DAG의 복잡한 Dependency
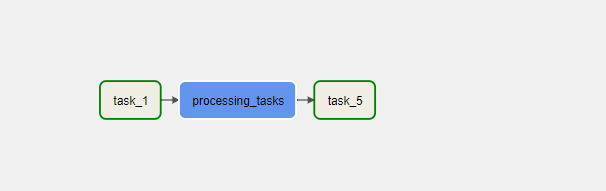
에어플로우 작업을 하다보면 그래프 뷰를 볼 때 매우 흔하게 볼 수 있는 아래와 같은 상황이다.
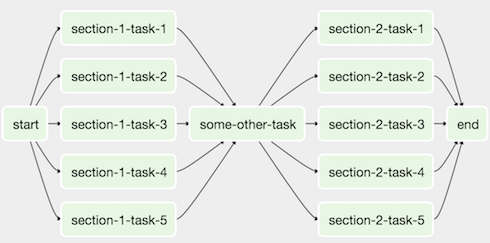
우리는 아래와 같이 저 그래프를 보다 쉽고 간단하게 볼 수는 없을까?
start > section1 > some_taask > section2 > end
이렇게 병렬적으로 수행되는 작업들을 한번에 묶어서 말이다.
실제로는 잘 사용하지 않는 Sub DAG
강조 할 점!!!!
우리는 절대 sub Dag를 쓰지 않고 앞으로도 쓰지 않을 것입니다.
왜나하면 해당 프로세스는 이점에 비해 많은 단점이 존재하기 때문입니다. 따라서 해당 내용은 그냥 이런게 있구나 정도만 하고 넘어가시면 됩니다.
Sub DAG란 main dag 안에서 정의하여 task들을 묶어서 하나의 task처럼 보이게 할 수 있는 operator이다.
백날 말로만 설명하는 것보다 눈으로 보고 직접 해보는 것이 좋으니 직접 해보자.
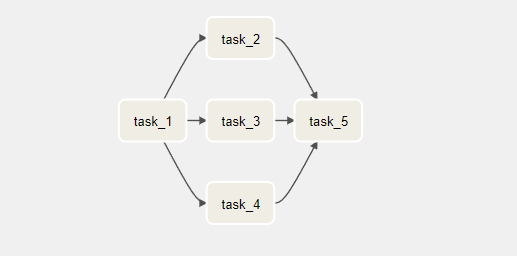
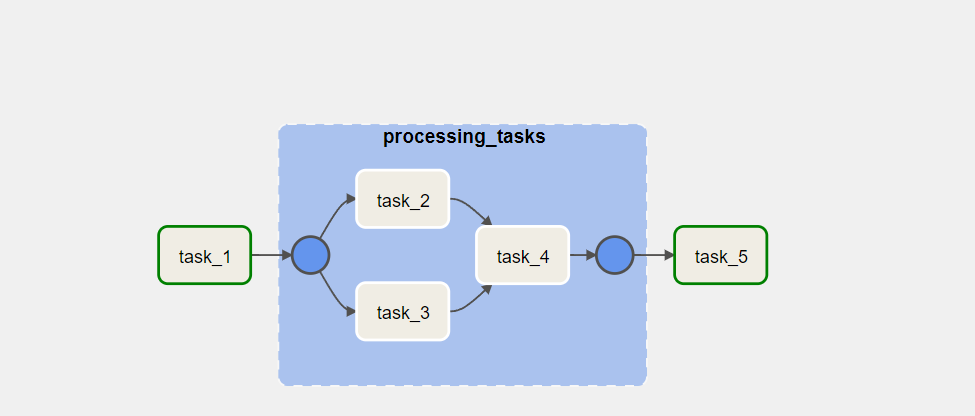
우리는 위와 같은 dag를 갖고 있다고 가정해보자.
그렇다면 우리는 task2, 3, 4를 하나의 sub dag로 묶을 수 있을 것이다.

from airflow.operators.subdag import SubDagOperator 를 통해 해당 오퍼레이터를 불러 오자.
그리고 해당 오퍼레이터를 사용한 processing 이라는 sub_dag를 만들어주자.

그리고 subdag에 우리가 묶으려한 task들을 dag로 만들어서 넣어주면 된다.
이제 묶으려한 task들을 sub_dag로 묶어보자.
유의할 점은 default_args를 같이 넘겨야한다는 점이다.
from airflow import DAG
from airflow.operators.bash import BashOperator
def sub_dag_parallel(parrent_dag_id, child_dag_id, default_args):
with DAG(
dag_id=f'{parrent_dag_id}.{child_dag_id}',
default_args=default_args,
description='parallel_dag_subdag'
) as dag:
task2 = BashOperator(
task_id='task_2',
bash_command='sleep 3'
)
task3 = BashOperator(
task_id='task_3',
bash_command='sleep 3'
)
task4 = BashOperator(
task_id='task_4',
bash_command='sleep 3'
)
return dag
위는 사용자 정의 함수를 통해 subdag를 정의하고 task들을 할당하여 하나의 dag를 생성했다.
그리고 이러한 함수를 subdag args로 넘겨주면 된다.
방법은 아래와 같다.
먼저 우리가 정의한 함수를 임포트 해준 뒤 아래와 같이 인수들을 넘겨주면 된다.
processing = SubDagOperator(
task_id="processing_tasks",
subdag=sub_dag_parallel("parallel_dag", "processing_tasks", default_args=default_args)
)

메인 dag 파일은 아래와 같다.
from airflow import DAG
from datetime import datetime
from airflow.operators.bash import BashOperator
from airflow.operators.subdag import SubDagOperator
from dags.sub_dags.sub_dag_parallel import sub_dag_parallel
default_args = {
'start_date': datetime(2022, 1, 1)
}
with DAG('parallel_dag',
default_args=default_args,
schedule_interval="@daily",
catchup=False) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='sleep 3'
)
processing = SubDagOperator(
task_id="processing_tasks",
subdag=sub_dag_parallel("parallel_dag", "processing_tasks", default_args=default_args)
)
task5 = BashOperator(
task_id='task_5',
bash_command='sleep 3'
)
task1 >> processing >> task5
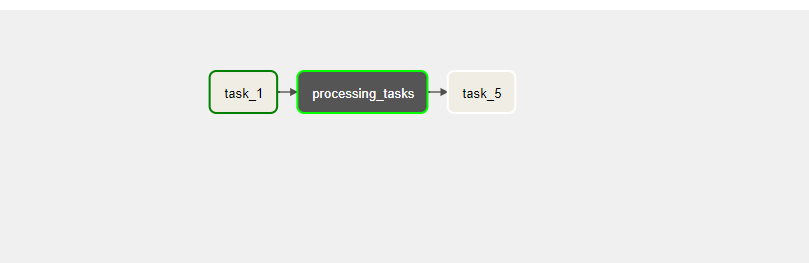
정상적으로 수행이 되는 모습이다.
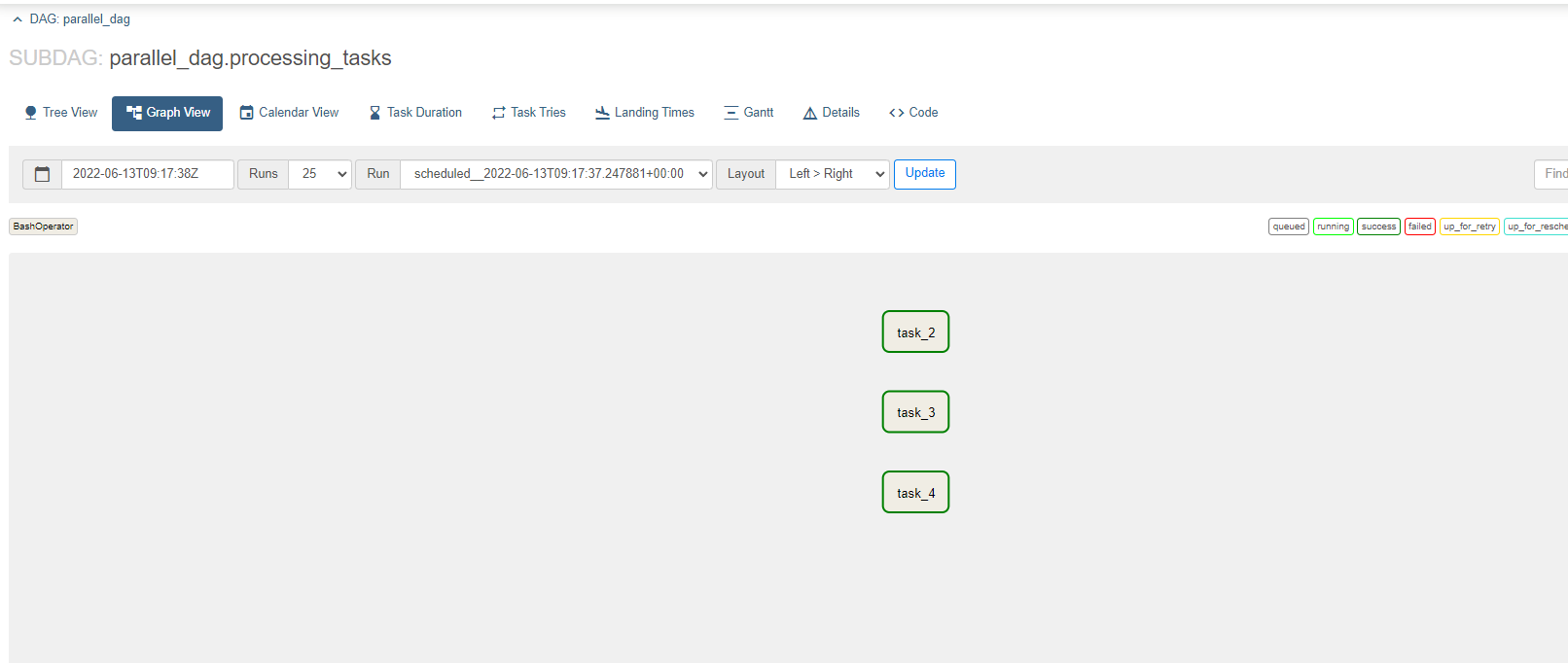
subdag들도 정상적으로 수행된 모습이다.
이처럼 subdag를 이용하면 비슷한 맥락의 task들을 묶어 추상화할 수 있다.
SubDAG의 단점
-
deadlock: 교착상태
하나의 task가 끝나기만을 기다리고 있고, 해당 task도 다른 task가 끝나기만을 기다리고 있다. 이런 상태를 deadlock이라고 한다.
subdag를 활용하면 교착상태에 빠지기 쉽다. -
complexity: 복잡성 문제
subdag를 활용하면 dag 폴더안에 subdag 폴더를 만들고 해당 파일을 만들어 다시 함수를 만들고 해당 함수를 main dag에 import 해야만 한다. 그리고 여러가지 인수들을 다시 넣어줘야 한다.
우리는 단순한 케이스라 저렇게 가능했지 복잡하게 엉켜있는 파이프라인에서 저렇게 하면 많이 복잡할 것이다. -
executor: 각기 다른 executor
subdag는 sequencial executor를 사용한다. 우리가 디폴트로 로컬 익스큐터를 사용한다고 하더라도.... 때문에 해당 프로세스는 많이 느리다.
따라서 위와 같은 이유로 우리는 subdag를 사용하지 않는다.
그럼 우리는 뭘써야 할까?
바로 taskGroup이다.
TaskGroup을 반드시 쓰자.
TaskGroup은 개념적으로 subDag와 유사하지만 단점은 모두 해결한 방법이다.
코드로 보는 것이 더 직관적으로 다가온다.
with DAG('parallel_dag',
default_args=default_args,
schedule_interval="@daily",
catchup=False) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='sleep 3'
)
with TaskGroup(group_id='processing_tasks') as processing_tasks:
task2 = BashOperator(
task_id='task_2',
bash_command='sleep 3'
)
task3 = BashOperator(
task_id='task_3',
bash_command='sleep 3'
)
task4 = BashOperator(
task_id='task_4',
bash_command='sleep 3'
)
[task2, task3] >> task4
task5 = BashOperator(
task_id='task_5',
bash_command='sleep 3'
)
task1 >> processing_tasks >> task5우리는 taskgroup 그냥 main dag에 임포트한 다음 쓰기만 하면 된다.
taskgroup 안에 taskgroup 집어 넣기
task 그룹안에 또 task 그룹을 집어 넣을 수 있다.
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.subdag import SubDagOperator
from airflow.utils.task_group import TaskGroup
from datetime import datetime
default_args = {
'start_date': datetime(2022, 1, 1)
}
with DAG('parallel_dag',
default_args=default_args,
schedule_interval="@daily",
catchup=False) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='sleep 3'
)
with TaskGroup(group_id='processing_tasks') as processing_tasks:
task2 = BashOperator(
task_id='task_2',
bash_command='sleep 3'
)
with TaskGroup(group_id="spark_tasks") as spark_task:
task3 = BashOperator(
task_id='task_3',
bash_command='sleep 3'
)
with TaskGroup(group_id="flink_tasks") as flink_tasks:
task4 = BashOperator(
task_id='task_4',
bash_command='sleep 3'
)
task4 = BashOperator(
task_id='task_4',
bash_command='sleep 3'
)
task2 >> task4
[spark_task, flink_tasks] >> task4
task5 = BashOperator(
task_id='task_5',
bash_command='sleep 3'
)
task1 >> processing_tasks >> task5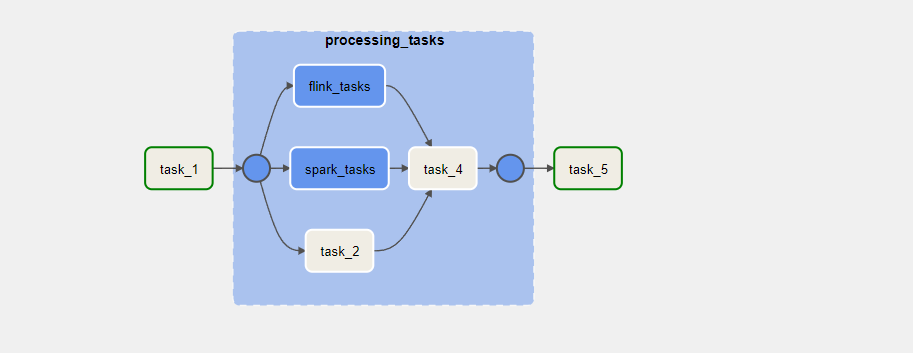
이처럼 task group은 간단하면서도 강력하고 빠르게 DAG를 추상화 하면서 작성할 수 있다.
마지막으로 진짜 꿀팁
태스크 그룹을 사용하면 task_id가 자동으로 {group_id}.{task_id} 로 할당이 된다. 때문에 task id를 적절하게 잘 사용하자.
