본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 08. Recommender System with Deep Learning
DeepFM: Factorization Machine과 Wide&Deep의 장점을 잘 합쳤다
📑 Paper Review
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction

26th International Joint Conference on Artificial Intelligence 2017
0. Abstarct

-
Click Through Rate(CTR)을 예측하는 모델 ➡️ DeepFM이 달성하고자하는 최종 목표, CTR이 높은 아이템을 추천하자
- user에게 추천시스템의 결과로 아이템 목록을 보여줬을 때, 각각의 아이템들 중 어떤 아이템을 선택할 지 예측하는 모델
- 즉, CTR이 높은 아이템을 더 추천해줘야겠지
-
Low와 High-order interactions 모두 학습 가능
- 복잡하거나 단순한 feature interaction 모두를 학습 가능하다는 것
- 한가지 의문; Wide&Deep도 wide와 deep component로 나누어서 low와 high interaction을 학습가능하다고 했는데, 그렇다면 DeepFM과 무슨 차이가 있을까? (4번째 부분부터)
-
Factorization Machine의 장점과 Deep Learning의 장점을 모두 합친 모델 ➡️ DeepFM
-
추가 feature engineering없이 raw feature를 그대로 사용 가능 ➡️ Wide&Deep과 DeepFM의 중요한 차이점
- feature engineering이 없다는 것은 개인의 도메인 지식이 필요없다는 것 + 누구나 사용가능하다
-
벤치마크 데이터와 commercial 데이터에서 모든 실험 완료
1-1. Introduction (1)
1. CTR: user가 추천된 항목을 click할 확률을 예측하는 문제
- CTR(estimated probability)에 의해 user가 선호할 item 랭킹을 부여함
2. Learn Implict Feature Interaction
<예시>
- App category와 Timestamp 관계: 음식 배달 어플은 식사시간 근처에 다운로드가 많음
- User gender와 Age 관계: 남자 청소년들은 슈팅과 RPG 게임을 선호한다
- 숨겨진 관계: 맥주와 기저귀를 함께 구매하는 사람이 많다
➡️ 이처럼 low와 high-order feature interaction을 모두 고려해야 함
➡️ 또한 Explicit과 Implicit features를 모두 모델링할 수 있어야 함
➡️ DeepFM은 이 둘 모두 가능하다!
1-2. Introduction (2): 현재까지 추천알고리즘 연구 정리

1-2. Contributions

1. DeepFM이라는 모델 구조 제안
- Low-order는 FM, High-order는 DNN
- End-to-end 학습 가능: pre-trained model 같은 것 필요 X
2. DeepFM은 다른 비슷한 모델보다 더 효율적으로 학습 가능
- Input과 embedding vector를 share 함
3. DeepFM은 benchmark와 commercial 데이터의 CTR prediction에 의미있는 성능 향상 이룸
1-3. Our Approach
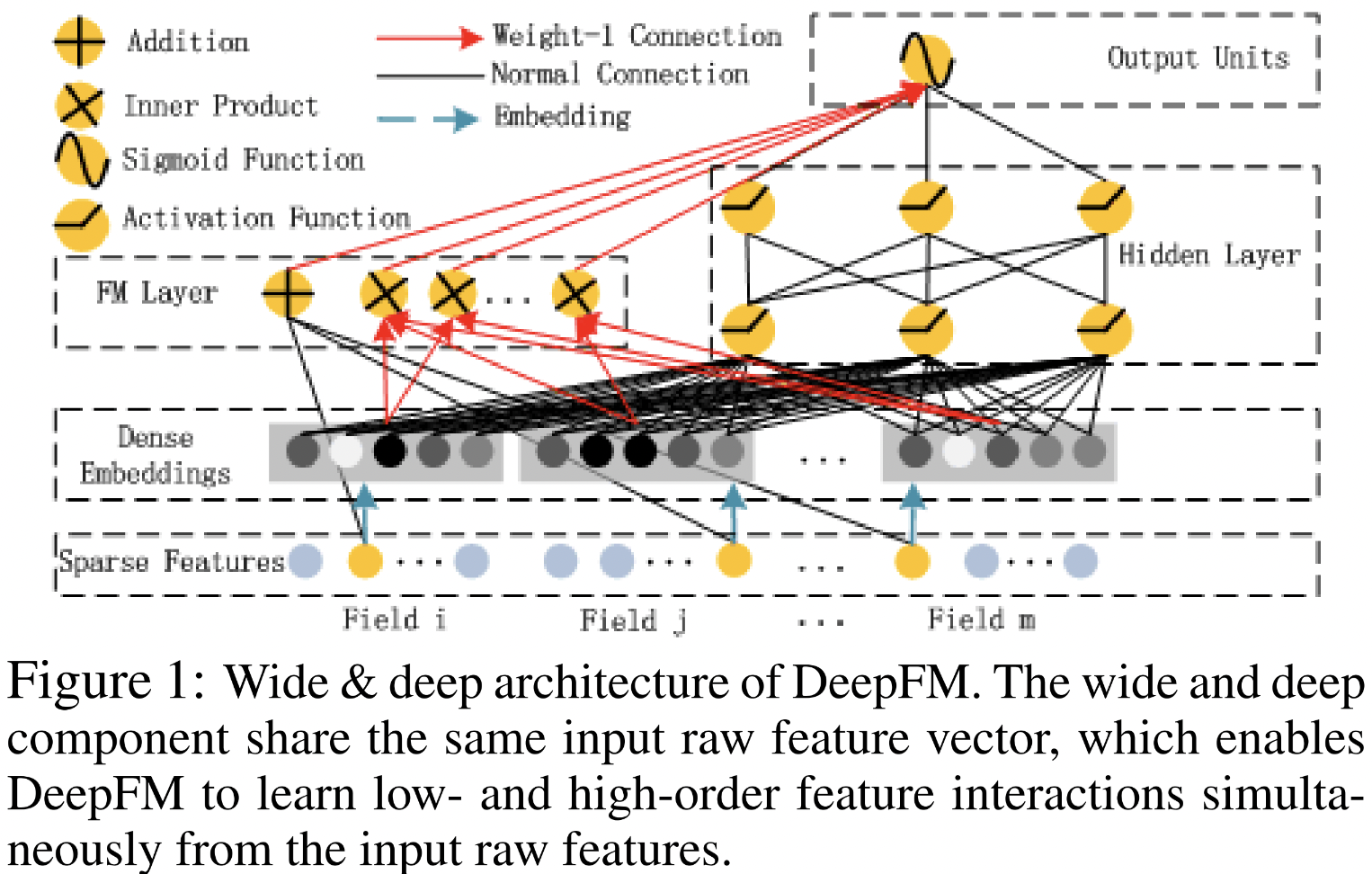
- input와 dense embedding share ➡️ share 한 것들을 하나는 FM layer, Hidden layer(DNN)에 활용 후 최종 하나의 output
- Wide part가 왼쪽, Deep part가 오른쪽
- Wide&Deep과 굉장히 흡사한데, 차이점은 same input raw feature vector를 사용한다는 것
2-1. DeepFM
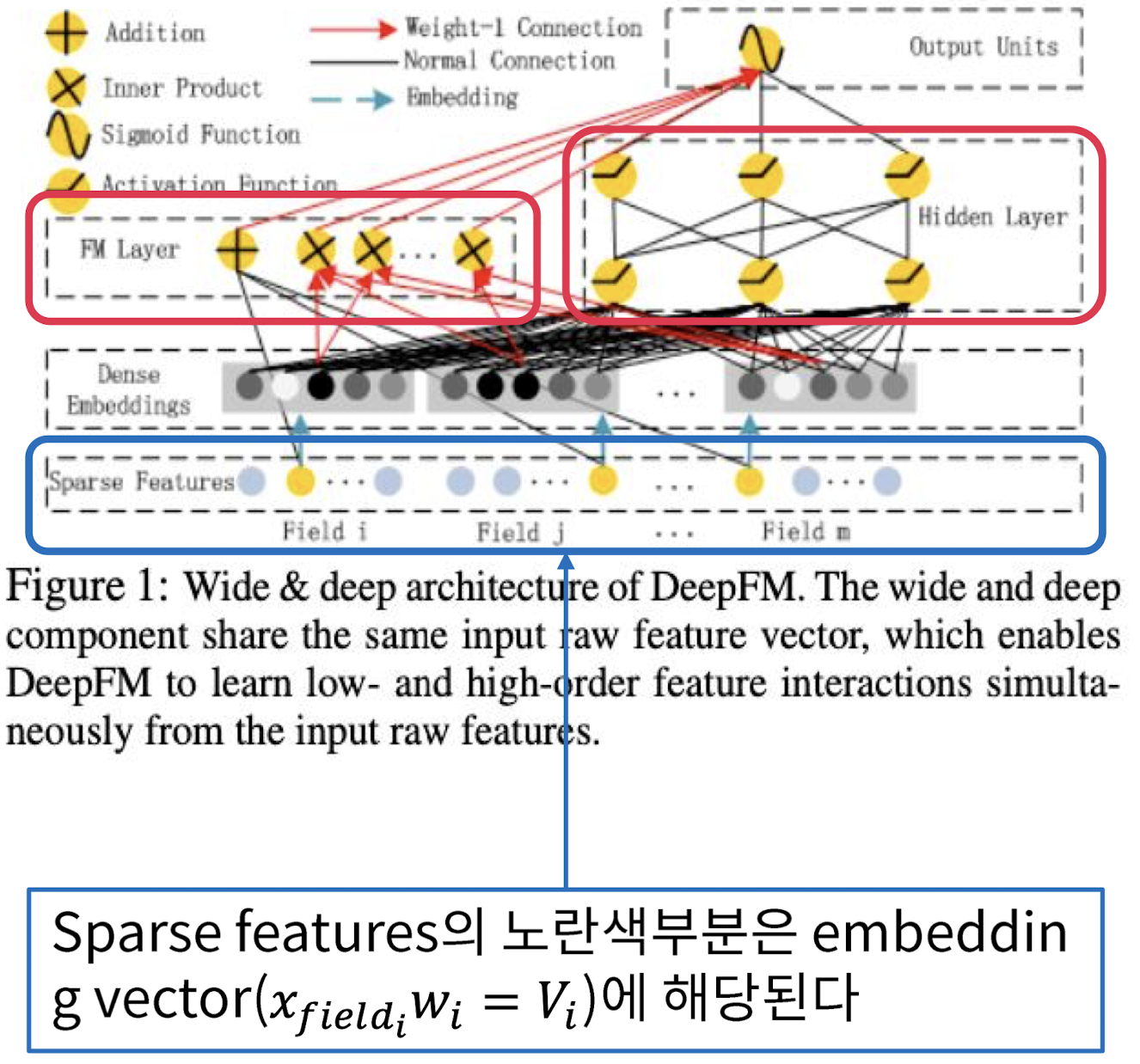
Sparse Features
- 각각의 Field들이 있음, 이때 노란색 부분이 embedding vector이고 로 계산됨
- ...
- _: [0,1]의 확률값

즉, Sparse Features에서 노란색 부분에 해당하는 embedding vector를 이용해서 embedding vector를 share하고, share한 벡터를 가지고 FM layer와 Hidden layer에서 작업 후 최종적 output을 concat해서 결과 도출
2-2. FM Component
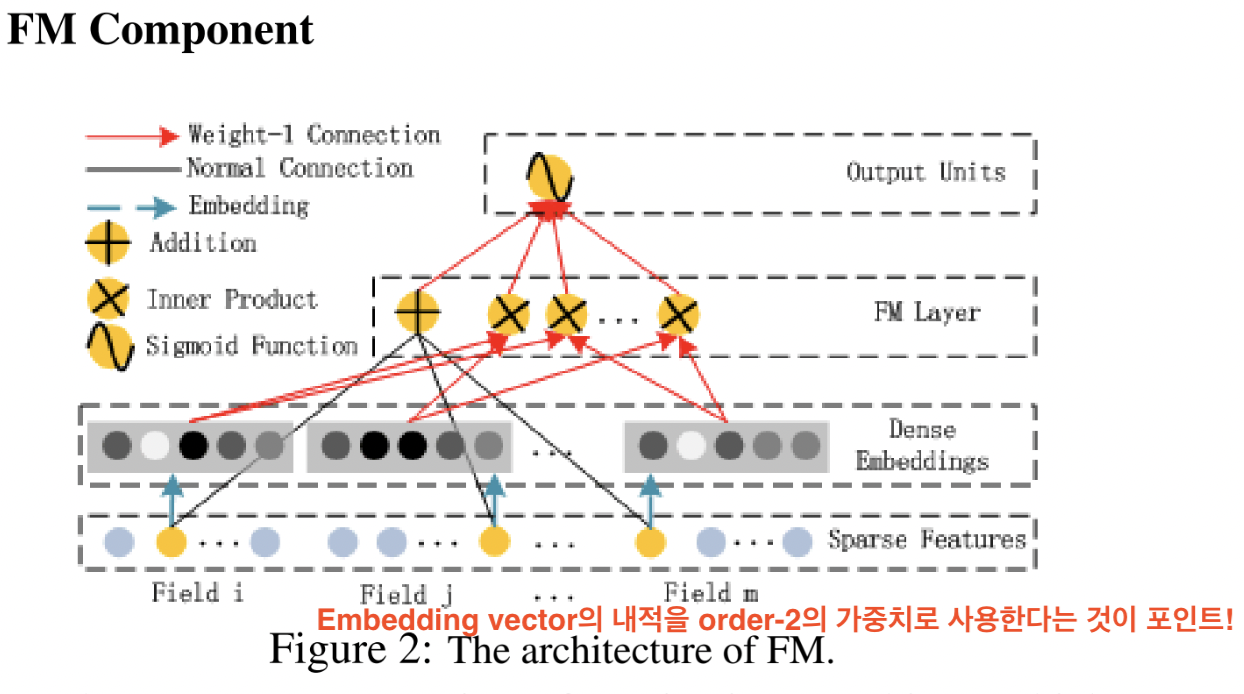
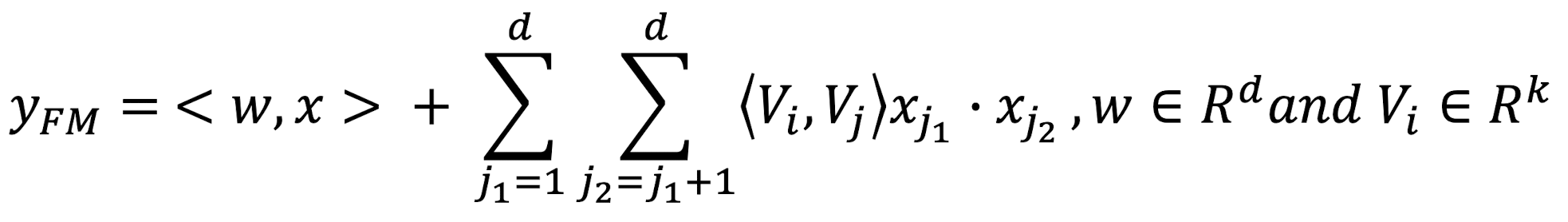
- embedding vector끼리의 내적 ➡️ 을 가르키는 것
- 그림에서 각각의 Dense embedding vector들을
Inner Product해주는 표시
2-3. Deep Component
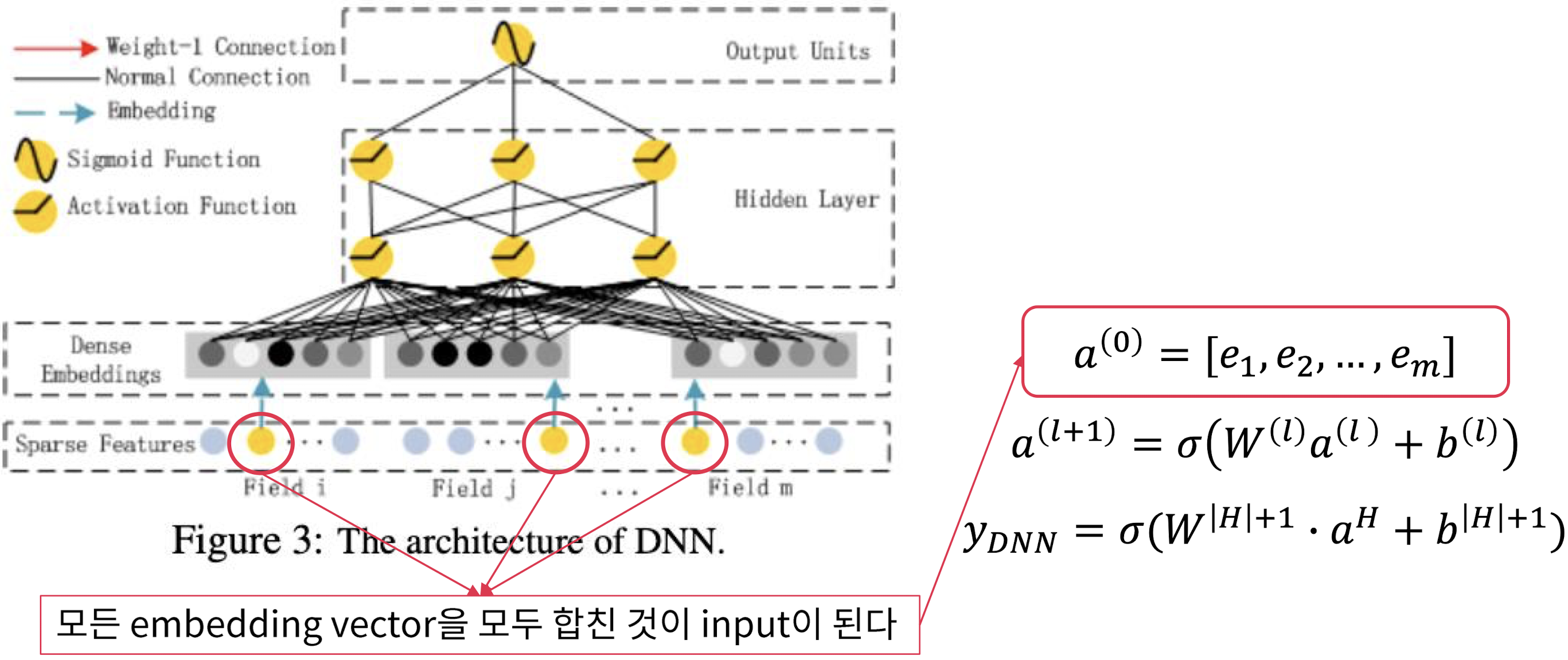
- Sparse feature들을 모두 합쳐서 로 만들고, 이것을 hidden layer들을 쭉 태운다
- 한 마디로, dense embedding을 FM Component와 share하고, Deep component에서는 각각의 dense embedding을 하나로 합쳐서 layer들을 태움
2-4. Relationship with the other Neural Networks
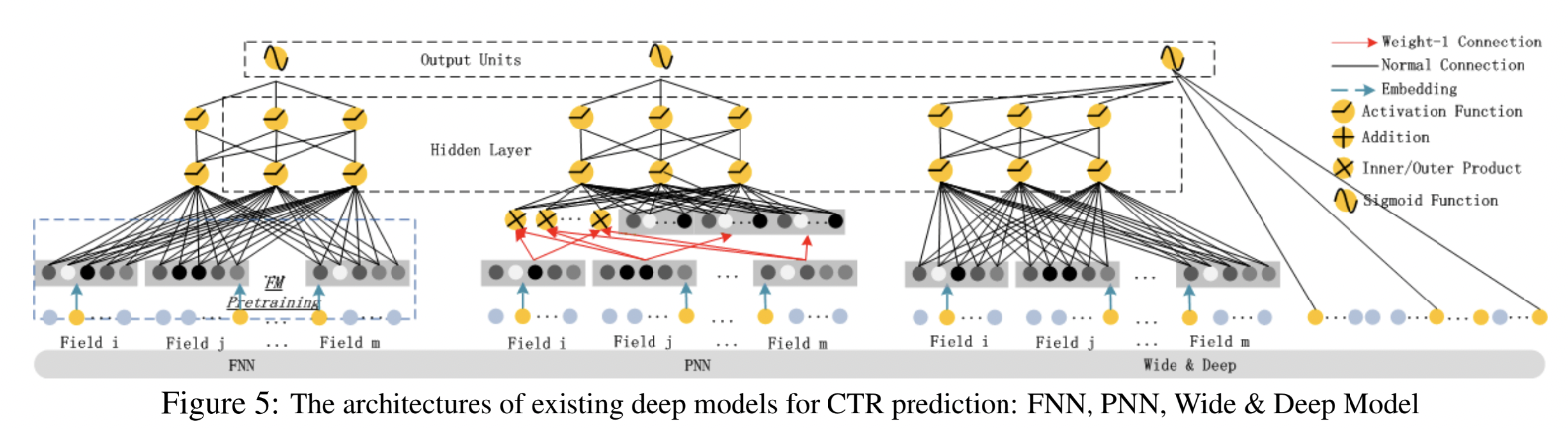
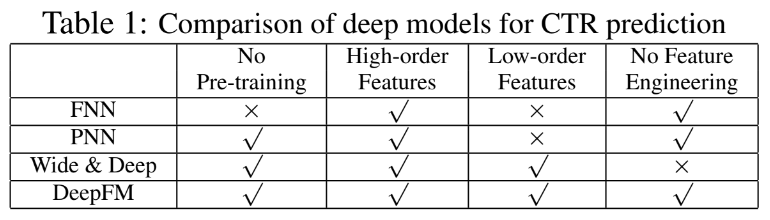
- 다른 neural network들은 DeepFM과 무슨 차이가 있는지 살펴보았음
- DeepFM은 4가지 요소 분야 해당되는 장점이 많은 모델 (한번 더 강조!)
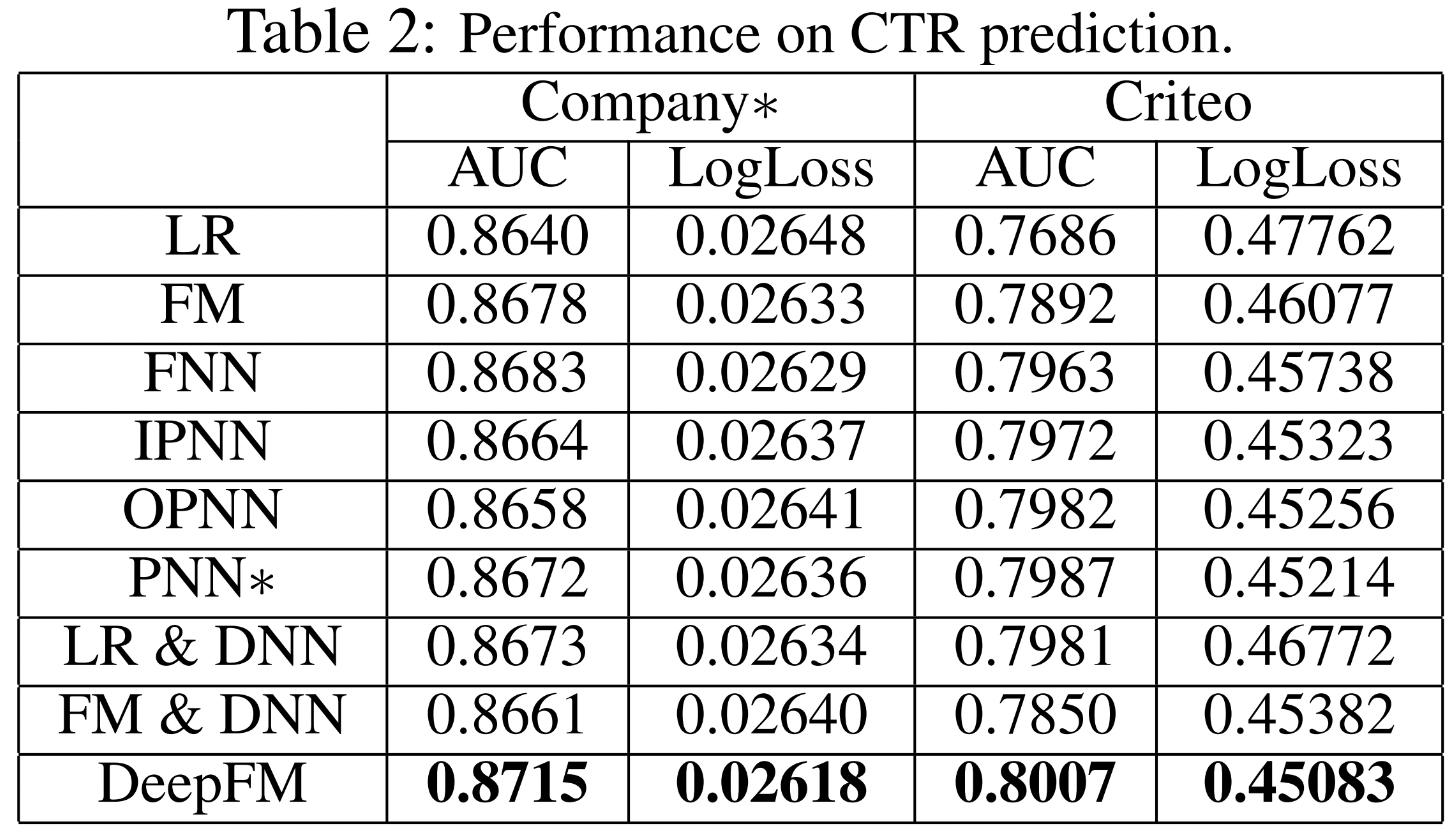
3-1. Experiments

3-2. Efficiency Comparison
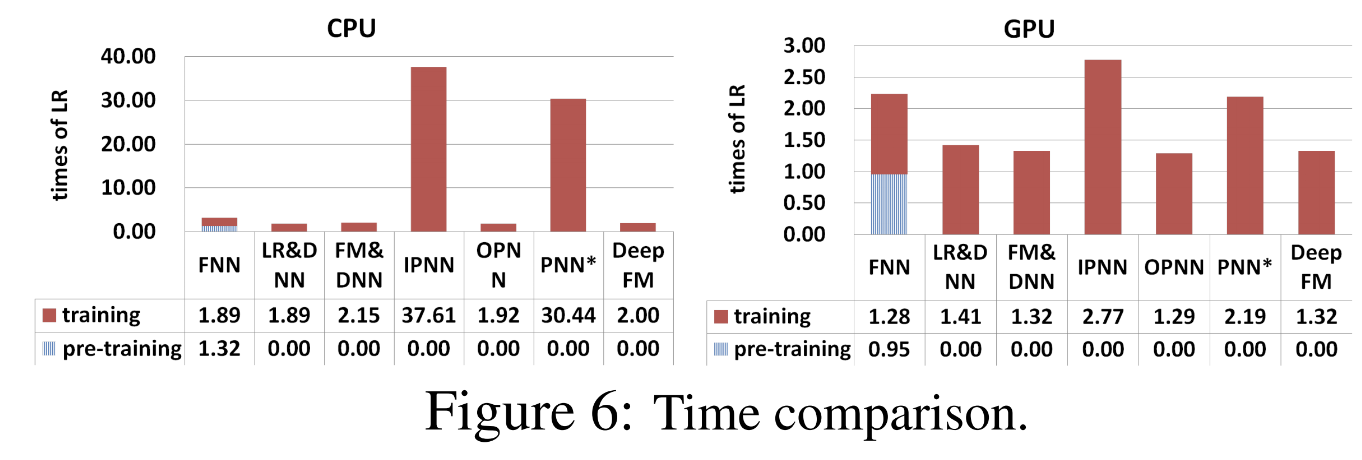
- 학습하는데 시간이 얼마나 걸렸냐
- 그래프에 나와있는 시간은 Linear model 대비 각 모델이 학습에 걸린 시간을 나타냄
- FNN은 pre-training에 시간을 많이 쏟음
- IPNN과 OPNN은 hidden layer에서 inner product를 하면서 시간이 매우 오래 걸림
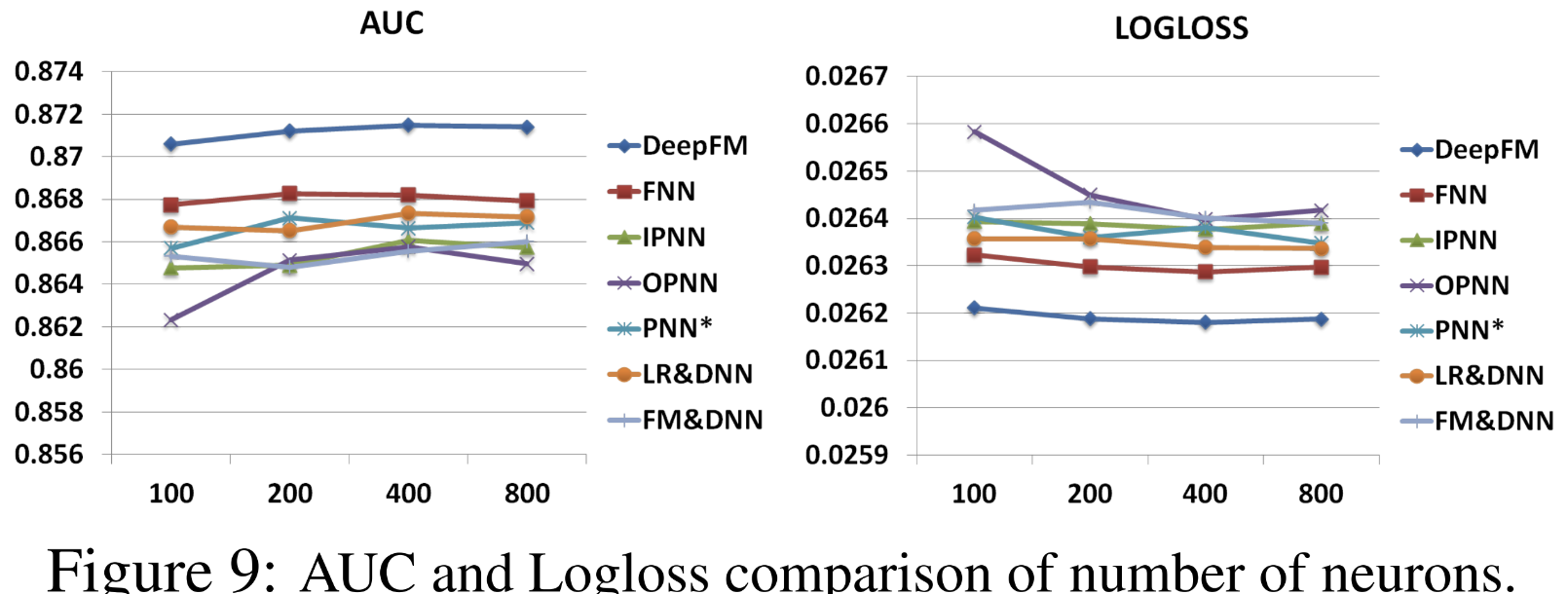
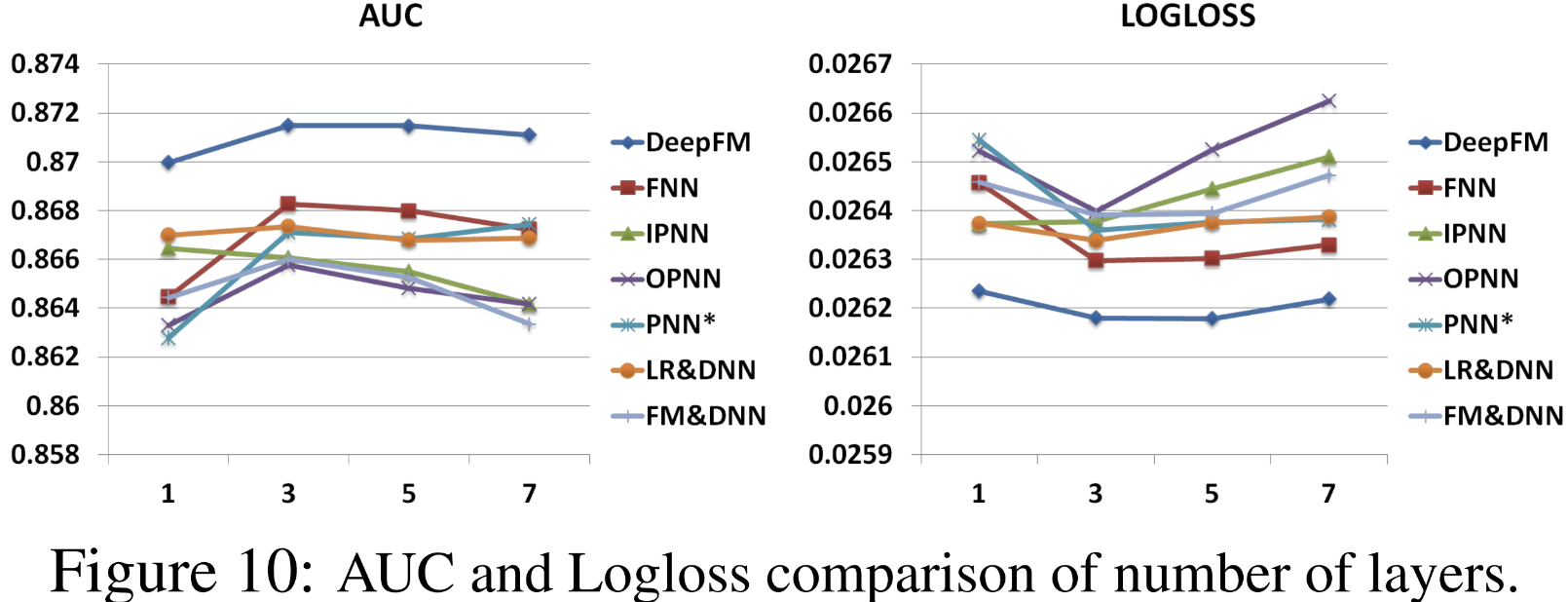
3-3. Hyper-Parameter Study

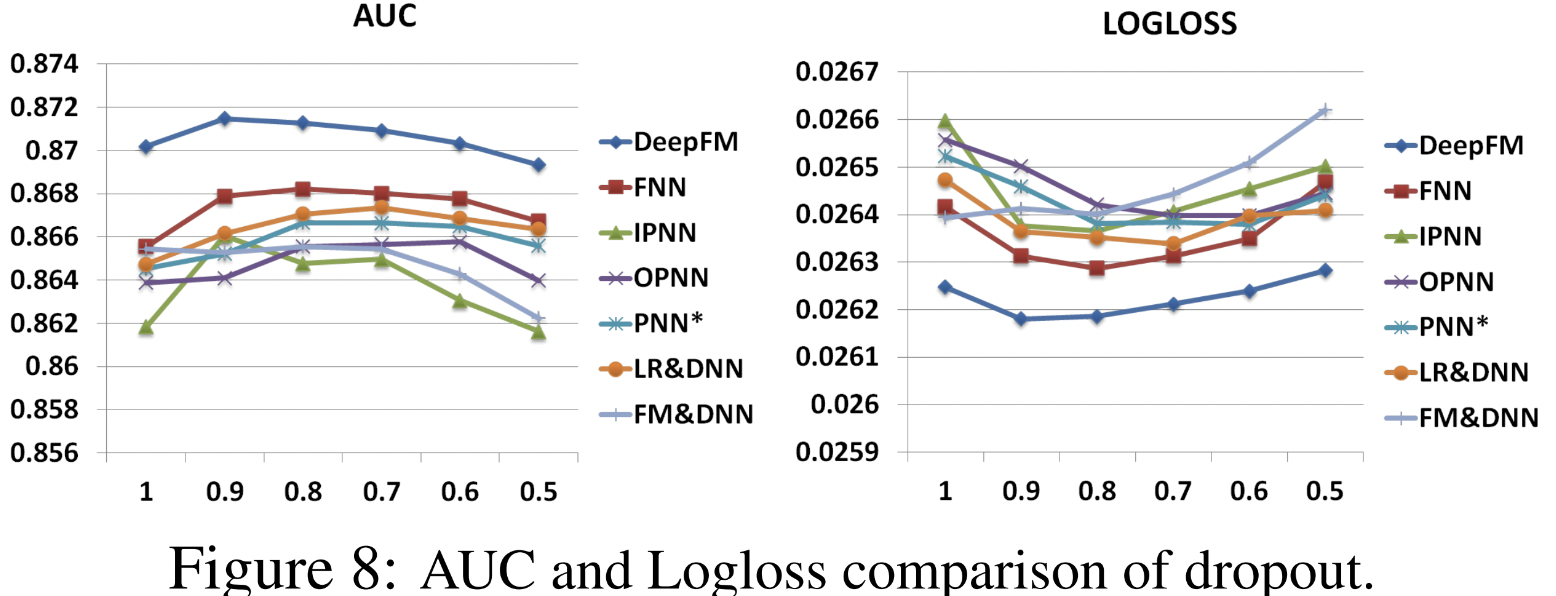
- activation이 어떤 역할을 하느냐
- ReLU와 tanh의 성능적 역할
- dropout도 DeepFM이 제일 성능이 좋음
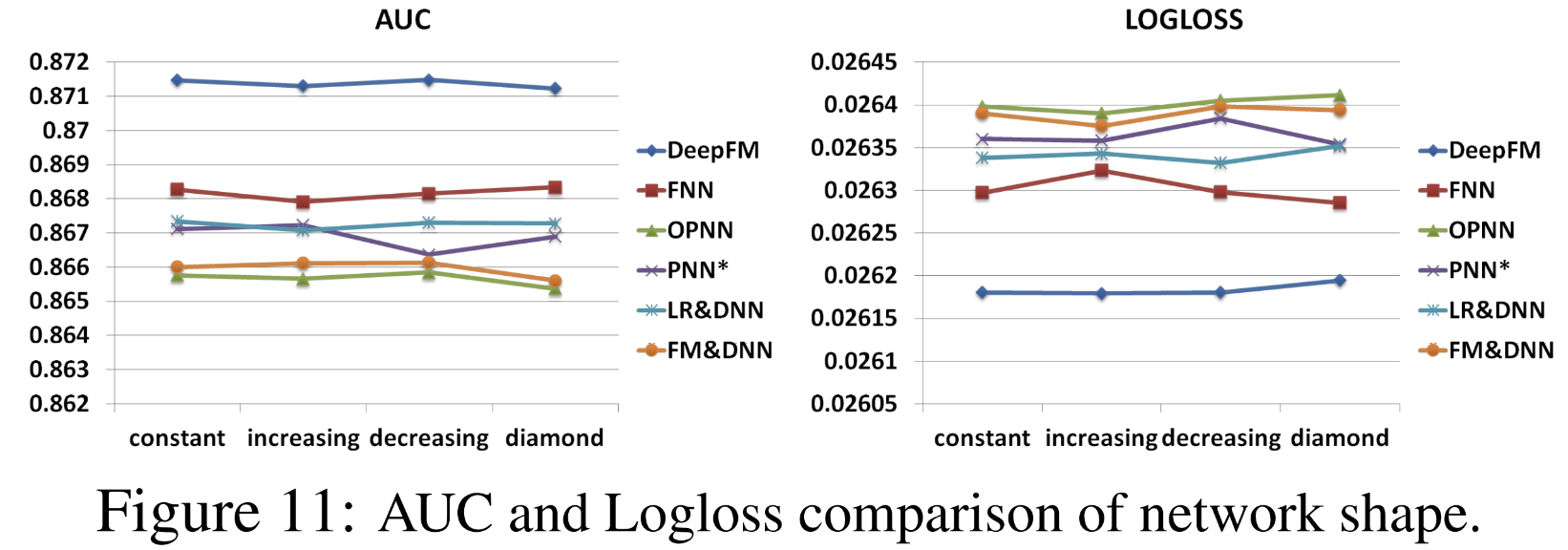
Conclusion
1. DeepFM
- deep component와 FM component를 합쳐서 학습
- Pre-training이 필요 X
- High와 low-order feature interactions 둘 다 모델링
- Input과 embedding vector를 share함
2. From experiments
- CTR task에서 더 좋은 성능 얻을 수 있음
- 다른 SOTA모델보다 AUC와 LogLoss에서 성능 뛰어남
- DeepFM이 가장 efficient한 모델
