
본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 08. Recommender System with Deep Learning
📑 Paper Review
Session-based Recommendation with RNN

- point: Session과 RNN
| Abstract

-
RNN을 추천시스템에 적용
-
Short session-based 상황에서 Matrix Factorization은 정확도가 떨어짐
- netflix 데이터의 경우 user의 history가 많기 때문에 Matrix Factorization, model-based CF에서는 비교적 잘 작동되지만, 이커머스 데이터인 경우 처음 유입된 사용자라면 아이템을 클릭했다가 그 다음엔 어떤 행동을 할 지 모르는 굉장히 짧은 세션에서는 데이터가 너무 없기때문에 Matrix Factorization의 정확도가 떨어질 수 밖에 없다
-
Item-to-item 추천방식을 short session에서 활용하기 함 (item 기반이기때문에 그 사용자를 위한 추천 정확도는 상대적으로 떨어짐)
-
RNN-based 방식을 통해 session-based 추천시스템을 구현 가능
-
RNN의 ranking loss를 변경하여 Session-based recommendation task에서 좋은 성능 얻을 수 있었다
| Introduction
- 현재까지 대부분의 session-based 추천은 간단한 방법을 사용할 수 밖에 없었음
- User profile을 사용하지 못하고(처음 들어온 user의 profile이 당연히 없겠지) item간 유사도, co-occurrence 등을 활용
- E-commerce 분야에서 특히 session-based 추천을 적용하기 어려웠음
- 주로 사용하는 모델은 factor model과 neighborhood method
- Factor model: user profile이 없기때문에 session-based 추천 문제를 풀 수 없음
- Neighborhood method는 유사도와 co-occurrence 기반이기 때문에 session-basd 추천에서 적절히 사용가능했음
-
RNN의 sequential한 특징 덕분에 session-based 추천에 활용 가능함
-
Sparse한 sequential 데이터를 모델링하고 추천시스템에 RNN을 적용
-
새로운 ranking loss를 task에 맞게 다시 제안
-
학습 시
- 사용자가 웹사이트에 들어왔을 때 하는 첫 번째 클릭 = initial input
- 이전 클릭에 따라 사용자는 다음 클릭을 연이어 진행 = output
-
위의 click-stream 데이터셋 (클릭이 이어지는)을 활용하는데, 데이터 사이즈와 scalability가 매우 중요
| Recommendations with RNNs

-
RNN: variable-lengh sequence data에 대해 모델링
-
Standard RNNs의 hidden state
-
sequence의 다음 element에 대한 확률 분포
-
중요한 단점인 Vanishing gradient: 시간에 흐름에 따라 맨 처음 정보 손실 및 기울기 유실 문제 ➡️ Gated Recurrent Unit(GRU)로 보완
- GRU: GRU의 gate를 통해 hidden state를 언제, 얼만큼 업데이트할지 학습
| Customizing the GRU Model
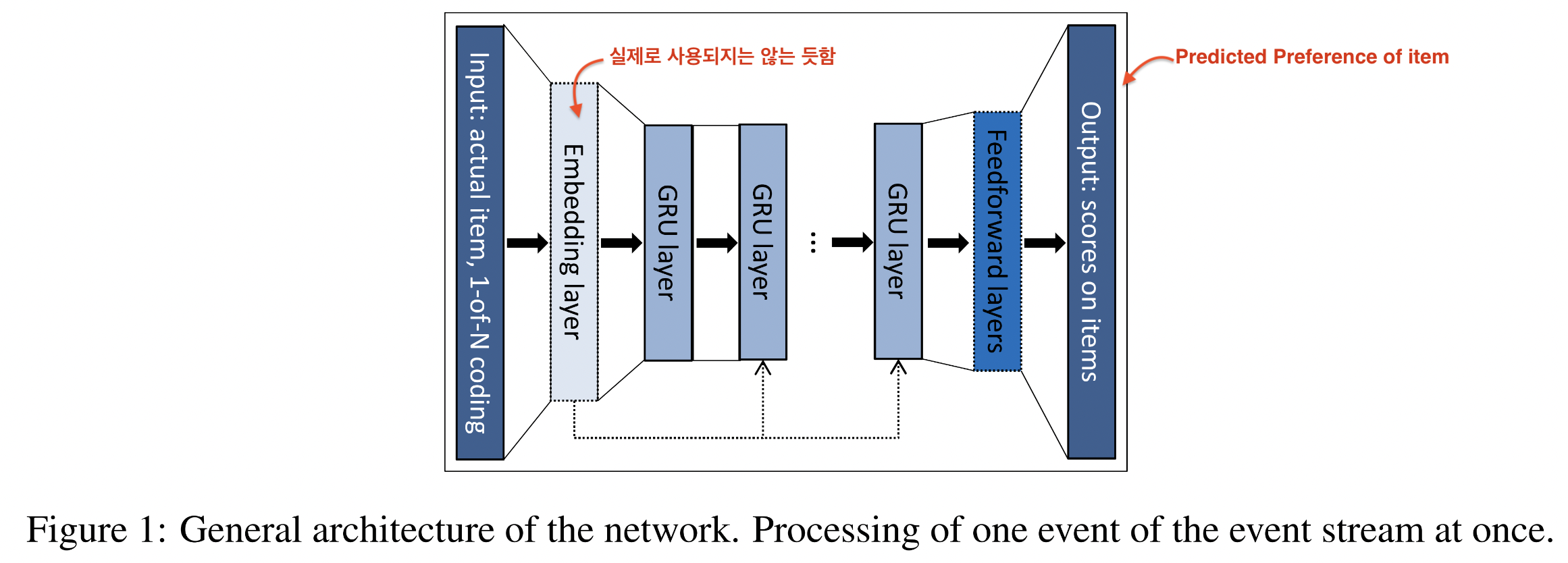
-
Input: Actual state of the session (item)
-
Output: item of the next event in the session
- 해당 item을 얼마나 preference할 지 score를 예측
-
State of the session 정의
- item of the actual event: one-hot vector
- Events in the session: weighted sum of these representations (가중합)
| Session-Parallel Mini-batches
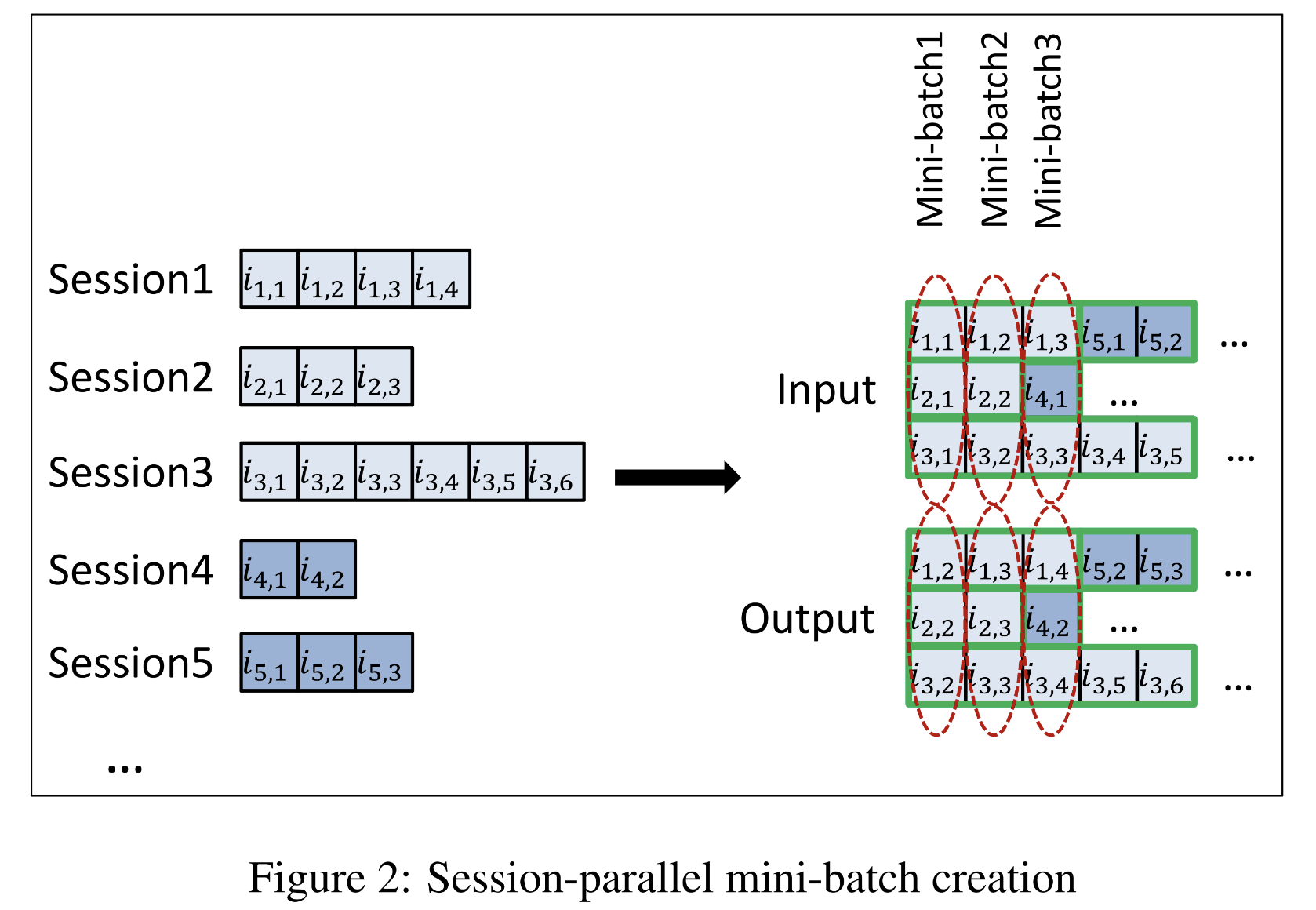
-
기존 RNN batch 방식을 적용할 수 없음
- Session마다 길이가 매우 다름
- 시간 변화에 따라 session이 어떻게 생겨나는지 학습하는 것이 목적
-
Session-parallel mini-batches 방법 선택
-
Session은 모두 독립이며, 새롭게 hidden state를 reset함
| Sampling on the output
-
매 step마다 모든 item에 대해 점수를 계산하는 것은 비효율적 ➡️ 아이템 중 subset만 뽑아서 점수를 계산
-
다음과 같이 sampling을 할 때는 popularity를 고려
- 아이템이 존재하는지 몰랐기 때문에 관심을 갖지 않았다
- 유명한데도 안 봤다면 좋아하지 않을 가능성이 높다
-
따라서 mini-batch에서 다른 학습 데이터를 negative example로 활용
-
이는, mini-batch에서 다른 학습 데이터에 아이템이 존재할 likelihood는 popularity와 비례
| Ranking Loss
- Pointwise: 각 아이템에 점수를 매김
- Pairwise: 유저가 선택한 아이템과 그렇지 않은 아이템을 고르고, 유저가 선택한 아이템을 선택하지 않은 아이템보다 더 선호할 확률을 최대화
- Listwise: 모든 아이템에 점수와 랭킹을 부여하고 랭킹을 바탕으로 정답과 비교
➡️ 논문에서는 Pairwise Loss가 가장 성능이 좋았다고 함
- BRP(Bayesian Personalized Ranking)
- TOP1: relative rank of the relevant item
| Experiments

Best Parameters for GRU4Rec
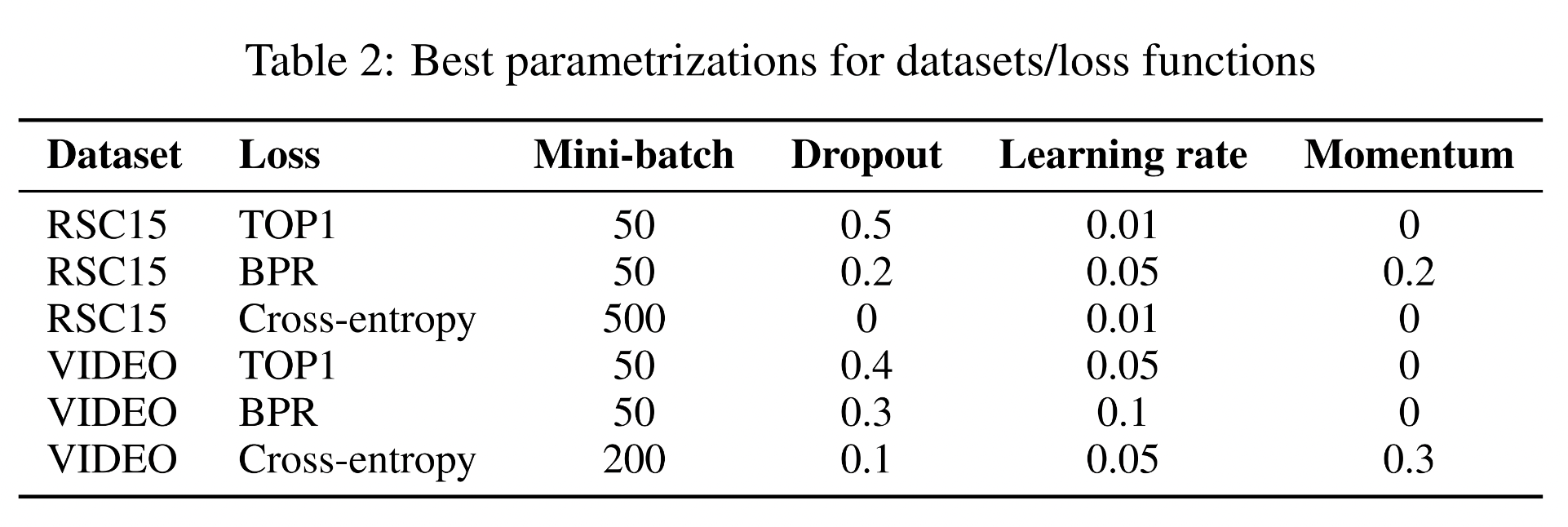
- AdaGrad > RMSProp
- LSTM, RNN < GRU
- Session이 그렇게 길지 않기 때문에 single layer GRU로도 충분
- GRU의 사이즈를 키우는 것은 도움됨 (나머지는 크게 도움 x)
- 세션의 모든 이전 이벤트를 input으로 사용하는 것은 이전 하나만 넣는 것에 비해 성능 향상이 없음 ➡️ GRU 역시 long short term memory 이슈가 있기 때문 (vanishing gradient 문제처럼)
Baseline method 결과
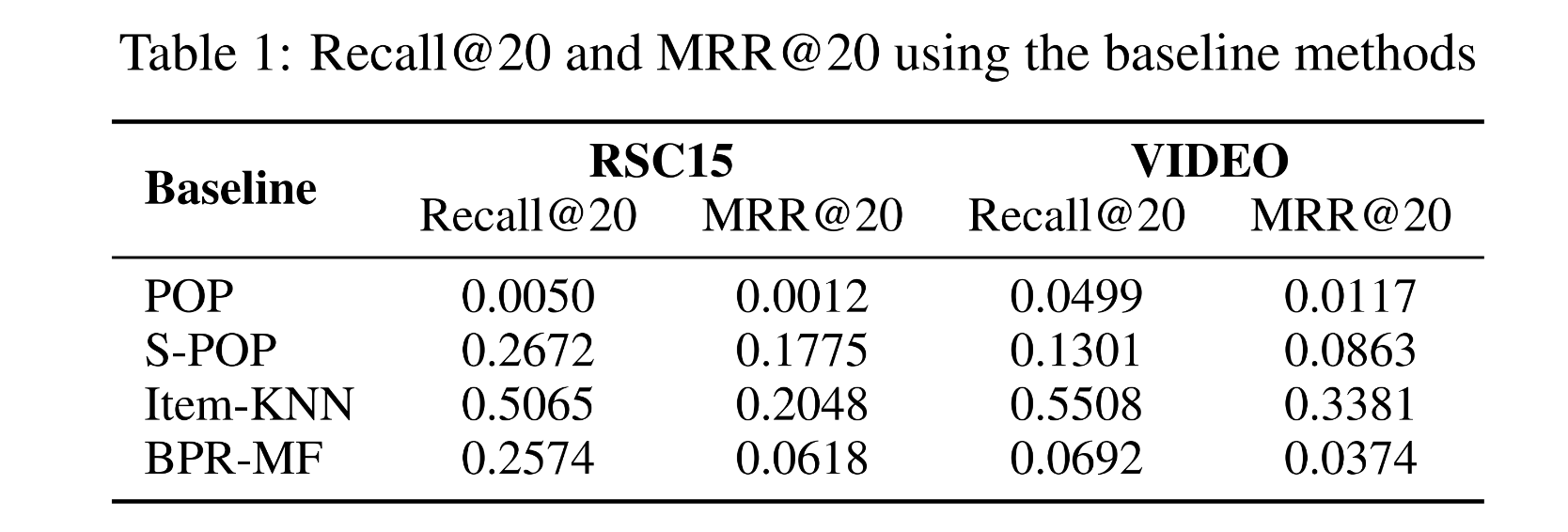
- Item-KNN이 다른 baseline 모델보다 월등히 높은 성능
GRU4Rec의 결과
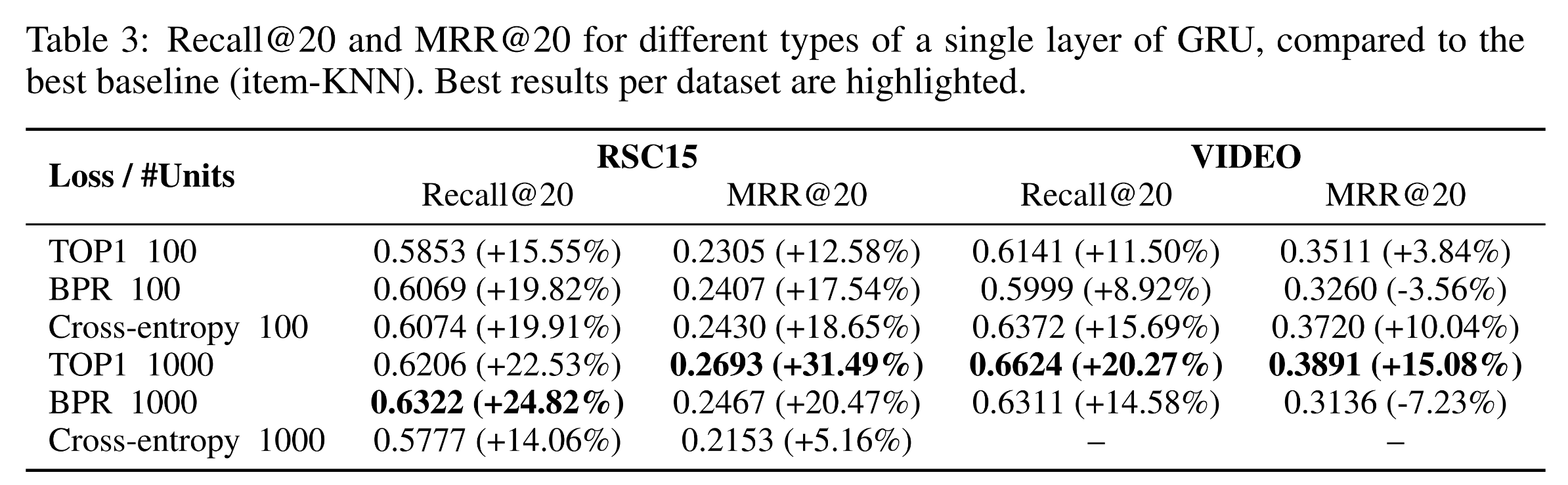
- BPR 1000(Loss / #Units)이 가장 높은 성능
| Conclusions
1. Session-based Recommendation with Recurrent Neural Network(GRU)를 제안
2. Session-based Recommendation를 위한 다음과 같은 방법 제안
- Session-parallel mini-batches
- Mini-batch based output sampling
- Ranking Loss function
3. 이 task에 대해 다른 baseline보다 성능이 월등히 우수함을 확인
+ One more thing to learn: BERT4Rec
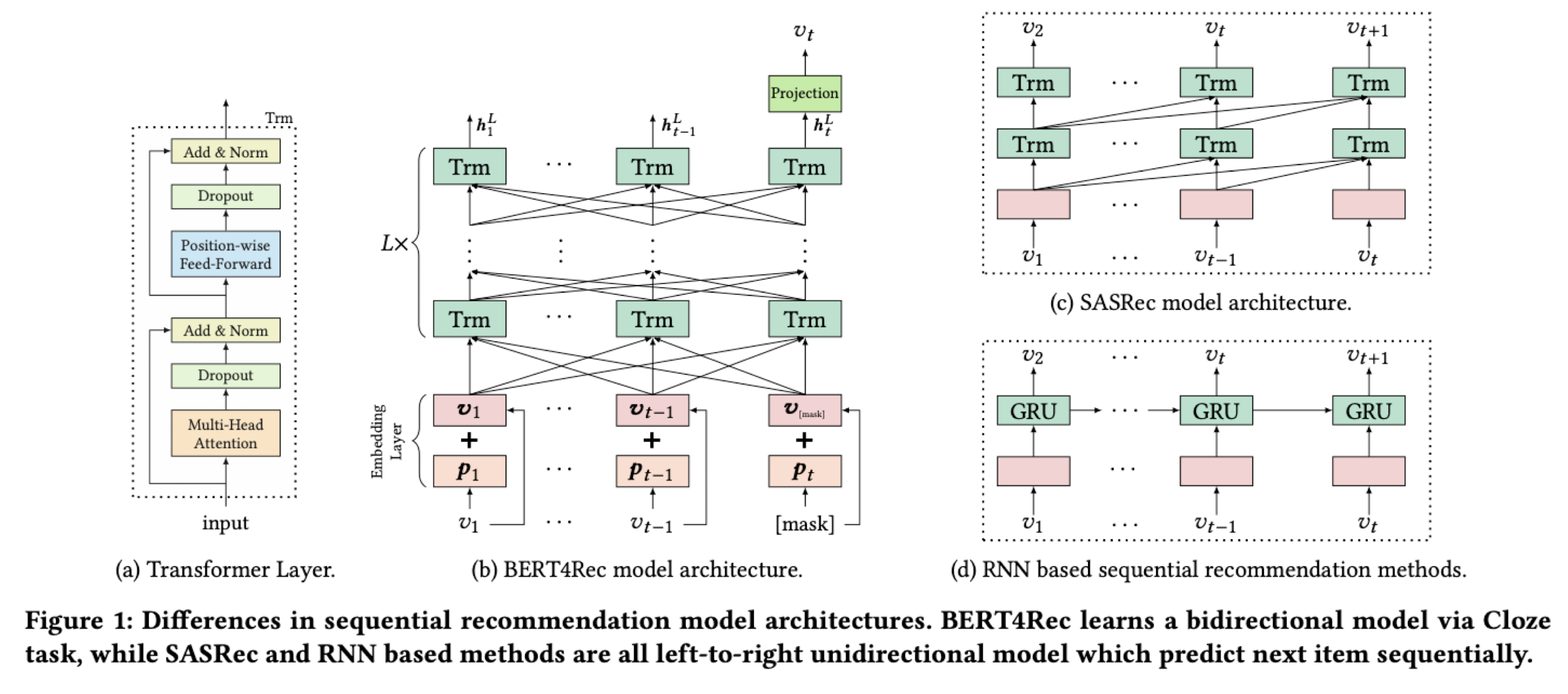
- BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- BERT의 Masked Language Model을 활용하여 next item을 예측하는 모델
