본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 08. Recommender System with Deep Learning
📑 Paper Review
Image-based Recommendations on Styles and Substitutes

SIGIR 2015
- ex) 청바지를 샀을 때 어울리는 아이템을 주로 다루는 논문 ➡️ 이미지 기반
| Abstract

- 보여지는 사물에 대해 사람이 어떻게 인식하는지 판단하고, 판단된 내용으로 실제 모델링에 활용하는 것이 주 목적
- 유저의 기록이나 주어진 히스토리 등을 활용하는 것이 아니라, 매우 큰 데이터셋을 활용하고 확장하는 방법 소개
- 데이터 속의 숨겨진 시각적 관계에 대한 인간의 개념과 이해를 모델링하기 위함
- 즉, 어떤 옷과 어떤 액세서리가 잘 어울리는지 추천 가능
| Introduction
-
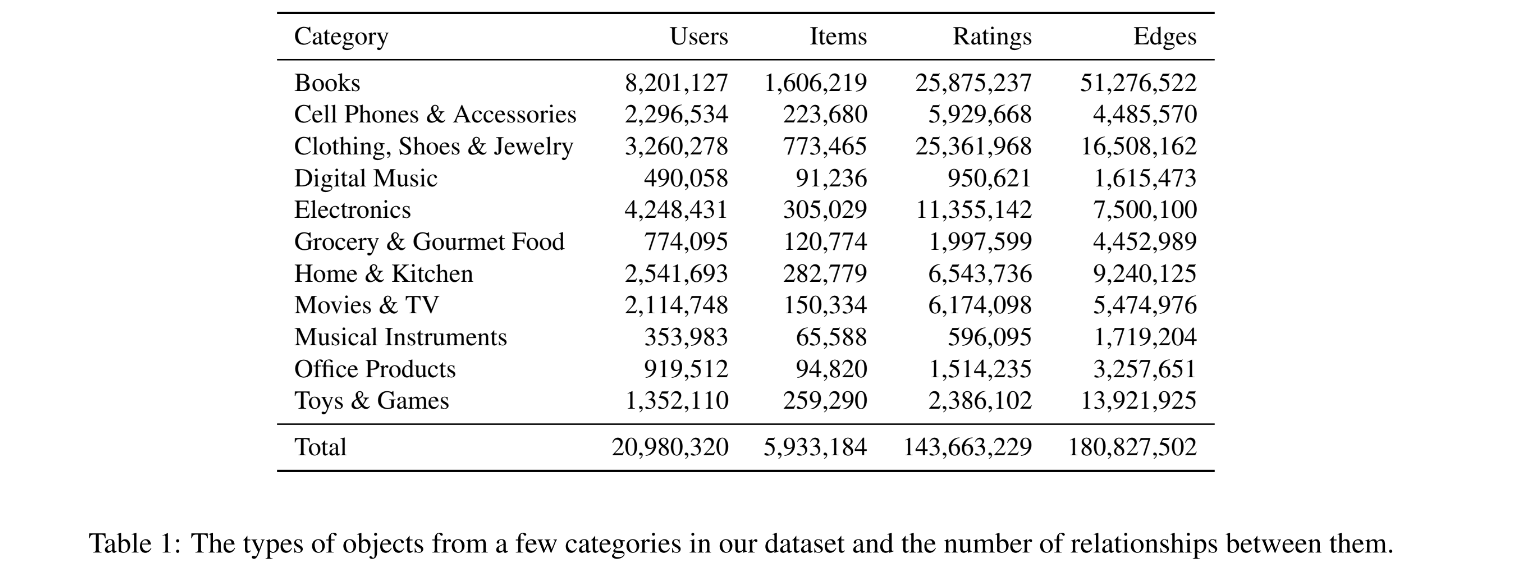
아마존 웹스토어에서 얻은 데이터셋 활용
- 6,000,000개의 상품들에서 180,000,000(1억 8천)개의 관계 나타냄
- 아마존 웹사이트를 방문해서 어떤 특정 웹페이지의 주제에 대한 유저의 관심사를 바탕으로 주어지는 제품 추천을 기록한 결과물
➡️ 이러한 데이터셋을 Styles and Substitutes
-
Substitutes:
- Users who viewed X also viewed Y(65M edges)
- Users who views X eventually bought Y(7.4M edges)
-
Complementary
- Users who bought X and bought Y(104M edges)
- Users bought X and Y simultaneously(3.4M eges)
-
Visual and Relational Recommender System
- 인간의 시각적 선호도를 모델링 하는 것이 목표 ➡️ Styles and Substitutes 데이터셋 활용
- 사용자가 다른 것에 대한 명백한 관심을 표현한 것을 바탕으로 아이템 추천
- 이러한 특성을 일반적인 형태로 확장하여 사용할 수 있지만, 리뷰 또는 그와 유사한 metadata가 아닌 보여지는 것을 기반으로 함
| Model
-
데이터셋에 대해 F차원의 feature vector를
CNN으로부터 얻음 -
Shifted sigmoid함수로 상품간 거리와 확률의 관계를 나타냄. i,j가 관계가 있다면 거리가 가깝고, 그렇지 않다면 거리가 멀다 -
에 따라 이 monotonically 증가하는 를 찾는 것이 목적
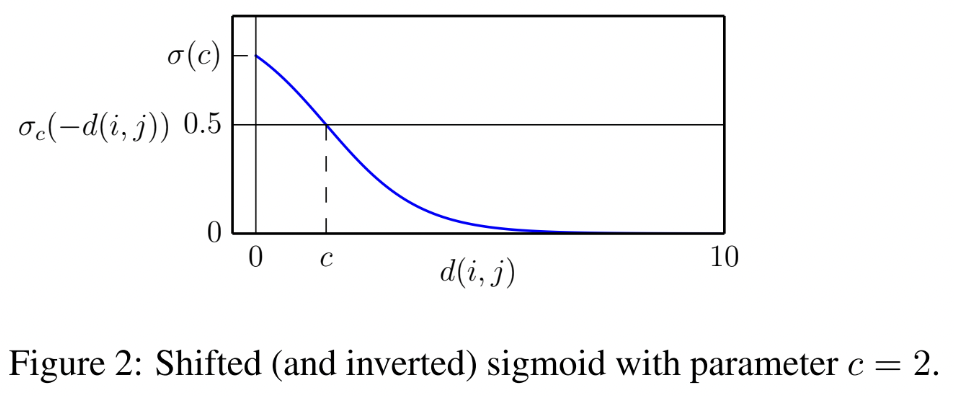
(C: 예측 정확도를 최대화하도록 선택 ➡️ c를 잘 찾아야 됨)
-
Weighted nearest neighbor를 활용하여 상품간의 유사도 또는 관계를 파악
-
mahalanobis transform을 함께 활용 ➡️ 서로 다른 feature가 서로 어떤 관계가 있는지 파악하고자 함
- ex) 바지가 어떤 신발과 관련있는지 파악하는 과정
요약하자면, CNN으로부터 아이템의 feature를 얻고 그 feature들의 거리 계산을 바탕으로 관계에 대한 예측 정확도를 최대화하도록 학습하는 것이 모델의 특징
- Personalized distance function을 정의
- 특정한 User에 대해 각각의 item이 어떤 관계가 있는지 파악 (User가 개입됨)
- 데이터셋에서 유저가 연결된 edge가 있는 경우 이것이 성립한다는 가정을 바탕으로 함
- 유저별 개인화 연구를 위해 평점과 리뷰데이터도 함께 활용
- 각 관계가 존재하는지 여부를 확률로 정의하고, 발견된 관계의 likelihood 확률 값을 최대화하는 것이 학습의 목적
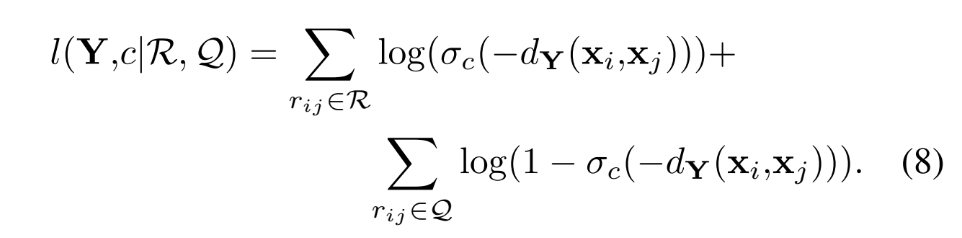
| Conclusions
1. 큰 데이터셋에 대해 시각적으로 관련있는 개념 자체를 모델링하는 것이 가능하다
- CNN으로 추출한 feature들(시각적)을 가지고 인간이 시각물에 대해 어떻게 생각하는지에 대한 개념 자체를 모델링 가능
2. 제안하는 방법으로 간단한 시각적 유사도를 바탕으로 그 관계를 판단하고 모델링하는 것이 가능하다
- 복잡한 유사도가 아닌 간단한 유사도(Weighted nearest neighbor) 측정을 바탕
