본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 08. Recommender System with Deep Learning
📑 Paper Review
Wide & Deep Learning for Recommender Systems

- 구글에서 공개한 논문
- Wide와 Deep의 개념 정의 후 어떻게 추천시스템에 적용할 수 있는지 설명하는 논문
- Tensorflow 딥러닝 프레임워크에 Wide & Deep을 쓸 수 있도록 API화
- 구글 플레이스토어에서 추천시스템이 잘 작동했는지 직접 확인해보면서, 모든 사람들이 각자의 추천시스템에 이용할 수 있도록 환경 구성
Abstract

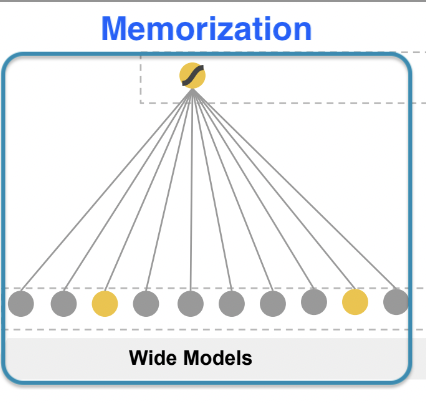
Wide: Memorization
주어진 데이터를 그대로 외운다- Cross-product feature transformation
- 단순히 외우는 것이 아닌 feature 간의 interaction도 보면서 외운다
- More feature engineering effort 필요 (단점이 될 수 있음)
Deep: Generalization
- Generalize to unseen feature combinations
- 지금까지는 seen feature, 주어진 과거 데이터로 학습하고 외웠던 wide component라면 Deep을 통해 unseen feature도 generzalize 해보겠다
- Less feature engineering effort
- Over-generalize
- 사소한 부분 신경 못 쓸 수 있다
Wide & Deep
- Joint wide linear models and deep neural networks
Introduction (1)
Memorization 정의
- Frequent co-occurrence of items of features
- 얼마나 둘이 동시에 등장하는지, interaction은 어떻게 되는지
- Exploit correlation available in the historical data
- correlation을 모두 활용하여 historical data 학습한다
Generalization
- Explore new feature combinations
추천시스템에서 Memorization과 Generalization
Memorization: more topical and directly relevant to the items- 아이템에 집중되어 있다 ➡️ historical data에서 본 내용으로 추천하겠다
Generalization: improve diversity of the recommendations- 추천의 다양성 향상 (추천시스템에서 중요한 부분)
-> Google Play Store의 apps recommendations 실험을 했더니 general하게 적용할 수 있다
Introduction (2)
기존 추천 모델의 한계
1. Generlized Linear Model
- Logistic Regression과 같은 모델에 다양한 features를 만들어서 학습시킴
- Memorization(주어진 데이터의 기억)에 특화됨
- 코로나 발생 이전에는 마스크에 대한 추천이 거의 없었는데, 코로나라는 새로운 상황이 발생했을 때 과거 데이터에는 마스크라는 아이템 추천이 없었으므로 새로운 추천(마스크)을 못하는 문제 발생
- 새로운 또는 관측되지 않은 데이터(unseen data)에는 취약함
- 오버피팅 발생 가능
- 주어진 데이터만 외우게 되면 그 데이터와 비슷하지만 좀 다른 데이터라면 이를 제대로 캐치못해서 생뚱맞은 추천 가능성이 있다
2. Embedding based Model
- Factorization Machine, Deep Neural Network 방법 활용
- Generalization(unseen data 대응)에 특화됨
- but, over generalization 가능성이 있을 수 있다 (한계점, 단점)
- Non-zero prediction으로 인해 섬세한 추천 불가능
Contributions
1. Wide&Deep Learning framework 제안
- Jointly training feed-forward neural network and linear model
2. Google Play에 상용화된 Wide&Deep 추천시스템의 평가와 구현내용을 공개
- 모바일 앱스토어에서 App 구매, 다운로드 등 향상
- 🌟 학습과 서비스 속도 충족 ➡️ 실서비스에 적용 가능
3. Tensorflow기반의 API를 오픈소스 형태로 제공
Wide&Deep Learning Framwork Overview
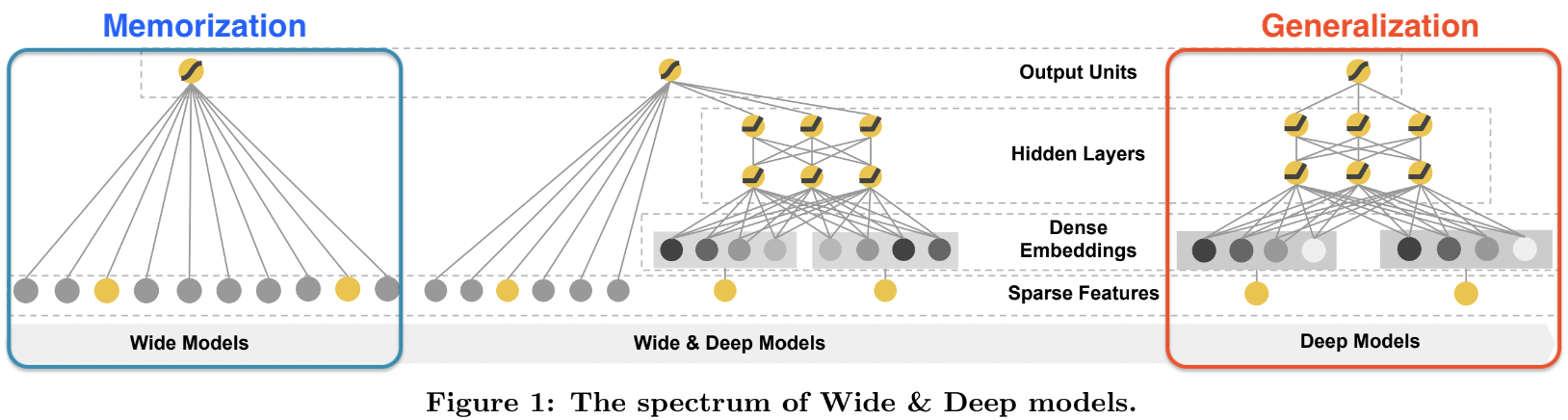
왜 딥러닝은 Wide와 같은 linear model을 합쳐서 많이 얘기할까
➡️ 추천에는 정답이 없고, 추천 알고리즘은 각각의 시스템에 맞는게 존재한다 (데이터가 조금 바뀌면 추천 알고리즘도 변경되는 형태)
또한 추천은 점수로만 평가할 수 있는 것이 아님, 추천 서비스는 사람이 선택하는 것
그래서 Wide&Deep을 합쳤지 않을까. 성능만 따지는 거면 Deep model을 썼겠지만 Wide를 합쳐서 어느정도 보장이 된 기본적 역할 + 새로운 것 추천해주는 deep한 모델이 필요한 것 같음
Recommender System Overview
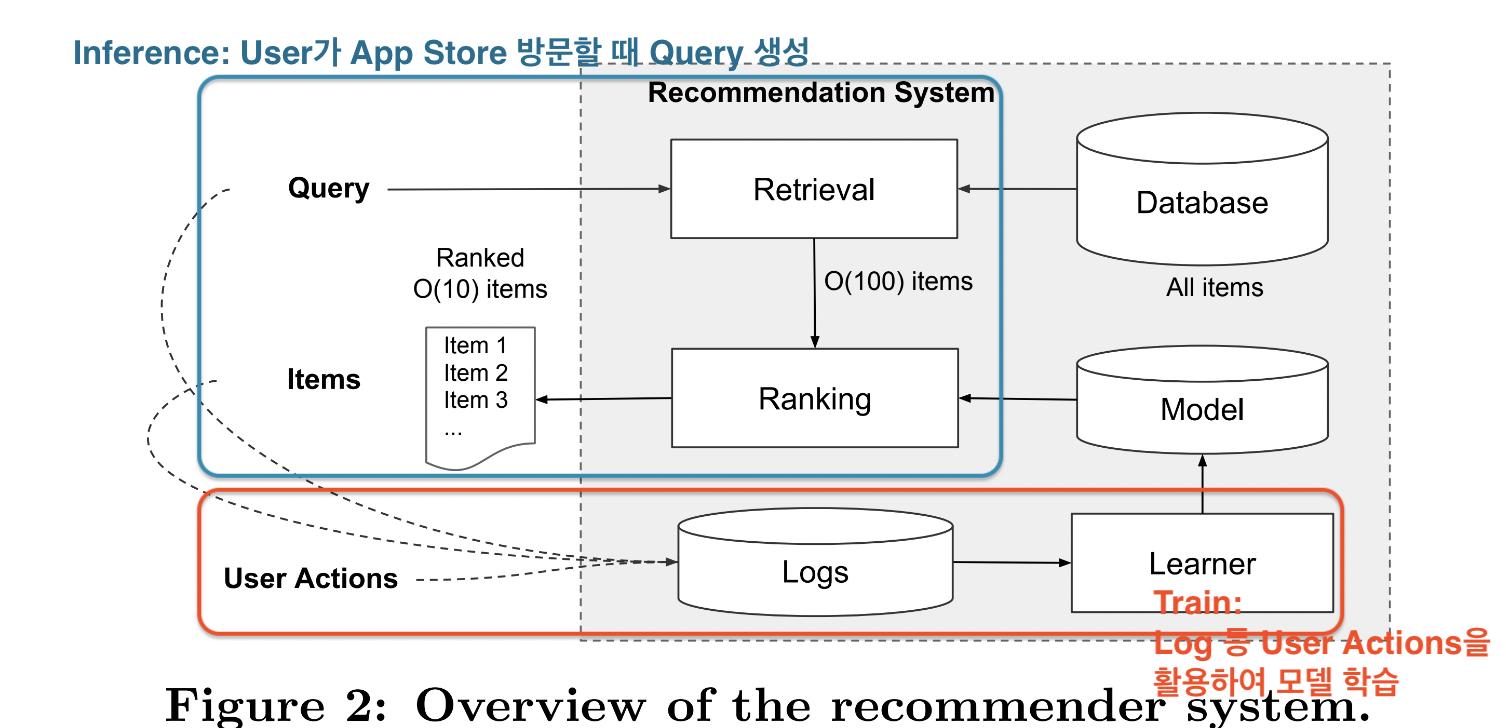
Infernece
-
Query: user가 app store 방문할 때 생성 ➡️ 어떤 모바일 기기 활용, 어떤 time에 접속, 과거 app store에 어떤 기록을 남겼는지, 무슨 app을 원하고 있는지
- 아이템들 Retrieval을 통해 Ranking 매겨서 Items 리스트 생성
User Actions
- Query와 Items 모두 합쳐서 user actions로써 새로운 학습을 위한 Logs를 생성 ➡️ Learner에게 제공하여 학습 성능이 더 향상될 수 있도록 함
이러한 일련의 과정을 통해 추천 시스템 성능이 더 향상되는 것을 기대
The Wide Component
- Wide는 Generalized Linear model ➡️
- ➡️ prediction(유저 행동여부)
- ex) 구매 했는지의 여부
- 예측 y값과 실제 y값의 차이를 바탕으로 학습이 이루어짐
- size d의 feature vector
- Raw input features & cross-product feature
- ➡️ model parameters
- ➡️ bias
* cross-product feature 설명
- (예시) feature가 여성이고 영어를 쓰는 사람인지에 대한 2가지 조건을 모두 만족하면 1, 그렇지 아니면 0으로 새로운 cross-product feature를 만드는 것
- cross-product feature는 feature 간의 interaction을 반영하기 위해서 적용함
- 저자 왈, Wide componenet는 linear model이지만 non-linear한 부분도 조금 넣어주면 좋을 것 같악서 이를 반영하기 위해 이러한 feature interaction을 반영한다고 함

The Deep Component
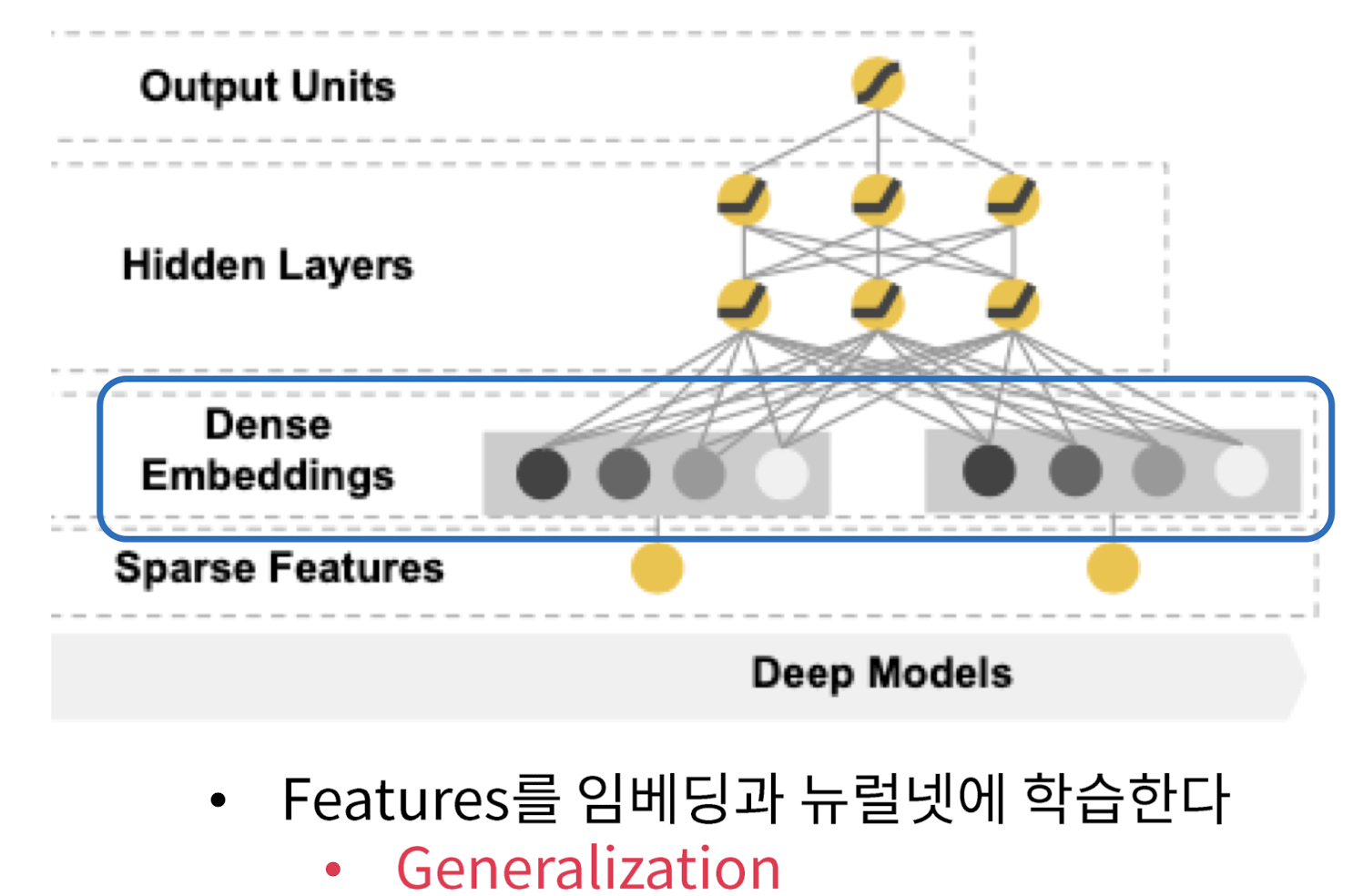
feed-forward neural network로 학습하는데, 추천시스템에서 만든 feature를 활용한다고 쉽게 이해해도됨
- layer 중간의 계산은 을 이용
- : number of layers
- : activation function (ReLU)
- Activation, bias and model weights at l-th layer
- Dense Embeddings
- Nominal Feature(명목형)에 해당하는 임베딩을 랜덤 초기화(random initalize)하고 모델 전체를 학습한다
Joint Trainig of Wide & Deep Model (1)
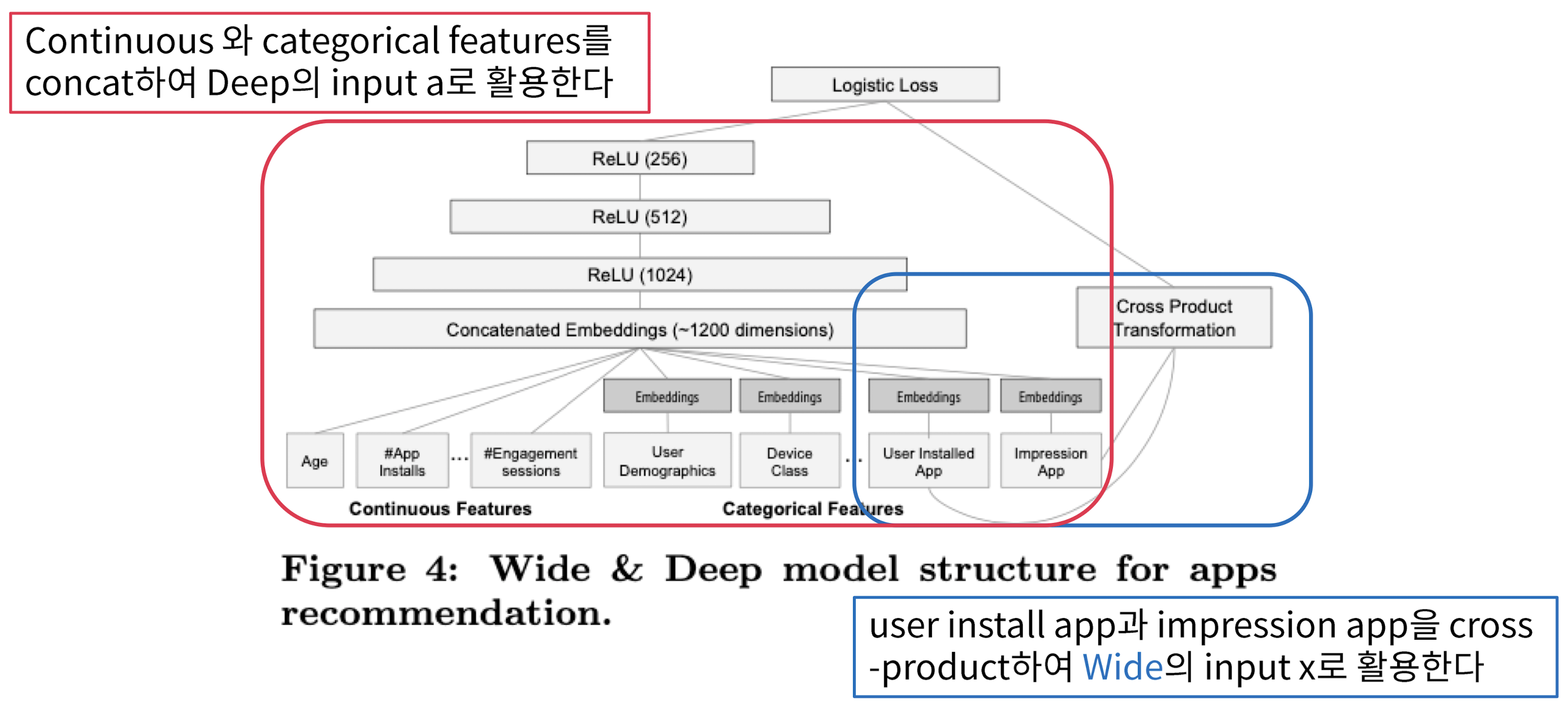
- user installed app과 impression app을 바탕으로 Cross Product Transformation 하여 Wide의 inpux 로 활용하겠다
- user installed app와 impression app의 interaction을 보고자함도 있음
- Deep Component에서는 Continuous Feature부터 Categorical Features까지 모두 활용하여 concat하여 Deep의 inpux 활용
Joint Trainig of Wide & Deep Model (2)

- gradient 업데이트할 때 backpropagation을 wide와 deep part 모두 동시에 진행한다 ➡️ 마지막 Logistic Loss를 wide와 deep 모두 활용
- 또한, 학습할 때 Wide part에서는 FTRL 알고리즘 사용하여 옵티마이저로 사용
- Deep part에서는 AdaGrad를 옵티마이저로 사용
Joint Trainig of Wide & Deep Model (3)

- 최종적으로 학습 후 무슨 결과를 얻을 수 있을까 ➡️ P의 확률값
- 는 app을 다운받을 확률
- Sigmoid 함수의 input으로 Wide와 Deep을 합한 값을 넣어주고, 그 output이 최종 결과가 됨
System Implementation
Pipeline
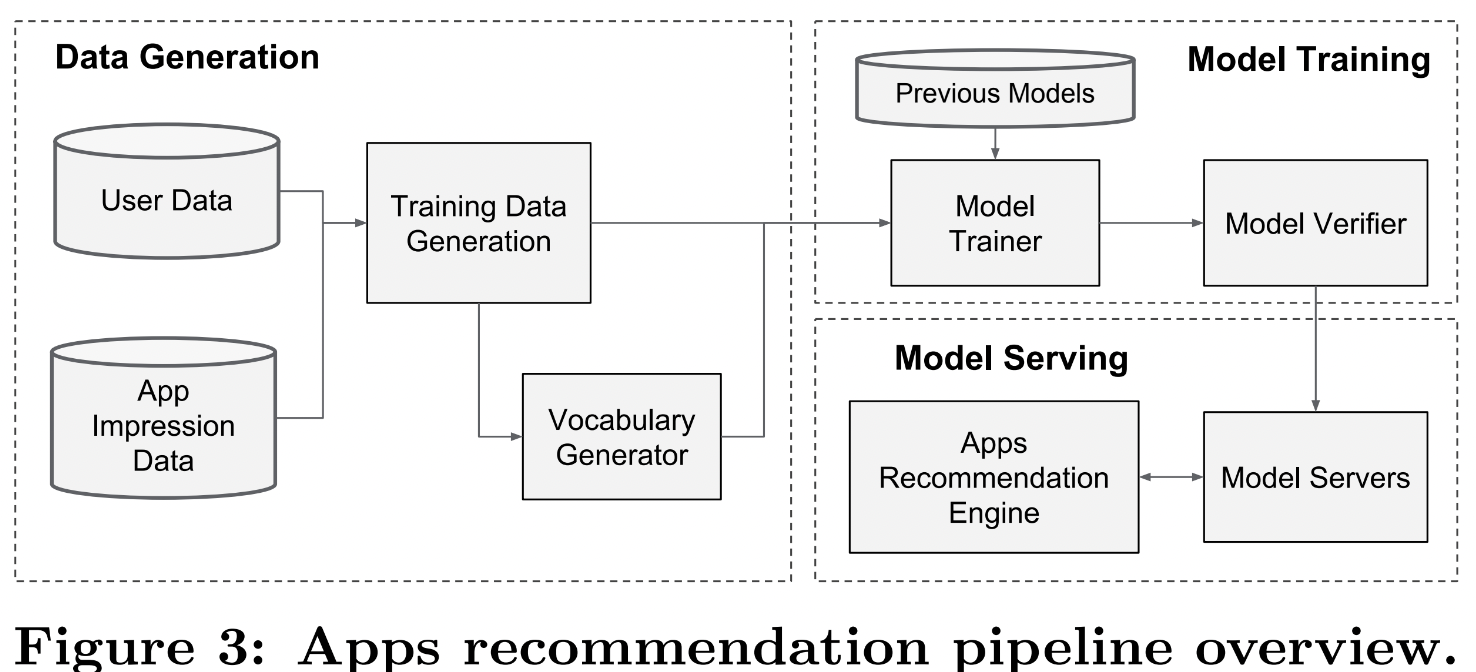
- 추천시스템은 실제 서비스에 적용하고자 하는 것이 굉장히 중요한데, 이러한 pipeline을 제공해주었음
Experiments (1)
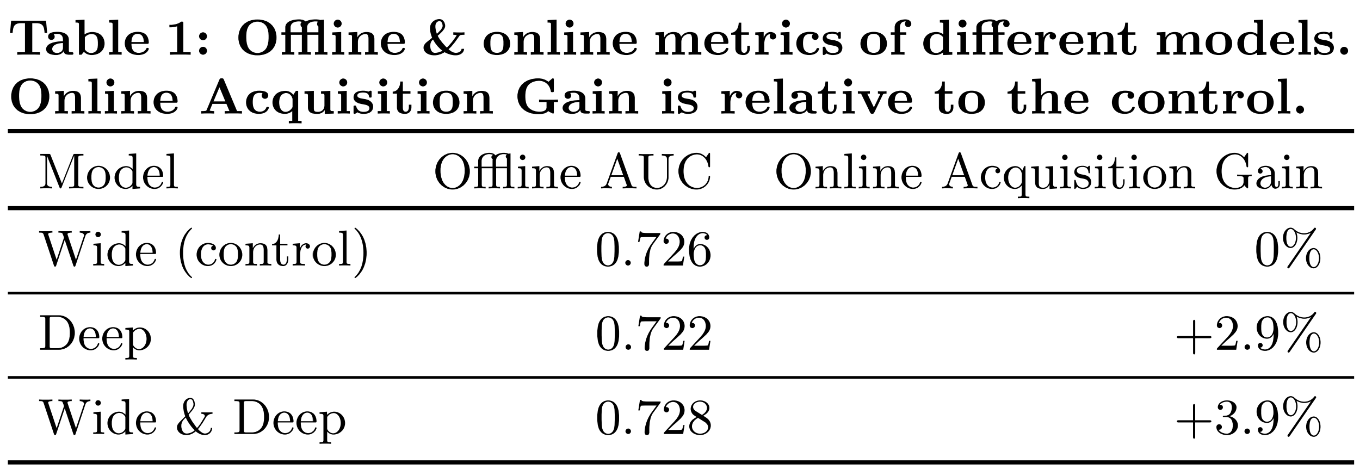
성능 부분 (50% 강조)
- Offline AUC
- Test set의 사용자 행동결과로 성능 측정
- AUC는 클수록 좋은 점수 나타냄 (=ROC 커브의 아래 면적)
- Online Acquisition Gain
- 실제 사용자들이 action을 추적
- 기존 모델 대비 application 실제 다운로드수가 증가함
Experiments (2)
나머지 50% 강조

- Multithreading, Split eath batch into smaller batches ➡️ latency를 14ms 줄일 수 있다
- 추천알고리즘의 성능 뿐만 아니라 Commercial Mobile App Store의 서비스까지 신경 쓴 것을 알 수 있다
Conclusions
1. Memorization의 Wide와 Generalization의 Deep을 결합한 모델 제안
- Wide & Deep Learning
