This Dot Media와 Dustin Goodman의 글을 번역하고, 중간 중간 필요한 내용을 추가하여 작성한 글입니다. 많은 의역이 들어갔으며 글을 재구성하였기에 아래 두 원문을 읽어보시는 것을 추천 드립니다.
Introduction
GraphQL은 새로운 API 기준으로, 데이터 기반의 애플리케이션을 만드는데 혁신적인 접근법을 제공한다. 페이스북이 모바일 앱을 HTML5에서 네이티브로 변경하는 과정에서 만들어졌고, 2015년이 되어서야 대중들에게 오픈 소스로 공개 되었다.
이후 GraphQL은 많은 기업과 스타트업들에게 관심을 받았다. 이전의 웹은 REST와 SOAP API를 사용해왔다.
RESTful API
HTTP request를 활용해 데이터 접근/사용하는 API 아키텍쳐 스타일. GET, PUT, POST, DELETE 데이터 타입을 사용하여 데이터를 읽고 수정하고 만들고 삭제한다. source
SOAP API
SOAP은 Simple Object Access Protocl의 줄임말로, 프로토콜이며, 시스템과 애플리케이션이 정보를 교환할 때 사용되는 통신 규약이다. 이를 기반으로 조금 더 엄격한 규범이 적용된 것이 SOAP API이다. source
두 개의 API 모두 제 역할을 다하긴 했으나, 애플리케이션이 점점 더 복잡해지고 데이터들이 많아지면서 조금씩 문제가 생기기 시작했다.
기존 API vs. GraphQL
기존 API의 문제점
1. Data under-fetching 또는 n+1 fetching
Data under-fetching은 한 번의 요청으로 필요한 데이터를 다 가져오지 못해서, 여러 번 요청하게 되는 것을 말한다.
기존 방식에서는 데이터를 요청할 때 엔티티 단위로 요청하게 되므로, 유저 또는 유저의 글만 가져올 수 있다.
유저에 대한 상세 정보와 해당 유저가 작성한 글이 필요하다고 해보자. REST를 사용하는 상황에서는 다음과 같이 요청해야 한다.
GET /users/1GET /users/1/posts
Data over-fetching
반대로, Data over-fetching은 필요한 데이터 이상의 데이터를 가져오는 것을 말한다. 기존 방식은 우리가 어떤 데이터를 요청하면 필요한 것 외의 데이터를 포함해 가능한 모든 정보로 응답한다.
이전 예시를 보면, 우리가 필요한건 유저의 이름과 닉네임일 뿐이지만, 응답에는 계정 생성일과 프로필까지 넘어오는 식이다.
All-or-nothing 응답
문제는 에러가 발생 했을 때이다. 에러가 발생하면 우리는 어떤 데이터도 받을 수 없다. 즉, 데이터를 요청하면 데이터가 오거나, 아예 안 오는 둘 중 하나의 결과만 있다.
물론 HTTP 상태 코드를 통해 에러 메시지를 받긴 해지만, 요청한 데이터에 대한 내용은 없다.
일괄 처리(batch)의 어려움
복잡한 화면에서는 여러 개의 요청을 동시에 보내기도 하는데, 기존 API는 틀에서 벗어난 이런 동작을 지원하지 않는다.
대시보드로 예를 들어 보자. 클라이언트가 대시보드에서 판매와 영업 관련 데이터를 요청하면, 서버로 두 개의 분리된 요청이 가게 된다. 그리고 요청한 데이터를 받아 화면에 표시하기 전까지 기다리는 동안 애플리케이션 내에서 속도가 느려지는 걸 체감하게 될 수도 있다.
GraphQL의 특징과 장점
GraphQL의 주요한 특징이자 장점은 당신이 클라이언트 쪽 앱을 만들고 백엔드 서버와 통신하면서 쿼리를 날리거나 데이터를 변경하는 방식에 대해서 완전히 새롭게 생각하도록 만든다는 것이다.
몇 가지 구체적인 예를 들자면, GraphQL은
- 클라이언트 브라우저와 서버가 데이터 통신하는데 쓰는 매우 유용한 쿼리 언어이다.
- 데이터베이스 쿼리 언어가 아닌 애플리케이션 수준의 쿼리 언어이다.
- 서버 사이드 또는 클라이언트 사이드든 상관 없이, 플랫폼에 구애 받지 않아 제공 된 환경 내에서 어떤 프로그래밍 언어(C#, Go, Java, Python, Node.js, etc)와도 잘 맞는다.
- 데이터베이스에 구애 받지 않아 필요한 hook을 사용하여 어떤 데이터베이스와도 연결할 수 있다
- 명확한 데이터 요청-응답 방식에 중점을 둔다. GraphQL 쿼리를 사용하면, 어떤 데이터/필드가 필요한 지, 어떤 입력 필터를 보내는 지 명확하게 정의 할 수 있다. 필요에 맞추어 쿼리를 객체부터 서브객체까지 구성할 수 있다.
- RESTful의 대체재로서, 당신의 앱 안에서 더 유연한 접근 데이터 방식을 제공한다.
이러한 특징을 바탕으로, GraphQL을 사용한다면 앞서 말한 기존 API가 가지고 있던 문제들을 해결할 수 있다. 데이터를 가지고 올 때, 필요한 데이터를 정확하게 요청하고 엔티티 사이의 연결을 활용해 한 번의 요청만으로 관계를 확인할 수 있다. 만약, 어떤 데이터를 가져오는 데 실패하더라도 GraphQL은 가져오는 데 성공한 데이터는 보여줄 것이다. 또한, GraphQL은 한 번의 요청을 통해 여러 개의 연산을 그룹화 하는 걸 가능하게 하고, 모든 데이터를 가져올 것이다. 이는 왕복 통신 횟수를 줄여 애플리케이션의 속도를 높일 것이다.
이러한 기능 외에도 GraphQL은 클라이언트를 위해 단일 게이트웨이를 생성하여 데이터를 가져오는 방법에 대한 팀 통신의 장애를 줄인다. 이제 API는 사용 방법 단일 엔드포인트 뒤에서 추상화 되어 어떻게 사용하는지 문서화 된 자료를 제공한다.
GraphQL로 바꾸는 방법
기존 방식에서 GraphQL로 바꾸는 마이그레이션 전략은 점진적으로 진행하면 되므로, 변화에 적응할 수 있는 준비가 다 될 때까지 현재 존재하는 데이터나 엔드포인트를 옮기기 위해서 개발 속도를 낮출 필요가 없다.
엔드포인트
커뮤니케이션의 종료 지점, URI를 의미한다.source
시작하기 전에
마이그레이션을 시작하기 전에, 몇 가지 생각할 부분이 있다. 결국 이는 새로운 기능을 추가하거나 기존 시스템을 바꾸는 것이니 말이다.
- 더 이상 새로운 REST 엔드 포인트를 생성하지 말 것
: 새로운 REST 작업을 하면, 나중에 GraphQL에서 또 해야 한다. 조금 있다가 GraphQL에서 추가하자. - 현재의 REST 엔드포인트를 유지하지 말 것
: REST 엔드포인트를 GraphQL로 옮기는 것은 간단하다. GraphQL은 훨씬 더 다양한 기능을, 당신이 정말 딱 원하는 방식대로 제공할 것이다. - 기존의 엔드포인트를 활용하여 프로토타입을 빠르게 만든다
: 기존의 REST API를 새로운 GraphQL 구현에 사용할 수 있다. 이는 지속가능한 것이 아니며, 장기간 사용할 것은 아니지만 시작하기에는 좋은 방식이다.
1. GraphQL 구현 툴을 정한다
Apoolo와 Relay는 가장 유명한 풀스택 GraphQL 솔루션이지만, 꼭 둘을 사용해야 할 필요는 없다. 직접 만들어서 쓰는 것도 괜찮기 때문이다. 무엇을 사용하든 간에 서버의 엔드포인트를 실행하고 클라이언트와 연결하는 용도로 사용하게 될 것이다. 모든 GraphQL 요청은 단일 엔드포인트를 통하기 때문에, 한 번 실행 되고 나면 엔드포인트에 연결하여 포팅 기능을 사용할 수 있다.
2. 새로 만들거나 이행할 첫 번째 기능을 정한다
예시에 맞춰서 사용자 작성 글을 이행해보자.
3. 스키마 타입을 정의한다
이제 두 가지 방법이 있다.
1) 사용자와 게시글 두 개를 같이 migrate하거나
2) 사용자에 대한 필터를 사용해서 게시글을 migrate하는 것이다.
우선 지금은 사용자 ID를 필터로 걸어서 게시글을 migrate 해보자. 먼저 스키마 내에 post 타입과 쿼리 타입을 정의 해야 한다.
type Post {
id: ID!
userId: ID!
content: String!
}
type Query {
posts(userId: ID): [Post]
}이제 우리에게는 어떤 사용자와 관련 있는 지 정보가 담긴 post 타입이 있다. 이에 더해, Posts라고 불리는 쿼리도 만들었는데, 이는 userId를 필터로 사용해서 Post 리스트를 반환한다. GraphQL에서 userId를 필드에 노출하는 것은 사실 올바른 방법은 아니다. 이보다는 게시물을 사용자와 연결하고 해당 엔티티 관계를 노출해야 하지만, 이는 API 설계 시 선택하면 된다.
4. data resolver 만들기
이제 우리의 스키마 타입과 쿼리를 데이터와 연결해야 한다. 이를 위해 resolver를 사용할 것이다. 아래 구문은 당신이 서버를 구현할 때까지 계속 조금씩 달라질 수 있다. 일단은 자바스크립트와 GraphQL을 쓴다고 가정할 때 다음과 같다.
const fetch = require('node-fetch');
export const resolvers = {
Query: {
post: async (obj, args, context) => {
const { API_URL } = process.env;
const { userId } = args;
if (userId){
const response = await fetch(`${API_URL}/users/${userId}/posts`);
return await response.json();
}
const responses = await fetch (`${API_URL}/posts`);
return await response.json();
},
}
};쿼리의 변수arguments로 userId가 주어지면, 사용자를 사용해서 게시글을 찾는 기존의 REST API를 따라갈 것이다. 하지만 만약 ueserId가 없다면, posts 경로를 바로 타게 될 것이다. 이제, 우리는 프론트엔드에서 다음과 같은 요청을 보내 데이터를 받을 수 있다.
query UserPosts($userId: ID!) {
posts(userId: $userId) {
id
content
}
}간단하기 때문에 node-fetch를 사용해서 예시를 보여줬는데, 사실 어떤 HTTP 라이브러리를 선택해도 상관 없다. 다만, Apollo를 사용할 때에는 이미 구축 되어 있는 RESTDataSource 라이브러리를 쓰면 편하다. 마이크로서비스 API를 처리할 수 있는 리졸버 및 GraphQL 구현 확장이 쉽기 때문이다.
5. 이후...
그래프 확장하기
데이터를 통합했기 때문에, 관련된 타입들을 연결하여 그래프를 완성하면 된다. userId를 가진Post말고도, User를 사용하면 같은 쿼리로 작성자의 상세 정보까지 가져올 수도 있다.
query UserPosts($userId: ID!) {
posts(userId: $userId) {
id
content
user {
id
avatarUrl
displayName
}
}
}하나로 통제하기
이제 스키마를 완전히 제어할 수 있는 쿼리와 타입이 있기 때문에, REST API가 아닌 코드 베이스에 의존하도록 resolver를 업데이트하고 성능을 추가할 수 있다. 이런식으로 계속 타입을 추가하고 API를 확장할 수 있다.
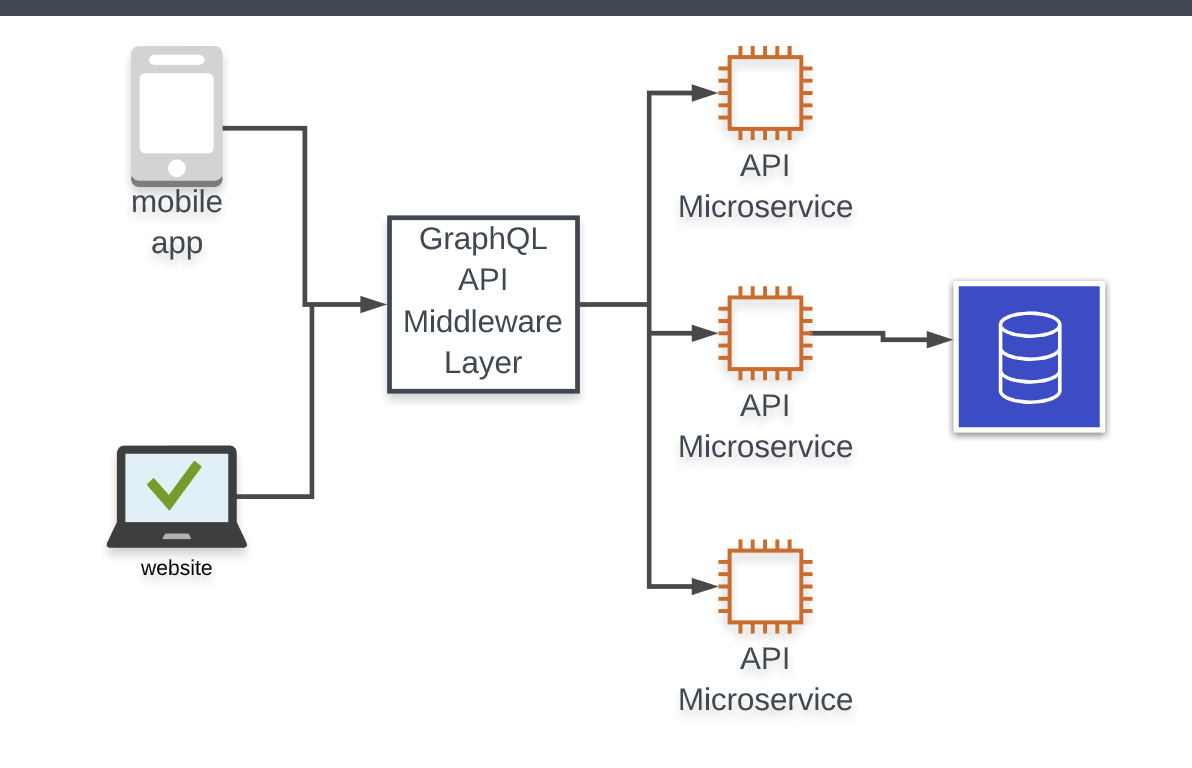
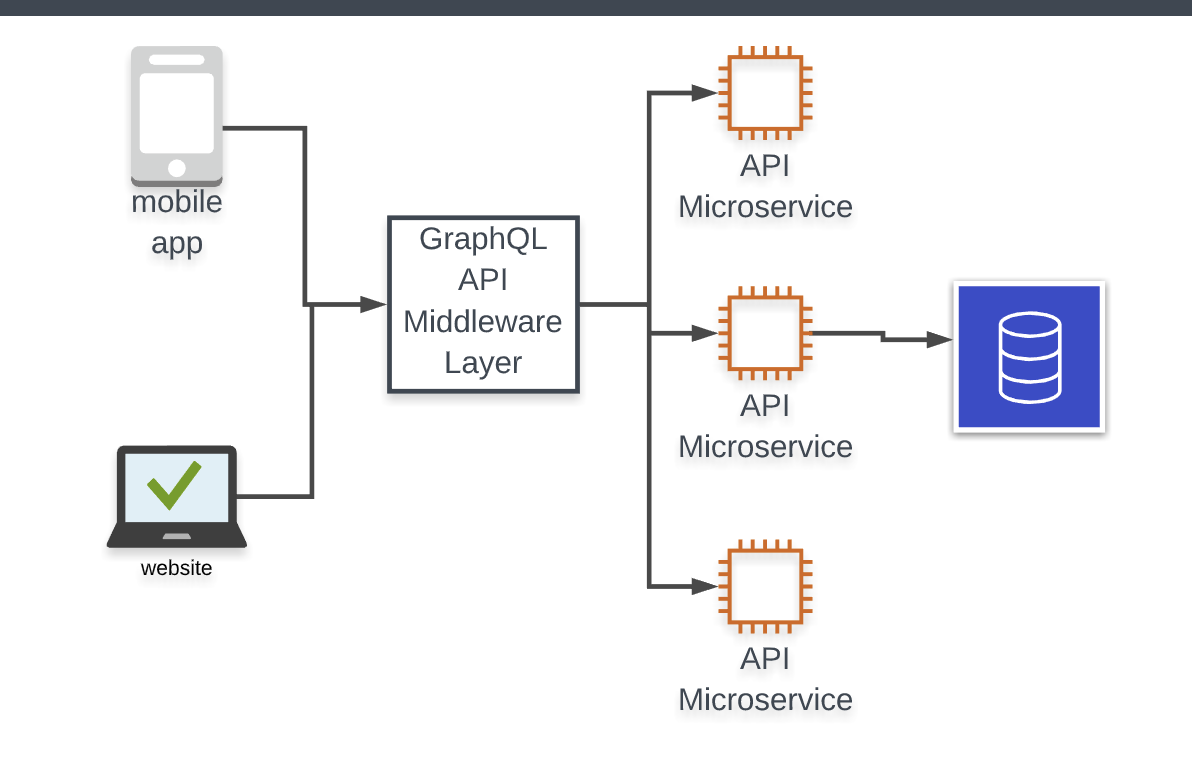
마이크로서비스
GraphQL과 마이크로서비스는 꽤 잘 맞는 조합이다. GraphQL은 스키마 스티칭을 지원하므로 마이크로 서비스에서 각각의 GraphQL API를 만들고, 이를 결합해 더 큰 인터페이스를 만들 수 있다. 즉, 클라이언트가 모든 서비스들에 대한 각각의 연결을 정의하고 이해할 필요 없이, 모든 데이터가 어디서 모이고 어떻게 처리해야 프론트엔드가 요구한 것을 충족 시킬 수 있는지 GraphQL 서버에서 알아서 이해하고 처리할 것이다.
성능
GrapQL의 최대 단점은 서버 사이드 overfetching 또는 n+1 문제이다. 왜냐하면 GraphQL은 실제 데이터가 DB 내에서 어떻게 구성되어 있는지 정확하게 알지 못하기 때문에 그래프 트리의 중복 요청을 최적화할 수 없기 때문이다. 하지만, GraphQL DataLoader를 이용하면 이미 가져온 데이터와 다음 하위 쿼리에 사용할 캐시를 결정하여 이 문제를 해결 할 수 있다.
결론
이러한 장점을 생각하면 GraphQL의 인기가 날로 높아지는 것은 당연하다고 볼 수 있다. 하지만, GraphQL이 무조건 모두를 만족시킬 수 있는 것은 아니다. 하지만, 앞으로 우리가 의존하는 많은 API가 GraphQL을 활용하기 시작할 것이며, 기존의 REST API에서 벗어나는 방향으로 갈 것이라고 본다.
단어
- agnostic: 불가지론의, ~에 구애 받지 않는
- dedicate: 헌신하다, 전념하다
- implementation: 이행, 실행
