정렬이 중요한 이유
컴퓨터 과학에서 정렬이 차지하는 비중은 매우 크다. 프로그램에서 데이터를 가공할 때 어떠한 기준에 맞춰서 정렬하는 경우가 대다수이기 때문이다.
또한 기존에 뒤죽박죽된 데이터를 정렬한다면 추후 이진탐색이 가능하게 된다.
정렬의 종류
정렬의 종류는 광장히 많다. 선택, 삽입, 버블, 힙, 분할, 퀵, 계수 정렬등등이 많지만 여기서는 선택 삽입 퀵 계수만 다른다.
선택정렬
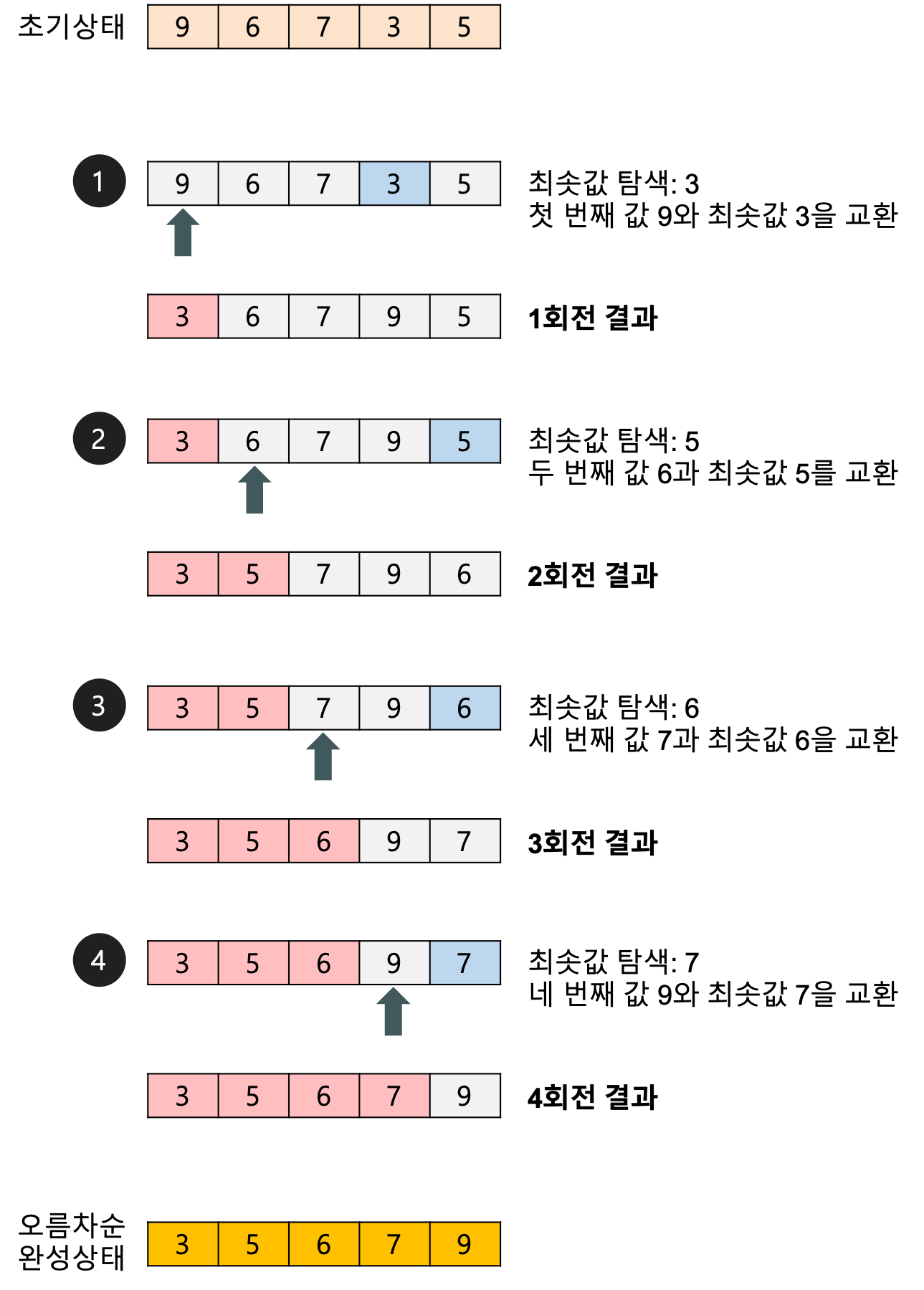
선택정렬은 굉장히 원시적인 알고리즘이다.
작동 과정은 아래와 같다.
- 처음 시작할 때 가장 작은 것을 맨앞 원소로 지정한다.
- 다음 가장 작은 것을 선택한다.
- 처리되지 않은 가장 앞에 있는 원소와 위치를 바꾼다.
- 2, 3 과정을 반복한다.
파이썬 코드로 위의 내용을 구현하면 아래와 같다.
def sel_sort(array):
for i in range(len(array)): # 처음 원소부터 시작
min_idx = i
for j in range(i+1, len(array)): # 다음 원소부터 차례로 탐색
if array[min_idx] > array[j]: # 최소값 보다 작은 녀석이 있다면 다른 녀석으로 교체
min_idx = j
array[i], array[min_idx] = array[min_idx], array[i] # 작은 포문이 끝나면 해당 값끼리 위치 변경
return array 시간 복잡도는 O(N^2)
총평: 약간 brute force에 가까운 야만적인 방법이다. 코테에 사용하기엔 아쉬운 녀석
삽입정렬
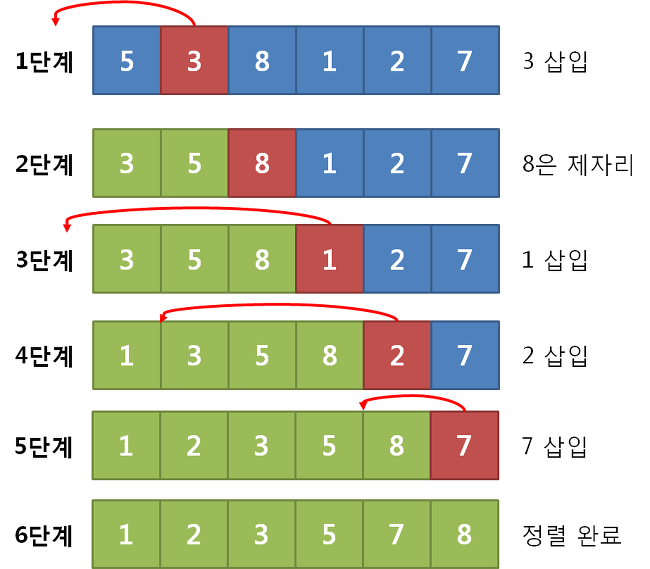
삽입 정렬은 특정한 조건에서 엄청난 능력을 보여주는 알고리즘이다.
특정한 조건은 데이터가 거의 정렬이 되어있다는 조건에서 실행시간이 매우 단축된다.
작동과정은 아래와 같다.
- 처음 원소를 가장 작은 원소로 지정한다.
- 다음 원소를 선택 후 앞에 정렬되어 있는 수들과 비교한다.
- 자기보다 크면 해당 수와 비교하며 앞으로 전진한다.
- 자기보다 작은 수가 나오면 해당 자리에서 멈춘다.
- 2, 3, 4 과정을 반복한다.
위의 과정을 파이썬 코드로 옮기면 아래와 같다.
def insert_sort(array):
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j] < array[j-1]:
array[j], array[j-1] = array[j-1], array[j]
else:
break
return array
핵심은 같게, 생각은 다르게