Array(배열)
같은 타입의 변수들로 이루어진 선형 자료구조
논리적 순서(인덱스)와 물리적 순서(메모리 주소)가 같다.
Element (요소): 배열을 구성하는 각각의 값Index(인덱스): 배열에서 위치를 가리키는 숫자. 요소에 대한 유일무이한 식별자
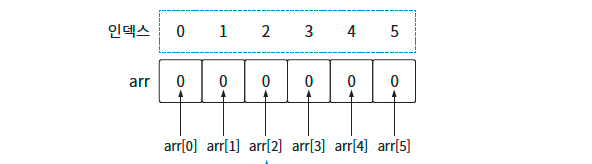
특징
- 여러 개의 데이터를 한 번에 다룰 수 있다.
- 한 번 만들어진 공간은 크기가 고정된다.
- 요소 삭제 시에도 해당 공간이 그대로 남아있다. → 메모리 낭비
- 메모리 상에 데이터가 연속적으로 저장된다.
- 인덱스를 활용해 데이터에 바로 접근이 가능하고, 빠른 데이터 조회가 가능하다.
- Object는 아니지만 Reference Value로 취급한다.
배열의 시간복잡도
삽입/삭제
배열의 맨 앞, 중간에 삽입/삭제 : O(n)
배열의 맨 뒤에 삽입/삭제 : O(1)
탐색 : O(1)
주요 List 인터페이스 구현 클래스
(다형성 : 모든 종류는 리스트형으로 표현 가능)
- ArrayList
- LinkedList
- Vector = growable한 배열. 값 추가/삭제 시 동기화 작동 → 멀티쓰레드 환경에 유리
-> index에 빠르게 접근해야 할 때 : Array 특징 가진 ArrayList, Vector 사용 유리
그 중에서도 먼저 LinkedList에 대해 알아보자.
LinkedList (연결리스트)
데이터를 일렬로 늘여놓은 형태의 선형 자료구조
노드: 헤드와 테일의 형태로 이루어짐
각 노드의 테일에 다음 노드의 주소 정보가 저장되어 꼬리에 꼬리를 물고 연결된다.
특징
- 여러 개의 데이터를 한 번에 다룰 수 있다.
- 삽입/삭제 연산이 용이
- 메모리 상에 연속으로 할당할 필요가 없어 메모리 재사용 가능, 낭비가 적다.
- 원소의 추가, 삭제에 따라 크기가 동적으로 변한다. = 유연성
- 목표 위치 알려면 첫 위치로 부터 한 칸씩 이동하며 찾아야 한다.
연결리스트의 시간복잡도
삽입
리스트 맨 앞에 삽입 : O(1)
리스트 중간에 삽입 : O(n)
삭제
리스트 맨 뒤에 삽입/삭제 : O(1)
리스트 중간에 삭제 : O(n)
탐색 : O(n)
→ 리스트 처음부터 링크를 타고 순차적으로 탐색해야 하기 때문
메서드 종류
| 메서드 | 기능 |
|---|---|
| add(element) | 요소 추가 |
| add(index, element) | index 다음 위치에 요소 추가 |
| addFirst(e), addLast(e) | 맨 앞 / 맨 뒤에 요소 추가 |
| addAll(Collection) | Collectioin의 모든 요소를 추가 |
| remove(index) | Index 위치의 요소 삭제 |
| clear() | 모든 요소 삭제 |
| get(index) | Index 위치의 요소 가져오기 |
| getFirst(index) / getLast(index) | 맨 앞 / 맨 뒤 요소 가져오기 |
| indexOf(object) | 요소의 index 찾기 |
| contains(object) | 특정 요소가 존재하는지 T/F |
| size() | 리스트의 크기 |
| isEmpty() | 리스트가 비어있는지 T/F |
연결리스트의 종류
단일 연결리스트
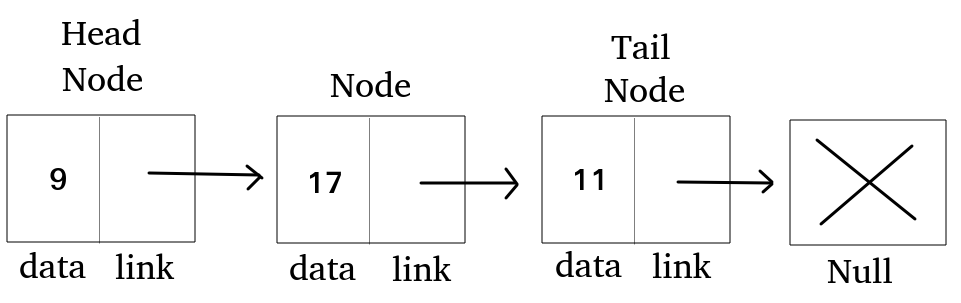
일반적인 연결리스트
연속되지 않은 메모리에 저장된 데이터들을 연결시키므로
하나의 노드는데이터 필드와링크 필드로 구성된다.
data에 데이터 값을 저장하고,Link에 다음 노드의 주소값을 저장한다,
- 마지막 노드(tail)의 링크 필드는 null
- 단방향으로 연결된 리스트
원형 연결리스트
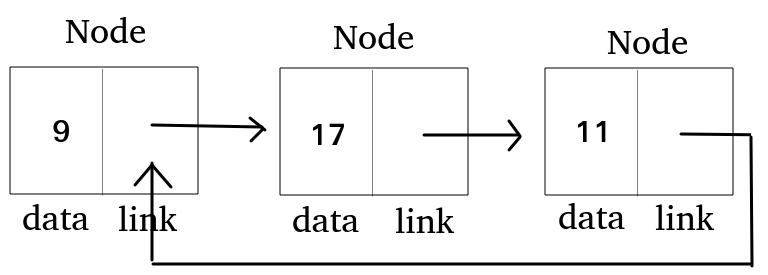
- 마지막 노드(tail)의 링크 필드는 맨 앞의 노드(head)
- 단방향으로 연결된 리스트
이중 연결리스트
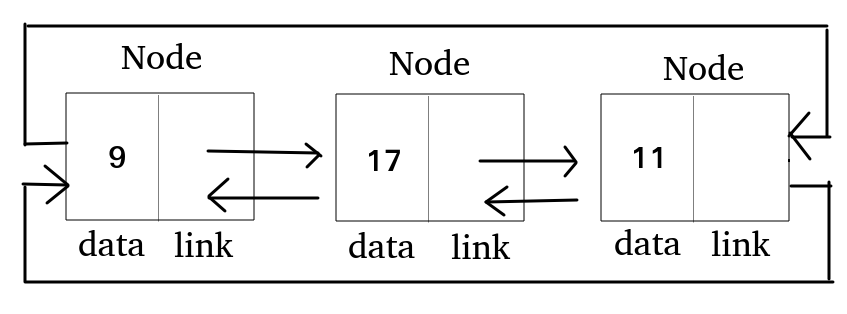
단일 연결리스트나 원형 연결 리스트는 현재 노드의 이전 노드에 접근하기 위해서는 리스트를 처음부터 순회해야 한다는 단점이 존재한다.
-> 이를 보완하기 위해 이전 노드의 주소를 저장한 것이 이중 연결리스트.
- 양방향으로 연결된 리스트
- 링크 필드는 이전 노드 주소를 저장하는
Left Link Field와 다음 노드 주소를 저장하는Right Link Field를 가진다.
ArrayList
배열 기반의 리스트로 동적인 길이를 가질 수 있다.
사이즈를 나타내는capacity인스턴스 변수를 가진다.
ArrayList에 요소들이 추가되면capacity가 자동으로 늘어난다.
| 메서드 | 기능 |
|---|---|
| add(element) | 요소 추가 |
| insert(index, element) | 인덱스 위치에 요소 추가 |
Array vs LinkedList
Array와 LinkedList의 가장 큰 차이는 인덱스의 유무와 삽입/삭제 가능여부이다.
- 인덱스의 유무
배열은인덱스가있기 때문에 빠른 데이터 조회가 가능하지만, 원소가 삭제되어도 인덱스를 유지하기 위해 해당 메모리를 유지해야 한다는 단점이 있다.
리스트는 이러한 메모리 낭비를 줄이기 위해 인덱스를 포기하고,노드를 연결해 데이터를 적재한다.
- 삽입/삭제 가능여부
배열은 사이즈 변경이 불가능하므로 요소의 추가적인 삽입/삭제 또한 불가능하다.
리스트는 새로운 요소에 할당된 메모리 위치가 LinkedList 이전 요소에 저장되는 방식으로 삽입/삭제가 가능하다.
Array와 LinkedList의 시간복잡도를 한 눈에 보기 쉽게 다시 정리해보자면
| 시간복잡도 | Array | LinkedList |
|---|---|---|
| 원소 접근 | O(1) | O(n) |
| 삽입 / 삭제 | O(n) | O(1) 단, 해당 원소의 위치를 알고 있는 경우 |
| 메모리 상의 배치 | 연속 | 불연속 |
자주 사용하는 Array, List 관련 문법 정리
Array → List ( 배열이 Reference 타입일 경우 )
Integer[] arr = new Integer[]{1,2,3,4,5};
List<Integer> list = Arrays.asList(arr);List → Array
//Reference 타입일 경우
List <Integer> list = Arrays.asList(1,2,3,4,5);
Integer[] arr = list.toArray(Integer[]::new);
list.stream().toArray(String[]::new);
list.stream().mapToInt(Integer::intValue).toArray();- mapToInt : primitive 타입으로 변경
리스트에서 최댓값 구하기
Arrays.stream().max().getAsInt();
for(int i=0; i<arr.length; i++){
if(arr[i] == max) list.add(i);
}
list.stream().mapToInt(Integer::intValue).toArray();
//stream 사용해 변환
Intstream.range(0, arr.length)
.filter(i → arr[i]==max)
.toArray();[참고]
https://bigbigpark.github.io/data_structure/linkedlist
https://hodie.tistory.com/89
