Kubernetes in Action, Second Edition MEAP V15 정리중
Kubernetes란?
기반이 되는 hardware들 위에 abstraction layer를 제공하여 이용자들이 low-level에 신경쓰지 않고 프로그램을 쉽게 deploy하도록 도와주는 프레임워크
아래의 사진에서 나와있듯이 개발자는 application을 networt나 computer에 대한 고려 없이 Kubernetes level 위에서 실행시킬 수 있다.
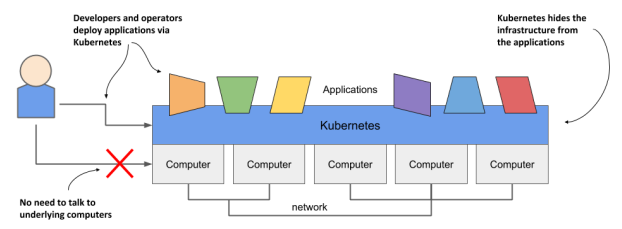
Kubernetes는 declarative model을 사용하는데, 실행하고자 하는 application을 잘 서술해주면 내부에서 이것을 실행시켜준다. 또한 reconfigure이나 restart등의 기능도 제공한다.
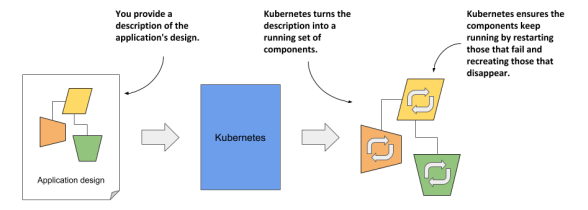
Kubernetes는 왜 필요한가?
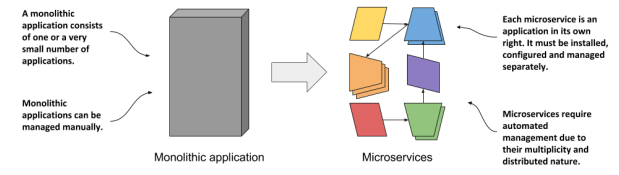
1. Microservices
기존의 Monolithic application ->
하나의 쪼갤 수 없는 단위, horizontally scaling(여러 대의 컴퓨터로 실행하는 것) 불가능
Microservices로 옮겨가며 application을 분할할 필요성 증가
but) Microservices의 경우 여러 OS의 여러 버전의 library를 관리하기 까다로움
-> 분산 컴퓨팅 프레임워크
2. DevOps Paradigm
DevOps란 ?
소프트웨어를 만드는 development team과 완성된 제품을 가지고 deploy하는 management team으로 나뉘는 구조
Kubernetes를 사용하면 더 실시간으로 소프트웨어를 개선시킬 수 있다.
3. Cloud화 진행
기존의 local에 있었던 코드는 옮기는데 비용 많이 듦 -> 코드를 cloud에 배포
Kubernetes API를 통해 AWS, Google Cloud등 여러 Cloud에 쉽게 접근 가능
Kubernetes 이해하기
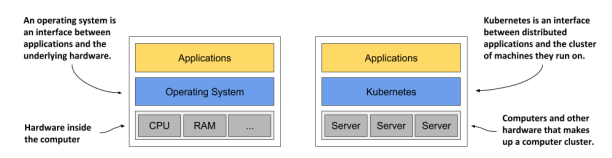
Kubernetes와 OS의 비교)
OS가 Scheduler를 통해 CPU를 할당해 주고 interface를 지원해 주는 것처럼 Kubernetes는 Server들을 Scheduling해 주고 interface를 제공해 사용자가 다음과 같은 infrastructure를 몰라도 되도록 해준다.
Infrastructure (Kubernetes의 주 기능)
service discovery - 어떤 application이 다른 application의 서비스를 이용하게 해주는 것
horizontal scaling - traffic이 증가했을 때 application의 개수를 복제하여 부담을 분할시키는 것
load-balancing - 복제된 application의 load(부담)이 치우치지 않게 해주는 것
self-healing - application이 죽었을 때 자동으로 restart해주고 healty node로 옮겨주는 것
leader election - 어떤 instance를 active시킬지, active된 instance가 죽었을 때 어떤 instance로 옮겨갈 것인지 설정
Kubernetes상에서 machine은 크게 Master node, Worker node 2가지로 나뉘어진다.
Master node - system과 cluster들을 제어, 보통 최소 3개는 필요함.
Worker node - application을 실행하는 machine으로 application의 개수를 맞춰간다.
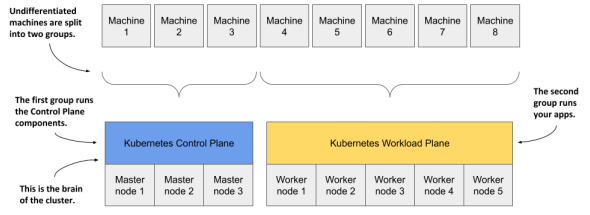
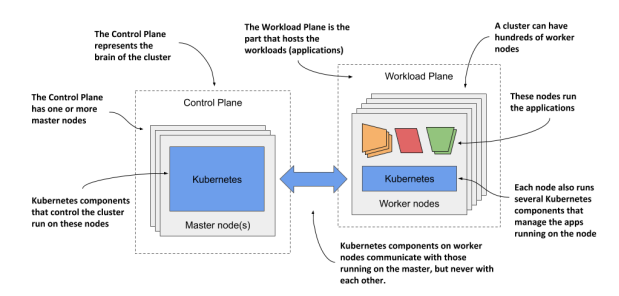
Kubernetes 프레임워크가 만들어지면 Kubernetes 내부에서 자동으로 application을 적절한 node들로 배치하고 이동시켜 주므로, 유저는 Control Plane에서 제공하는 Kubernetes API만으로 Workload Plane의 application을 제어할 수 있게 된다.
Cluster
Cluster란, Control plane과 Workload Plane이 모여서 만들어진 큰 단위이다.
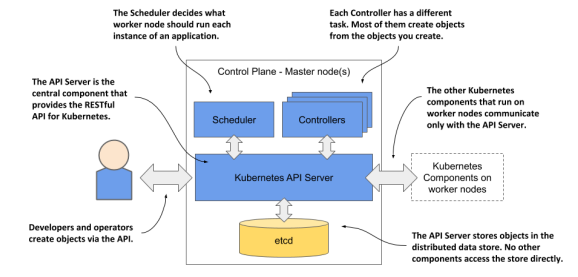
Control plane
API Server - REST API형식으로 요청을 받아서 object를 생성한다.
etcd - API를 통해 만든 object들을 persistent datastore에 저장한다. why? API Server 자체는 stateless하기 때문
Scheduler - 어떤 application을 어떤 worker node에서 실행할 것인지 결정한다.
Controllers - 생성된 object을 관리한다.
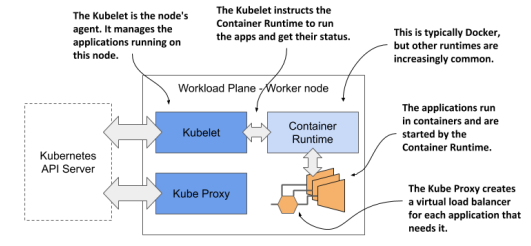
Worker node
Kubelet - API Server와 통신하고 application과 node의 상태를 감시하고 관리한다.
Container Runtime - Kubelet에 지시를 받아 application을 실행한다. 일반적으로 Docker같은 것.
Kube Proxy - application들 사이의 network traffic을 load-balance 해준다.
Add-on
DNS 서버, 네트워크 플러그인, 로그 기록들을 추가한다. 보통 Worker node에서 실행된다.
Kubernetes 작동 방식
Kubernetes에서는 object를 기본 단위로 한다. 하나의 소프트웨어에는 deployment하는 object, instance running 하는 object, 서비스를 나타내는 object등 다양한 object들이 있다.
전체 object들의 description은 yaml이나 json으로 관리된다. 이것들은 보통 kubetcl(K8s의 cli)로 object단위로 쪼개지고, PUT이나 POST 요청으로 API서버에 전해진다.
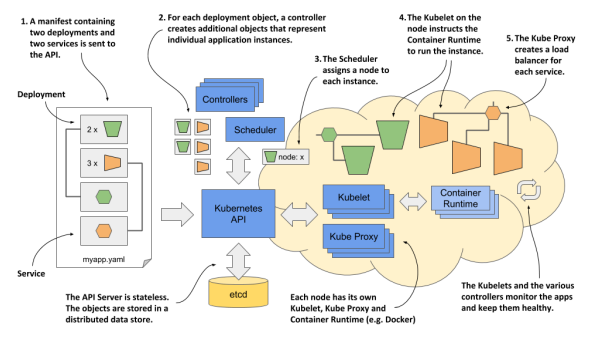
Kubernetess 내부 과정
- object들의 정보를 담은 application menifest를 API서버에 보낸다. API서버는 이것을 etcd에 저장한다.
- 각 type에 object에 대응하는 Controller가 새로운 object들을 실제로 생성한다.
- Scheduler가 object들을 node에 할당한다.
- object가 할당된 node의 Kubelet이 Container Runtime에게 instance(할당된 object)를 실행시킨다.
- Kube proxy가 instance가 사용 준비됨을 알리고 load-balancing 한다.
- Kubelet과 Controller가 시스템을 정상적으로 돌아가도록 관리한다. 또한 주기적으로 상태를 알려준다.
Kubernetes 사용 상황
On-Premises - 로컬로 시스템 작동, HPA하기 힘들다.
Cloud - Cloud 서버로 시스템 작동, HPA 유연하다.
Hybrid - 평소에는 로컬로 저장, peak일 때 instance추가로 받는다
