
본 포스팅은 파이토치(PYTORCH) 한국어 튜토리얼을 참고하여 공부하고 정리한 글임을 밝힙니다.
TORCH.AUTOGRAD를 사용한 자동 미분
- 신경망 학습할 때 가장 자주 사용되는 알고리즘: 역전파
- 매개변수(모델 가중치)는 주어진 매개변수에 대한 손실 함수의 gradient에 따라 조정됨
- 이러한 gradient를 계산하기 위한
torch.autograd: 자동 미분 엔진 ➡️ 모든 계산 그래프에 대한 변화도의 자동 계산 지원
입력 x와 매개변수 w와 b, 일부 손실 함수가 있는 가장 간단한 단일 계층 신경망(single layer)을 가정
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w) + b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)Tensor, Function과 연산그래프(Computational graph)
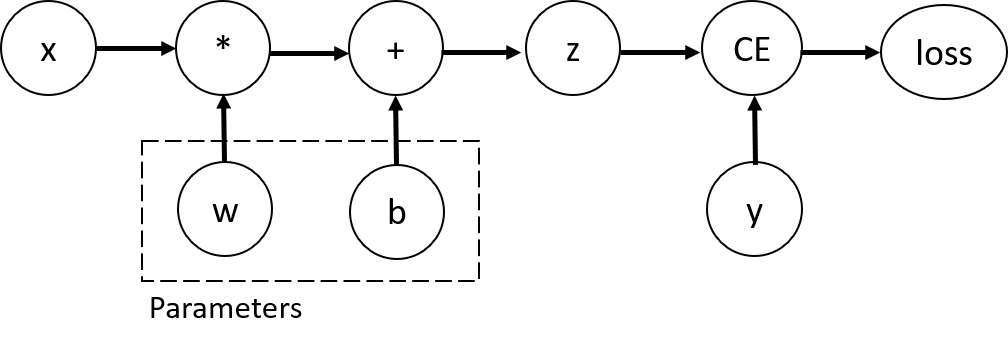
- w, b는 최적화 해야 하는 매개변수 ➡️ w, b에 대한 손실 함수의 gradient 계산
- 이를 위해 해당 텐서에
requires_grad속성 설정 - 역방향 전파 함수에 대한 참조(reference)는 텐서의
grad_fn속성에 저장
print(f"Gradient function for z = {z.grad_fn}")
print(f"Gradient function for loss = {loss.grad_fn}")변화도(Gradient) 계산하기
- 매개변수의 가중치 최적화를 위해 매개변수에 대한 손실 함수의 도함수 게산
- 도함수 계산을 위해
loss.backward()를 호출한 다음w.grad와b.grad에서 값을 가져옴
loss.backward()
print(w.grad)
print(b.grad)Out:
tensor([[0.0970, 0.2870, 0.2443],
[0.0970, 0.2870, 0.2443],
[0.0970, 0.2870, 0.2443],
[0.0970, 0.2870, 0.2443],
[0.0970, 0.2870, 0.2443]])
tensor([0.0970, 0.2870, 0.2443])
requires_grad속성이 True로 설정된 노드들의 grad 속성만 구할 수 있음- 성능 상의 이유로, 주어진 그래프에서의
backward를 사용한 변화도 계산은 한 번만 수행 가능- 만약 동일한 그래프에서 여러번의
backward호출이 필요하면,backward호출 시에retrain_graph=True를 전달
변화도 추적 멈추기
requires_grad=True인 모든 텐서들은 연산 기록을 추적하고 변화도 계산을 지원- 그러나 순전파 연산만 필요한 경우에는 추적이나 지원이 필요없을 수도 있기에
torch.no_grad()블록으로 둘러싸서 연산 추적 멈추기 가능
z = torch.matmul(x, w) + b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w) + b
print(z.requires_grad)동일한 결과를 얻는 다른 방법: 텐서에 detach() 메소드를 사용
z = torch.matmul(x, w) + b
z_det = z.detach()
print(z_det.requires_grad)변화도 추적을 멈춰야 하는 이유
- 신경망의 일부 매개변수를 고정된 매개변수(frozen parameter)로 표시
- 사전 학습된 신경망을 미세 조정할 때 매우 일반적인 시나리오
- 변화도를 추적하지 않는 텐서의 연산이 더욱 효율적 ➡️ 순전파 단계만 수행할 때 연산 속도 더욱 향상
동일한 인자로 backward를 두차례 호출하면 변화도 값이 달라짐
- 이는 역방향 전파를 수행할 때, PyTorch가 변화도를 누적(accumulate)해두기 때문
- 즉, 계산된 변화도의 값이 연산 그래프의 모든 잎(leaf) 노드의 grad 속성에 추가되어 따라서 제대로된 변화도를 계산하기 위해서는 grad 속성을 먼저 0으로 만들어야 함
- 실제 학습 과정에서는 옵티마이저(optimizer)가 이 과정을 도와줌
