본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
NDCG(Normalized Discounted Cumulative Gain)
- 랭킹 추천에 많이 사용되는 평가 지표
- 기존 정보 검색(Information Retrieval)에서 많이 사용했던 지표
- Ton-N 랭킹 리스트 만들고, 더 관심있거나 관련성 높은 아이템 포함 여부를 평가
- ex) 검색창에 10개의 아이템이 떴고, 그중 1,3,5,7번의 4개가 관심있는 아이템이라고 생각되면 이를 가지고 랭킹이 제대로 매겨졌는지 평가
- 순위에 가중치를 주고, 단순한 랭킹이 아닌 데이터의 성향을 반영하기 위한 평가 지표
- 10개를 좋아할 것 같은데, 추천시스템이 그 중에서도 순서를 매겨주어 랭킹까지 정확히 맞췄는지를 반영하기 위한 평가지표라고 생각
- MAP(Mean Average Precisoin), Tok K Precision/Recall 등 평가방법 보완
- 추천 또는 정보검색에서 특정 아이템에 biased된 경우
- 이미 유명하고 잘 알려진 인기있는 아이템 또는 한명의 사용자에 의해서 만들어진 랭킹 등의 문제
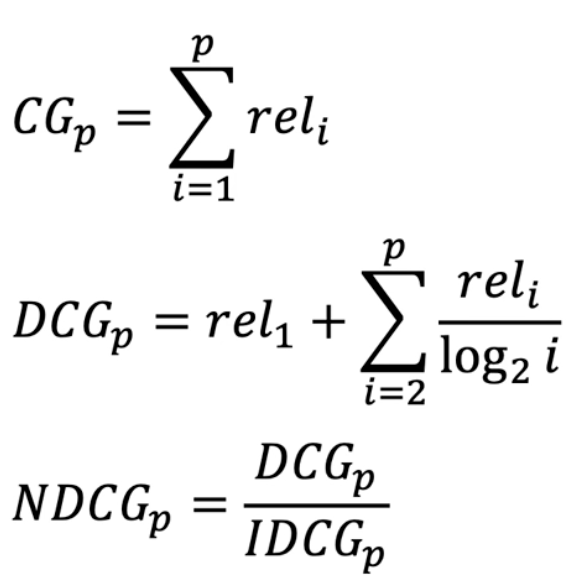
- 가장 이상적인 랭킹(정답 랭킹)과 현재 점수를 활용한 랭킹사이의 점수를 cumulative하게 비교
- 1에 가까울수록 좋은 랭킹
- 로 normalization하여 순위가 낮을수록 가중치 감소
- ex) 3등에서 4등으로 넘어갈 때보다 1등에서 2등으로 넘어갈 때 더 가중치를 주기 위한 것 (1,2등을 맞춘거랑 98,99등 맞춘거랑은 중요도의 차이가 있겠지)
- 검색엔진, 영상, 음악 등 컨텐츠 랭킹 추천에서 평가지표로 활용됨
1)
- 상위 아이템 p개의 관련성을 합한 cumulative gain
- ➡️ binary(관련 여부) 또는 complex value(문제에 따라 세분화된 값)
- ex) 아이템 1번이 얼마나 관련있는지
- 상위 아이템 p개에 대해서 동일한 비중으로 합함
- 1-5번의 아이템 ➡️ 1,3,4번이 관련있는 아이템이고 2,5번은 관련 없을 때 1/0/1/1/0 이라고 동일한 비중으로 합함 (1-5번까지 순위에 상관없이)
2)
- 개별 아이템의 관련성에 log normalization을 적용함
- 수식을 보면, 1번 아이템의 에다가 2번 아이템부터 p번 아이템까지 log normalization 적용한 것
- 랭킹에 따라 비중을 discount해서 관련성 계산 (뒷 순위로 갈수록 가중치가 점점 줄어들 수 밖에 없다)
- 즉, 하위권 penalty 부여
3)
- 이상적인 DCG(Ideal DCG)를 계산하고 (즉 정답 셋), 최종 NDCG를 계산함
- IDCG는 전체 p개의 결과 중 가질 수 있는 가장 큰 DCG 값
NDCG 예시
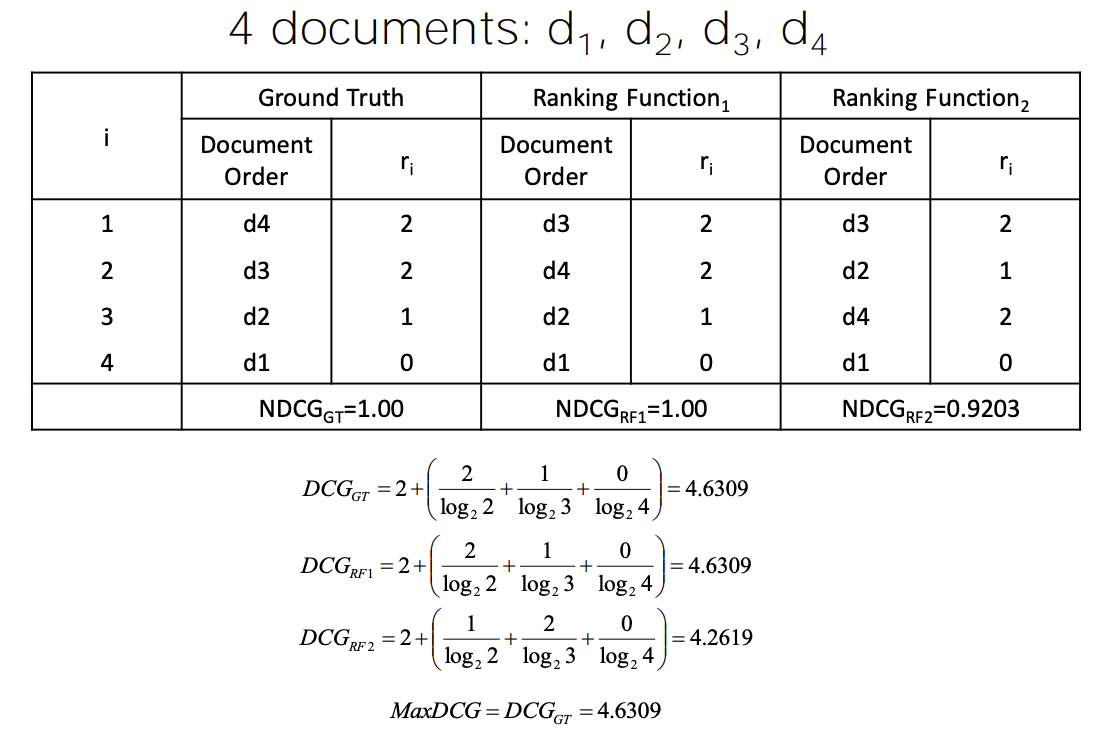
- Groudn Truth(정답): Document Order가 d4>d3>d2>d1 순
- Relevance는 2, 2, 1, 0
- 첫번째 DCG 값은 IDCG(Ideal DCG)겠지
Other Evaluation Metrics
1. Precisoin @ K (Top-K)
- Precision at K
- Tok-K의 결과로 Precision 계산
- 관련 여부를 0 또는 1로 평가
- ex) 1-0-1-1-0-0-1 일 때, Top-3는 2/3=(66.7%), Top-5는 3/5=(60%)
2. Mean Average Precision (MAP)
- 추천 랭킹 또는 검색 결과에 대한 average precision의 평균값 계산
- Precision@K(,,...,) ➡️ 전체 Precision@K에 대한 평균값
3. Precision/Recall, AUC
- 정밀도, 재현율
- 분류 문제의 정확도를 검증하고자 할 때 주로 사용되는 평가 지표
Note
여러가지 평가지표 중에 어떤 것이 딱 좋다!라고 말하기가 정말 어려움
따라서 어떤 추천시스템을 어떤 목적으로 개발하며 어떤 기준으로 평가하겠다라는 것을 잘 기획하고 설계해야 개발할 때 훨씬 수월함!
