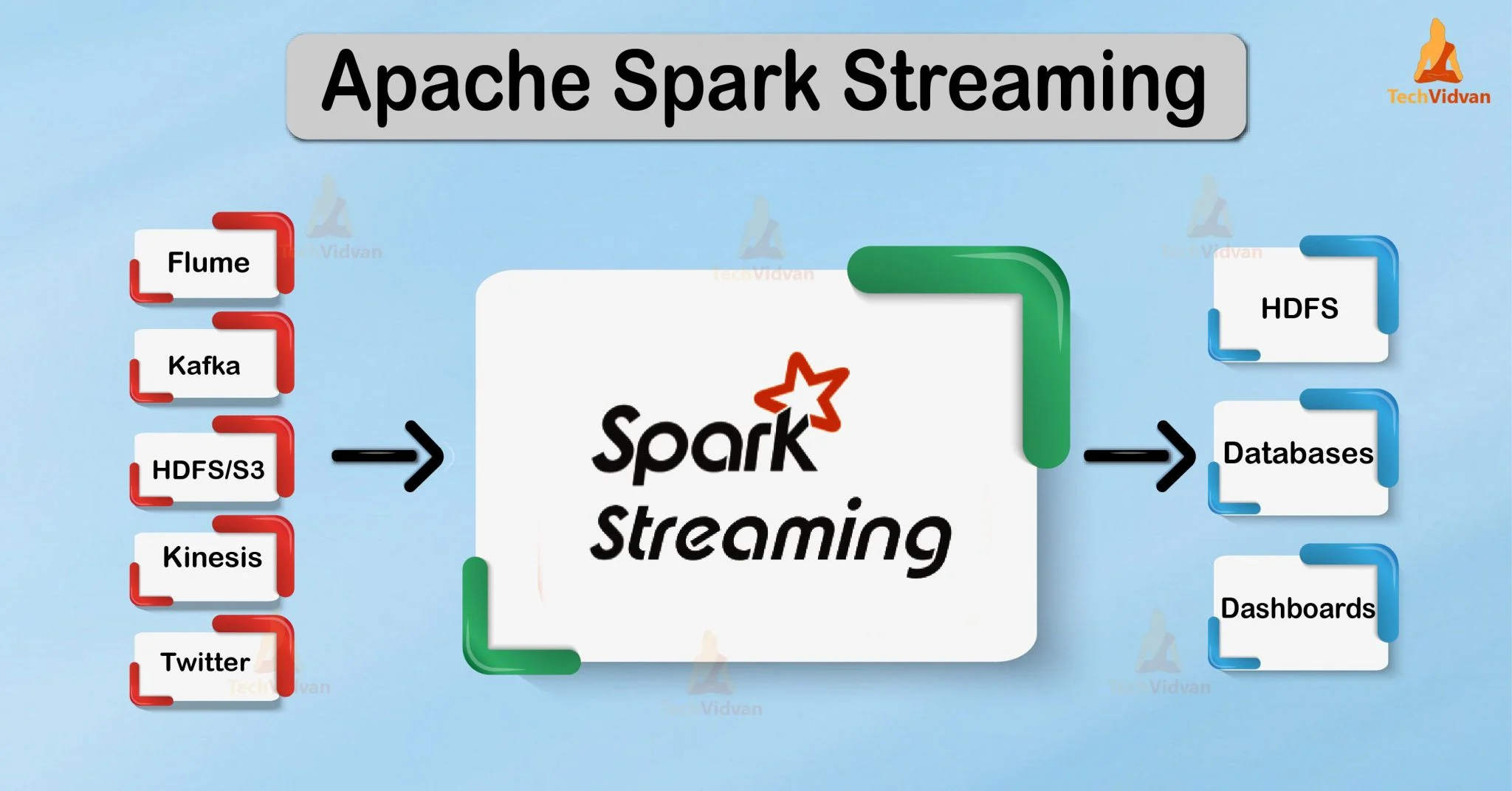
Spark Streaming 왜 필요할까?
실제 서비스 단계에서 데이터는 계속해서 발생하고 그러한 데이터를 저장해서 의미 있는 데이터로 만드는 것은 중요한 일이다. 하지만 그러한 데이터를 의미 있게 만들기 위해서는 많은 시간이 발생한다. 스트리밍 데이터 처리 방식은 몇가지만 포기한다면 다양한 장점을 보여주는 처리 방식이다.
구체적으로 살펴보자.
구조적 스파크 스트리밍
스파크는 기존부터 스트리밍 데이터 처리에 대한 프레임워크를 제공하고 있었다. 하지만 기존 방법은 RDD 기반으로 구조적이지 못했다.
Strectured! 이 단어는 CS를 공부하는 사람이라면 대부분 SQL을 통해서 많이 보았을 것이다.
그렇다. RDD와는 달리 DATAFRAME, DATASET으로 SQL 방식으로 데이터를 처리할 수 있다.
(물론 기존 방법도 RDD에서 DATAFRAME으로 바꿔서 진행할 수 있었지만 매우 번거로웠다.)
또한 기존 방법과는 달리 다양한 집계함수들을 사용하여 실시간으로 데이터를 집계할 수 있으며 단 한번 내결함성을 보장한다.
프로그래밍 핵심 아이디어
핵심 아이디어는 데이터는 테이블의 경계가 없이 데이터가 아래에 계속 추가되는 상태를 유지하는 것이다.
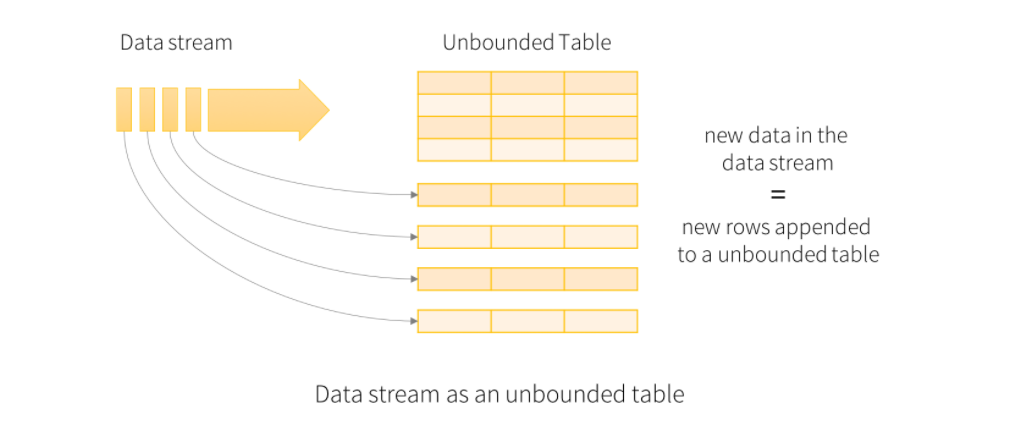
RAW > RESULT TABLE > OUTPUT
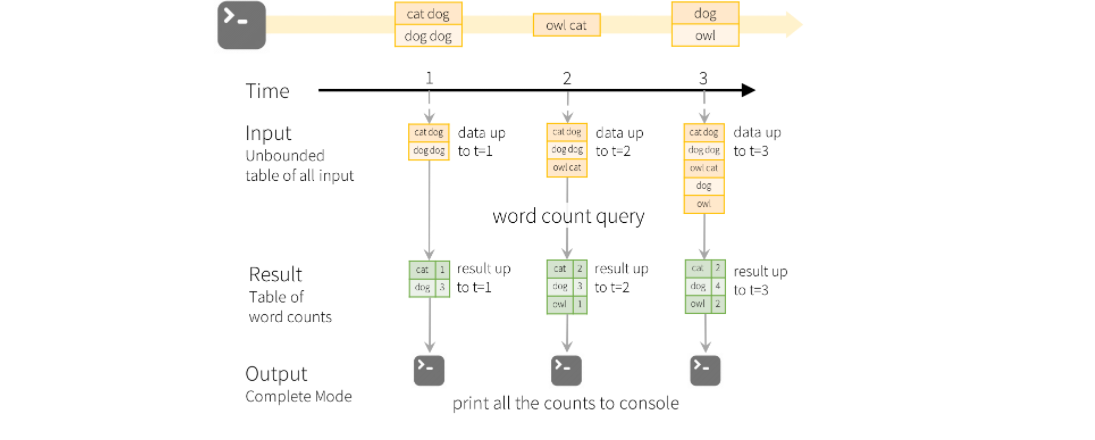
위의 자료는 스트리밍 처리 과정의 전부라고 볼 수 있을 정도로 핵심적인 내용이다.
원자료를 받아오고 해당 자료들을 우리가 넣은 쿼리나 스키마의 형태로 다시 정리하고 해당 결과를 우리가 지정한 형식으로 외부 저장소에 저장하거나 출력한다.
원자료는 받아놓은 후 집계테이블을 업데이트 하는데 사용한 뒤 바로 버려진다.
스파크는 기본적으로 메모리 기반 프레임워크 이기 때문에 적절한 메모리 상태를 유지하는 것이 핵심이다. (GC를 튜닝하는 방법도 존재한다.)
출력 방식은 3가지가 존재한다.
-
전체 모드 - 업데이트된 전체 결과 테이블이 외부 저장소에 기록된다. 전체 테이블의 쓰기를 처리하는 방법을 결정하는 것은 스토리지 커넥터(HDFS, S3, GS등)에 달려 있다..
-
추가 모드 - 마지막 트리거 이후 결과 테이블에 추가된 새 행만 외부 저장소에 기록된다. 이는 결과 테이블의 기존 행이 변경되지 않을 것으로 예상되는 쿼리에만 적용된다.
-
업데이트 모드 - 마지막 트리거 이후 결과 테이블에서 업데이트된 행만 외부 저장소에 기록된다.(Spark 2.1.1부터 사용 가능). 이 모드는 마지막 트리거 이후에 변경된 행만 출력한다는 점에서 완료 모드와 다르다. 쿼리에 집계가 포함되지 않은 경우 추가 모드와 동일하다.
스파크 스트리밍의 몇가지 특징
-
데이터셋과 데이터프레임을 이용한다.
다양한 SQL 함수 및 집계함수 사용이 실시간 데이터에 적용이 가능하다. -
이벤트 시간 및 지연 데이터 처리가 가능하다.
워터 마킹을 도입해서 지연 데이터를 처리하는 방식이 존재한다.
또한 윈도우 형식을 사용해 데이터의 범위를 지정할 수 있다.
워터 마킹이란 지연가능한 임계 시간을 설정하는 것
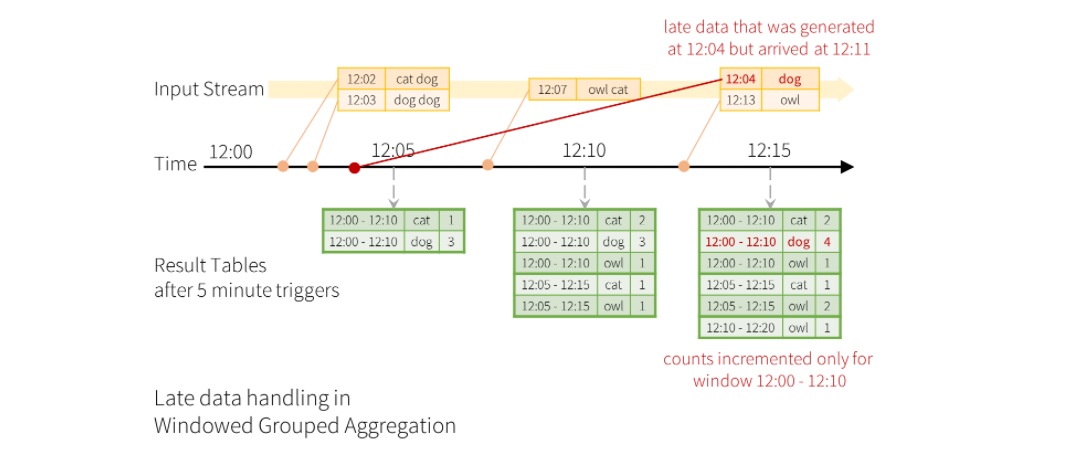
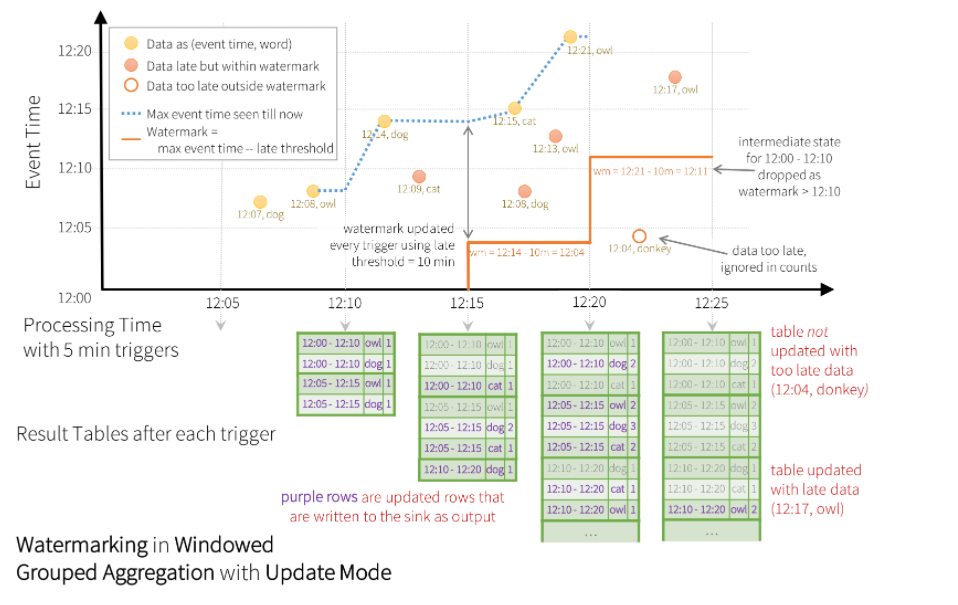
- 내결함성을 1회 보장한다.
스트리밍 처리상 해당 프로세스의 완벽성을 보장하지는 못한다. 하지만 스파크 스트리밍은 진행상황 등을 꾸준히 추적하여 재시작 또는 재처리를 통해 오류상황을 처리하여 내결함성을 1회 보장한다.
또한 스파크 엔진은 체크포인트, write-ahead logs 등을 사용하여 처리중인 데이터의 오프셋 범위를 기록한다. 또한 재처리 가능성 때문에 스트리밍 싱크는 멱등성을 갖추기 위해 설계되었다.
때문에 어떠한 문제가 발생하여도 한번의 내결함성을 보장한다.
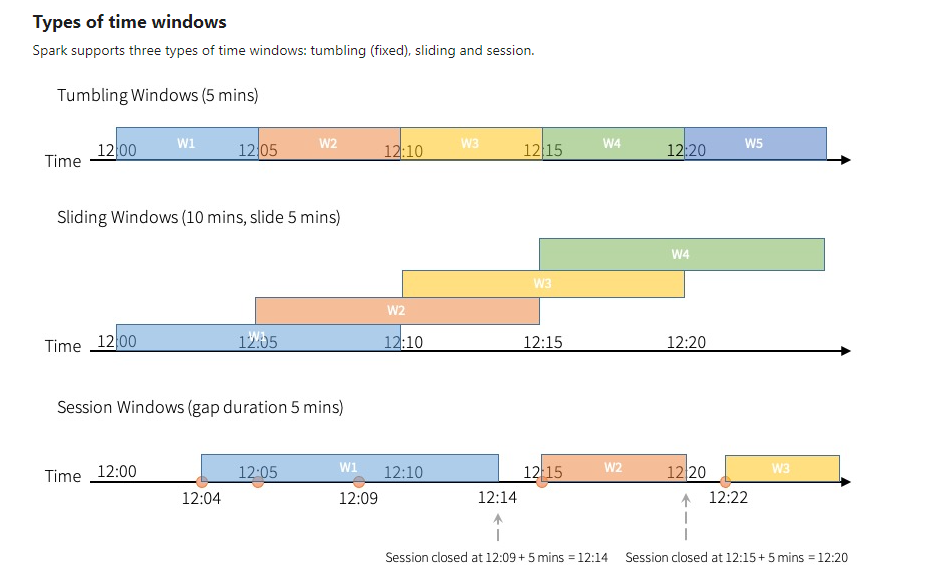
윈도우 구성방식
아래의 이미지를 보는게 더 빠르다.
스트리밍 중복 제거
이벤트의 고유 식별자를 사용하여 데이터 스트림의 레코드를 중복 제거할 수 있다. 이는 고유 식별자 열을 사용하는 정적 중복 제거와 정확히 동일하다. 쿼리는 중복 레코드를 필터링할 수 있도록 이전 레코드에서 필요한 양의 데이터를 저장한다.
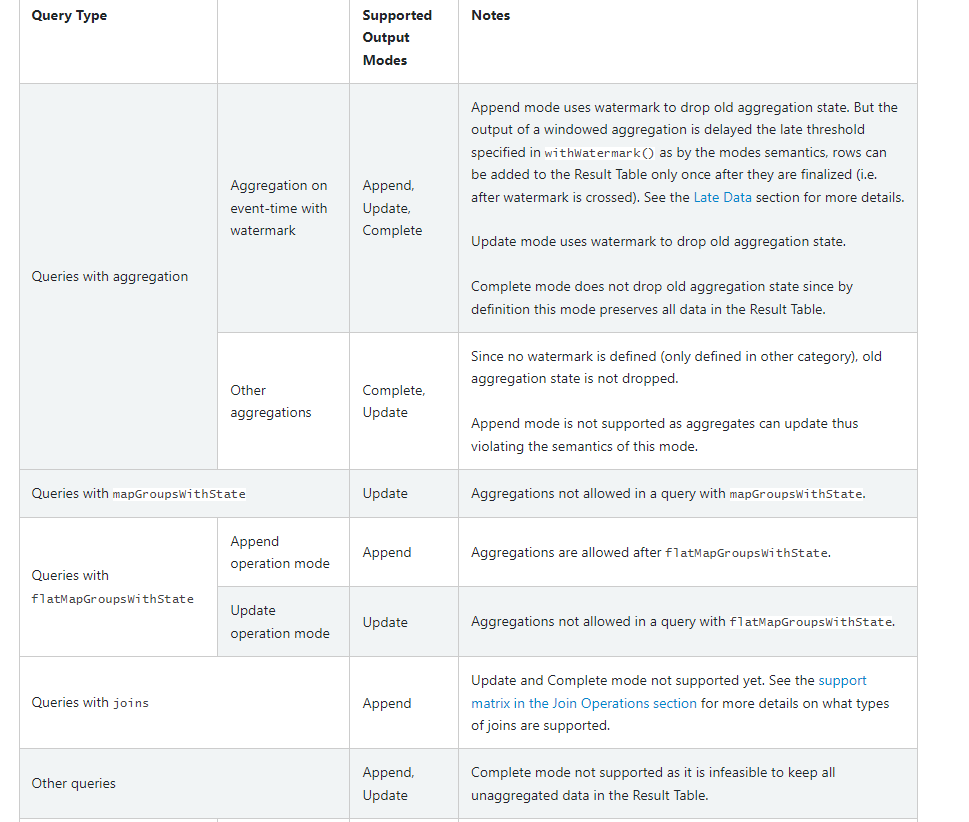
출력방식 지정
-
추가 모드(기본값) - 마지막 트리거 이후 결과 테이블에 추가된 새 행만 싱크로 출력되는 기본 모드다. 이는 결과 테이블에 추가된 행이 절대 변경되지 않는 쿼리에 대해서만 지원된다.(AGG 함수를 사용할 때 제약이 존재한다.)
따라서 이 모드는 각 행이 한 번만 출력되도록 보장한다.(내결함성 싱크 가정). 구체적으로 구성 가능한 쿼리는 select, where, map, flatMap, filter, join 등이 가능하다. -
완료 모드 - 모든 트리거 후에 전체 결과 테이블이 싱크로 출력된다. 이는 집계 쿼리에 대해 지원이 가능하다.
-
업데이트 모드 - ( Spark 2.1.1부터 사용 가능 ) 마지막 트리거 이후 업데이트된 결과 테이블의 행만 싱크로 출력된다.
아래에 가능한 쿼리들의 종류들이 있으니 참고하자.
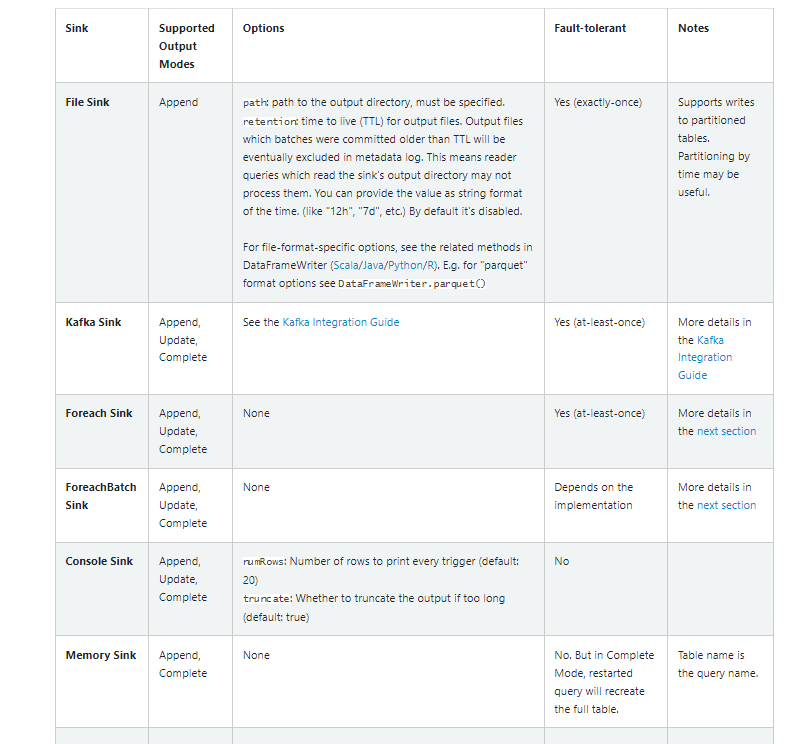
출력 싱크 지정
-
파일 싱크 - 출력을 디렉터리에 저장
-
Kafka 싱크 - 출력을 Kafka의 하나 이상의 주제에 저장
-
Foreach 싱크 - 출력의 레코드에 대해 임의 계산을 실행
-
콘솔 싱크(디버깅용) - 트리거가 있을 때마다 콘솔에 출력
append, compelete, update 모드가 모두 지원된다. 이것은 모든 트리거 후에 전체 출력이 수집되고 드라이버의 메모리에 저장되기 때문에 낮은 데이터 볼륨에서 디버깅 목적으로 사용되어야만 한다. -
메모리 싱크(디버깅용) - 출력은 메모리 내 테이블로 메모리에 저장. append, compelete, update 모드가 모두 지원된다. 이것은 전체 출력이 수집되고 드라이버의 메모리에 저장되기 때문에 낮은 데이터 볼륨에서 디버깅 목적으로 사용되어야만 한다.
리뷰를 마치며
스파크 스트리밍을 도입하기 위해서 꾸준히 공부하고 복습하면서 리뷰를 진행해보았다.
확실히 스파크 스트리밍은 중복성이나 내결함성을 보장한다고는 하지만 스트리밍 처리상 위와 같은 문제를 완벽히 대처할 수는 없다. (데이터가 매우 늦게 도착하는 경우, 동일한 데이터가 보내지는 경우)
그럼에도 불구하고 스트리밍 처리는 우리가 빠르게 생성되는 데이터에서 실시간으로 인사이트를 뽑아내거나 서비스를 개선하는데 많은 도움이 될 수 있다고 생각한다.
내가 진행하는 프로젝트에서도 많은 도움이 될 것이라고 생각하면서 글을 마친다.

참조
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
https://cloud.google.com/dataproc/docs/concepts/connectors/cloud-storage
https://cloud.google.com/dataproc/docs/tutorials/gcs-connector-spark-tutorial
