본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 08. Recommender System with Deep Learning
📑 Paper Review
Training Deep AutoEncoders for Collaborative Filtering

- AutoEncoder에서 Deep하게 layer을 쌓았더니 더 좋은 성능 보였다
| Abstract

- 6 layer, ene-to-end로 layer-wise pre-training없이 진행됨
- AutoEncoder는 deep할수록 일반화하는 성능이 더 우수
- Nagative 부분을 포함한 non-linear activation function은 학습에 매우 중요한 부분
- Dropout과 같은 Regularization을 사용하여 ovefitting 방지
- output의 Dense re-feeding
| Model
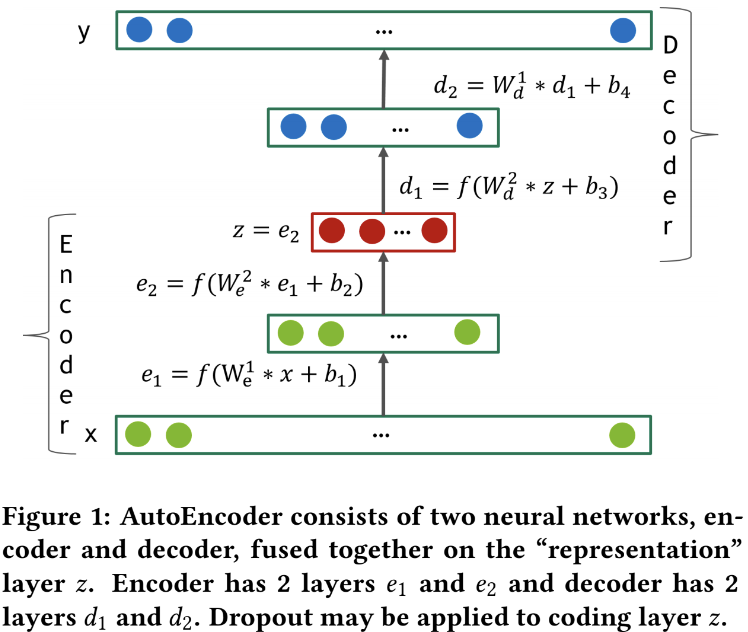
- 모델 구조는
AutoRec과 거의 유사한 구조 - 차이점은 단지 Deep AutoEncoders 모델은 더 deep하게 layer를 쌓았다는 것
1. Loss Function
- MMSE는 기존 MSE에 라는 term이 추가된 것
- 는 rating 이 0이면 0 (아예 고려되지 않음), 아니면 1 ➡️ 즉, rating이 있는 것을 고려하겠다
- Collaborative Filtering을 계산할 때 training set에 포함된 애들만 계산했는데 사실 큰 의미있는 loss function인지는 모르겠지만, 논문에서 중요하게 주장하는 내용
- 는 predicted rating
2. Dense re-feeding
-
Sparse한 로 와 loss를 구함 (forward pass)
-
Gradient와 weight를 update한다 (backward pass)
-
로 를 구한다. 이때 둘다 dense함 (second forward pass)
- 이미 비어있는 sparse 정보들이 결국 다른 matrix completion 문제로 접근하여 dense하게 채워짐
- 따라서 second forward pass에서는 dense하게 바뀌고, 이를 re-feeding하겠다
- Gradient와 weight를 다시 update한다 (second backward pass)
✅ 즉 dense한 결과로 한번 보고 끝인게 아니라, dense한 결과를 한번 더 학습시킨다는 것
| Experiment (1)
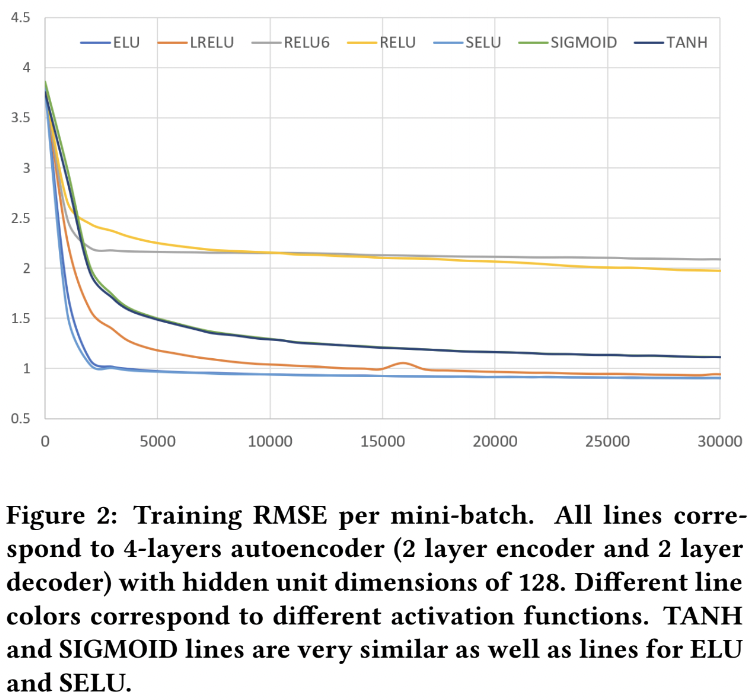
-
여러 종류의 Activation function에 대한 실험
-
Single layer에 대해 hidden units 개수를 다르게 한 실험!
-
A: 학습할 때 RMSE 값 어떻게 변하는지
-
B: 학습 후에 evaluation할 때 RMSE 값 어떻게 변하는지
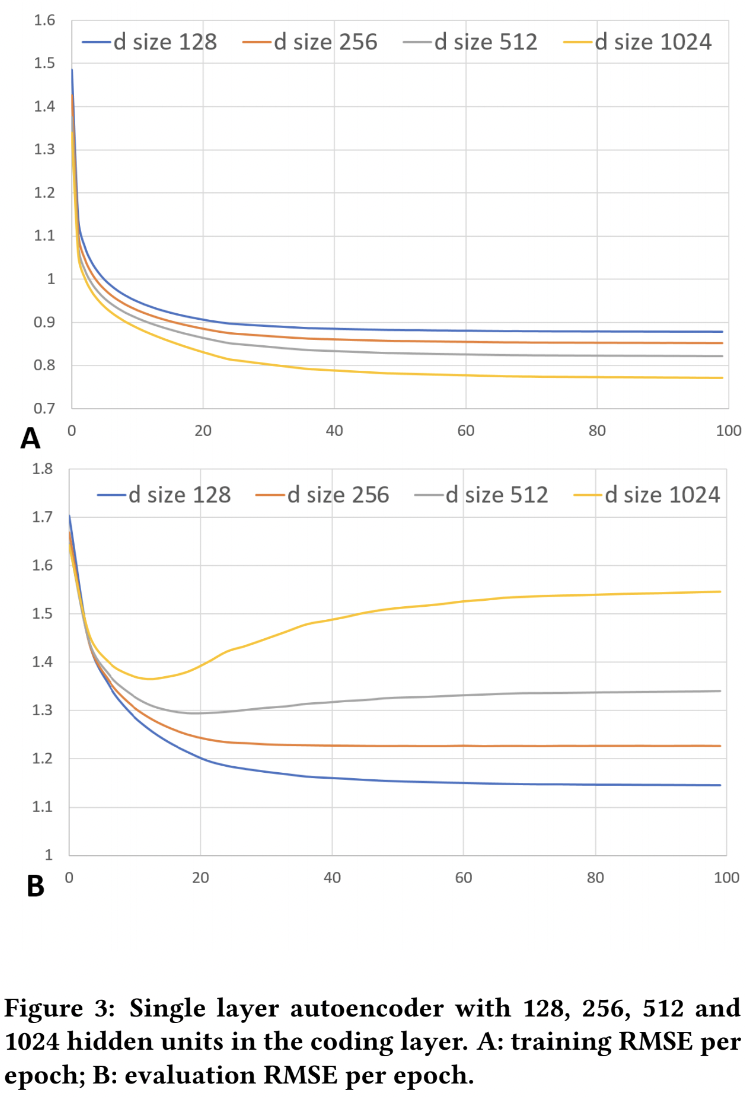
-
B에서는 d=128이 제일 성능이 좋지만, A에서는 d=1024일 때 제일 성능 좋음
- A에서 d=1024는 학습할 수록 overfitting 되는 것이 아닌가
- Dropout 실험
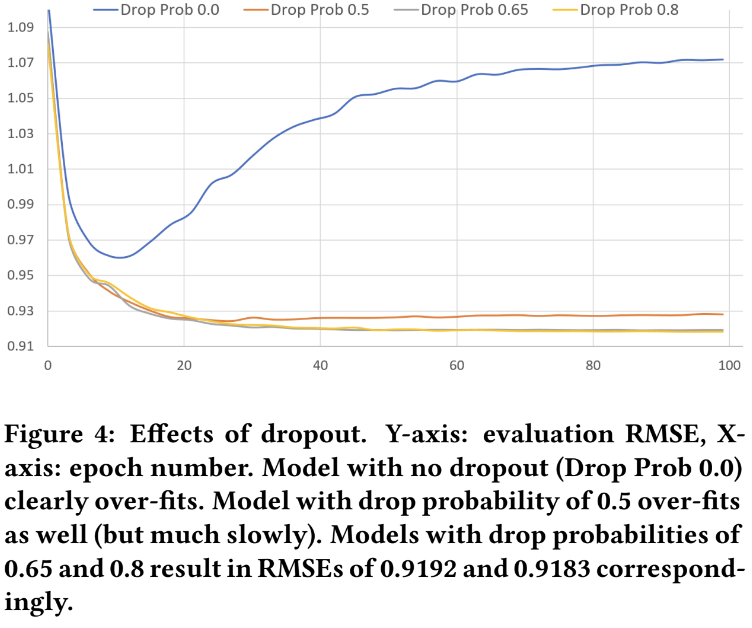
- Regularization 효과 검증
- Dense Re-feeding의 효과

