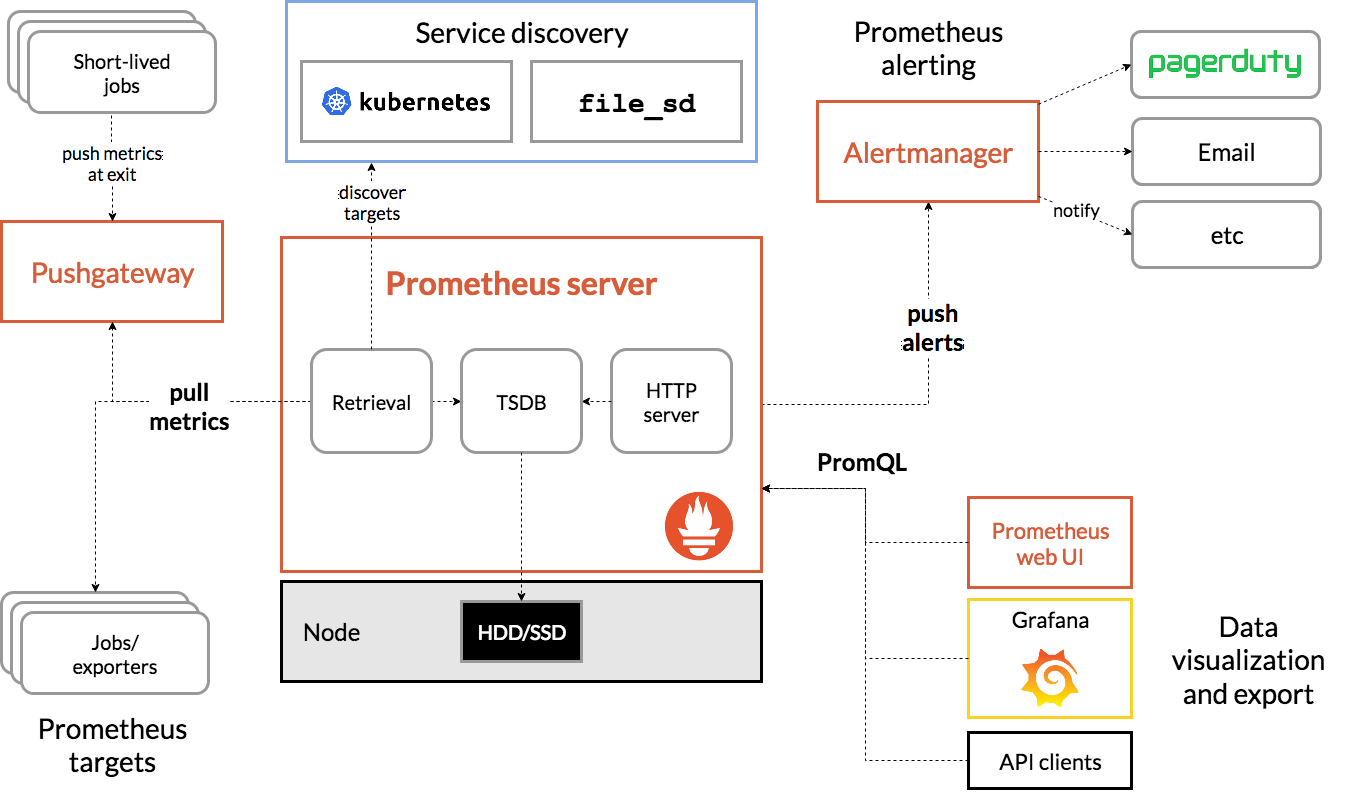
Prometheus
Overview
프로메테우스는 메트릭 기반의 오픈소스 모니터링 시스템이다.
프로메테우스가 맡은 주요 임무는 메트릭 기반 모니터링이고, 이 임무를 잘 수행한다. 프로메테우스에는 단순하지만 강력한 데이터 모델과 쿼리언어(PromQL)이 있으며, 이를 통해 애플리케이션과 인프라의 성능을 분석할 수 있다. 프로메테우스는 메트릭을 측정할 뿐, 메트릭 이외의 문제는 더 적절한 다른 도구가 처리하도록 남겨둔다.
프로메테우스는 간단한 텍스트 형식을 통해 쉽게 메트릭을 게시할 수 있다. 오픈소스나 다른 모니터링 시스템도 프로메테우스 텍스트 형식에 대한 지원을 추가했다. 이를 통해 모든 모니터링 시스템은 각자 주요 기능에 더 집중할 수 있게 됐다. 각 모니터링 시스템은 사용자들이 모니터링하려는 소프트웨어 하나 하나에 대해 일일이 지원하지 않아도 되는 것이다.
데이터 모델은 이름뿐 아니라 key-value 쌍으로 이뤄진 label로 비정렬 세트로도 모든 시계열을 구별한다. PromQL 쿼리 언어로 이러한 label중 일부를 집계할 수 있다. 따라서 프로세스 단위 뿐 아니라 데이터 센터별로도 분석할 수 있으며, 서비스 단위나 직접 정의한 다른 레이블을 통해서도 분석이 가능하다. 결과는 Grafana 같은 대시보드 시스템에서 볼 수 있다.
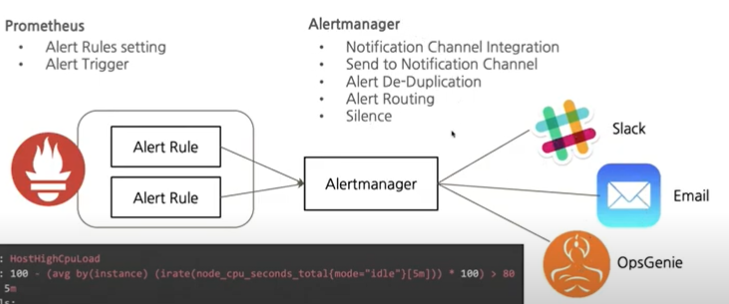
Alert는 그래프 작성에 사용하는 것과 동일한 PromQL 쿼리 언어로 정의할 수 있다. Lebel을 사용하면 하나의 알림에서 가능한 모든 레이블 값을 처리할 수 있으므로 알림을 더 쉽게 관리할 수 있다.
이 같은 모든 기능과 장점 덕분에 프로메테우스는 성능이 좋으며 실행하기도 쉽다. 프로메테우스 서버 한 대는 초당 수백만 개의 데이터 샘플을 처리할 수 있다. 프로메테우스 서버는 구성 파일과 함께 사용하는 정적으로 링크된 단일 바이너리다.
왜 프로메테우스를 사용하는가?
- 메트릭 수집을 위한 서버나 컨테이너 구성/설치 불필요
- 애플리케이션에서 메트릭 푸시를 위해 CPU 사용이 불필요
- 중앙 집중식 구성 및 관리 콘솔 제공
- 서비스 장애 및 비가동 상황을 gracefully 처리 가능
- 수천, 수만개의 메트릭을 직접 보지 않고 쿼리를 통해 그때그때 보기 때문에 트래픽 및 오버헤드 감소
- pull 방식이 불가능할 경우 Pushgateway로 Push 방식 수집 가능
PromQL
메트릭을 검색(retrive)하기 위한 고유한 쿼리 언어
Instance: single unit/process (ex:서버 단위, CPU 사용량)
Promehteus Architecture
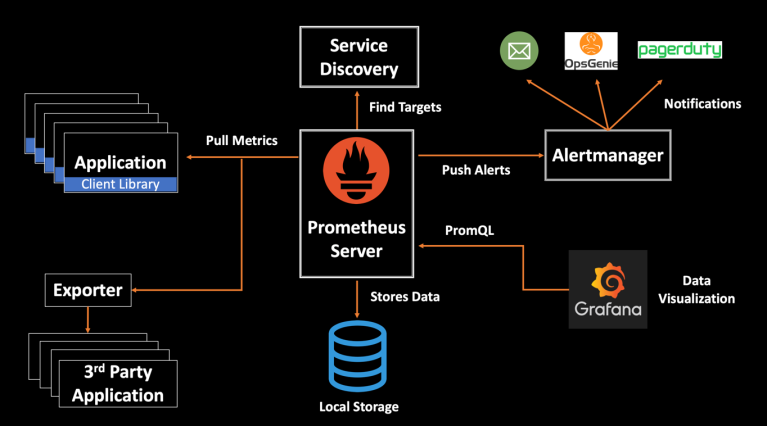
Prometheus Metric Collections
Metric Source
- Directly: Metric endpoint. 서비스에서 메트릭을 제공하는 경우(k8s, istio, docker)
- Exporter: Official & 3rd Party
✔ Prometheus Object
Prometheus-server
프로메테우스의 주요 기능을 수행하는 요소로, 3가지 역할을 맡는다. Node Exporter 외 여러 대상에서 공개된 메트릭을 수집해 오는 수집기, 수집한 시계열 메트릭 데이터를 저장하는 시계열 데이터베이스, 저장된 데이터를 질의하거나 수집 대상의 상태를 확인할 수 있는 웹 UI.
Node Exporter
노드의 시스템 메트릭 정보를 HTTP로 공개하는 역할. 설치된 노드에서 특정 파일들을 읽고, 이를 프로메테우스 서버가 수집할 수 있는 메트릭 데이터로 변환한 후에 노드 익스포터에서 HTTP 서버로 공개.
- HW, OS 메트릭 수집
- CPU, Memory, Disk, FileSystem
- vmstat, netstat, iostat, /proc/~
kubelet (cAdvisor)
- 개별 컨테이너 메트릭
kube-state-metric
- API 서버를 통해 오브젝트 상태에 관한 메트릭을 생성하는 도구 (deployment, Pod 등)
Client Library
메트릭은 누군가 메트릭을 만들기 위한 계측 코드를 추가해야한다. 이 부분을 관여하는 것이 클라이언트 라이브러리다. 코드로 메트릭을 정의하고, 제어하려는 코드에 인라인으로 원하는 계측 기능을 추가할 수 있다. 이를 직접 계측이라고 한다.
클라이언트 라이브러리는 모든 주요 언어와 런타임에 사용할 수 있다. Go, Python 등 주요 언어는 클라이언트 라이브러리를 제공한다. Node.js, Erlang 같은 다양한 서드파티 클라이언트도 있다.
클라이언트 라이브러리는 스레드 안정성, bookkepping, HTTP 요청에 대한 응답으로 프로메테우스 텍스트 게시 형식 생성 같은 모든 핵심 세부사항을 처리한다. 메트릭 기반 모니터링은 개별 이벤트를 추적하지 않기 때문에 메모리를 사용한다고 해서 이벤트가 더 늘어나지는 않는다. 오히려 메모리는 사용하는 메트릭 개수와 관련된다.
Exporter
대부분 시스템 커널 같은 소프트웨어에는 메트릭에 접근할 수 있는 인터페이스가 있다.
익스포터는 가져오고 싶은 메트릭을 애플리케이션 바로 옆에 배치하는 소프트웨어다. 익스포터는 프로메테우스로부터 요청을 받아서, 애플리케이션에서 요청된 데이터를 수집하고, 데이터를 올바른 형식으로 변환한 다음, 마지막으로 프로메테우스에 대한 응답으로 데이터를 반환한다. 익스포터는 애플리케이션의 메트릭 인터페이스를 프로메테우스의 게시 형식으로 변환하는 일대일 방식의 작은 프록시라고 생각해도 좋다.
Metric Collections 외 Object
alert manger: alert 규칙을 설정하고 이벤트가 발생하면 메시지를 대상에게 전달하는 기능
pushgateway: 배치와 스케줄 작업 시 수행되는 일회성 작업들의 상태를 저장하고 모아서 프로메테우스가 주기적으로 가져갈 수 있도록 공개
Prometheus Metric Target - 메트릭을 수집할 타겟을 어떻게 정하는가?
👏 Service Discovery
프로메테우스는 수집 대상을 자동으로 인식하고 필요한 정보를 수집한다.
정보를 수집하려면 일반적으로 에이전트를 설정해야 하지만, 쿠버네티스는 사용자가 에이전트에 추가로 입력할 필요 없이 자동으로 메트릭을 수집할 수 있다.
이는 프로메테우스 서버가 수집 대상을 가져오는 방법인 서비스 디스커버리 덕분이다.
Service Discovery Process
- 프로메테우스 서버는 컨피그맵에 기록된 내용을 바탕으로 대상을 읽어온다.
- 읽어온 대상에 대한 메트릭을 가져오기 위해 API 서버에 정보 요청
- 요청을 통해 알아온 경로로 메트릭 데이터를 수집
이와 같은 순서로 프로메테우스 서버와 API 서버가 주기적으로 데이터를 주고받아 수집 대상을 업데이트하고, 수집 대상에서 공개되는 메트릭을 자동으로 수집한다.
쿠버네티스가 나온 후 dynamic한 리소스 관리를 프로메테우스가 할 수 있어서 폭발적으로 성장 가능했다.
Kubernetes Components Metrics
ETCD 포함 Kubernetes의 모든 컴포넌트는 Prometheus의 metric 형태로 엔드포인트 제공. Prometheus 의 scrape 설정만으로 metric 수집이 가능

Prometheus Alerting & Alertmanager
Prometheus Visualization
Grafana Dashboard - Many Wellmade Charts
Grafana Dashboard
프로메테우스 제약 조건
- 원시 로그 / 이벤트 수집 불가: Loki, Elastic Stack
- 요청 추적 불가: OpenMetrics, OpenCensus
Prometheus Security
- TLS 적용
무엇을 모니터링해야 할까?
쿠버네티스 환경에서 발생할 수 있는 이슈 상황 예시
- 특정 노드가 다운되거나 Ready 상태가 아닌 경우
- 컨트롤 플레인의 주요 컴포넌트 상태가 비정상적인 경우
- 노드의 가용한 리소스보다 리소스 요청량(Request)가 커서 파드가 배포되지 않는 경우
- 노드 리소스가 부족하여 컨테이너의 크래시(혹은 eviction)가 발생한 경우
- 특정 컨테이너가 OOMKilled나 그 밖의 문제로 인해 반복적으로 재시작하는 경우
- PV로 할당하여 마운트된 파일시스템의 용량이 부족한 경우
클러스터 구성요소(노드 및 주요 컴포넌트)의 상태
쿠버네티스 자체를 모니터링. 클러스터의 주요 컴포넌트와 더불어 노드의 상태도 확인 필요. 각각 Healthy, Ready 상태여야 한다.
노드의 리소스 가용량
전체 노드에 가용한 리소스(Allocatable)가 파드의 요청량(Request)보다 부족하면 파드가 더 이상 스케줄링 되지 못한다. 필요한 경우 노드 리소스를 증설하거나, 노드를 추가해야 한다. 가장 쉬운 방법은 노드 상태를 확인하여 Allocated resources 부분의 각 CPU와 메모리 요청(Request)에 대한 퍼센티지 확인 가능
노드의 리소스 사용량
노드의 MemoryPressure, DiskPressure가 발생하는 경우 노드의 컨디션이 변경되고 파드 eviction이 발생한다. 일정 수준 이상으로 노드의 리소스가 유지되도록 모니터링이 필요하다.
Workload 이슈
애플리케이션 프로세스 다운 모니터링. 파드에 적절한 liveness probe가 설정되어 있는 경우, 혹은 OOMKilled 되는 경우는 컨테이너의 재시작 횟수(Restart Count)가 지속적으로 증가하는지 모니터링해 볼 수 있다.
Reference
- https://velog.io/@mng_jn/0809%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4-%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81-%ED%94%84%EB%A1%9C%EB%A9%94%ED%85%8C%EC%9A%B0%EC%8A%A4-%EA%B7%B8%EB%9D%BC%ED%8C%8C%EB%82%98 : 쿠버네티스 모니터링 프로메테우스, 그라파나
- https://www.alibabacloud.com/blog/pull-or-push-how-to-select-monitoring-systems_599007: Monitoring push vs pull
- https://www.youtube.com/watch?v=_bI_WcBc4ak: Prometheus Project Journey
- https://devthomas.tistory.com/24: 쿠버네티스에서 모니터링 시스템 운영기
- https://leoh0.github.io/post/2018-10-09-kubernetes-prometheus-metric-aggregation-by-daemonset-statefulset-deployment-walkthrough/: Kubernetes Prometheus Metric Aggregation by Daemonset, Statefulset, Deployment Walkthrough
- https://www.samsungsds.com/kr/insights/kubernetes_monitoring.html: 삼성SDS- 쿠버네티스 클러스터 운영자를 위한 모니터링
프로메테우스 오픈소스 모니터링 시스템 - https://sphong0417.tistory.com/30

7개의 댓글


함수 호출의 스택 추적을 기록하면 프로그램 작동을 모니터링하는 데 도움이 됩니다 drive mad 2. 관심 있는 함수에 대한 데이터를 얻고 성능 연구에 사용하세요.

와, 모니터링 시스템 종류 진짜 많네! Prometheus만 있는 줄 알았는데... Push랑 Pull 방식 비교 보니까 확실히 이해가 쏙쏙 된다. 덕분에 모니터링 개념 정리 제대로 했어요!
와, 모니터링 시스템 종류 진짜 많네! Prometheus만 있는 줄 알았는데... Push랑 Pull 방식 비교 보니까 확실히 이해가 쏙쏙 된다. 덕분에 모니터링 개념 정리 제대로 했어요!
모니터링 시스템에 대해 진짜 자세하게 설명해줬네. Prometheus 뿐만 아니라 다른 방법들도 같이 다뤄서 완전 꿀팁이다! 나도 이거 보고 우리 시스템 모니터링 좀 더 효율적으로 만들어봐야겠다. crazy cattle 3d

함수 호출의 스택 추적을 기록하면 프로그램 작동을 모니터링하는 데 도움이 됩니다 드리프트 보스 게임. 관심 있는 함수에 대한 데이터를 얻고 성능 연구에 사용하세요.
자세한 설명 감사합니다!