목차 요약
1. 논문 기본 정보
2. 연구 배경 및 목적
3. 모델 개요 및 구조
4. Dataset
5. 아키텍처 및 Reducing Overfitting
6. Details of Learning
7. 결과 및 성과
8. 장점 및 단점
9. 개인 인사이트
10. 참고 문헌
추가 설명
1. 논문 기본 정보
- 제목: Depth Anything V2
- 저자: Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
- 소속: HKU, TikTok
- 발표: 38th NeurIPS 2024
- 공식 홈페이지: depth-anything-v2.github.io
2. 연구 배경 및 목적
연구 배경
- 단안은 3D 재구성, 자율주행, AI 기반 콘텐츠 생성 등 다양한 응용 분야에서 핵심 기술로 자리잡고 있음
- 기존의 Depth Anything V1은 견고한 예측을 보였으나, 미세한 구조 표현과 투명/반사 표면 처리에서 한계를 보임
연구 목적
- 정밀도 강화: 합성 이미지의 정밀 라벨링을 통해 세밀한 객체 경계와 얇은 구조도 정확하게 예측
- 일반화 향상: 대규모 unlabeled real images에 대해 고성능 teacher 모델이 생성한 의사 라벨을 활용, 실제 환경의 다양성을 반영
- 효율성 및 확장성: 다양한 파라미터 크기의 모델을 제공하여, 실시간 응용부터 정밀 후처리까지 모두 지원
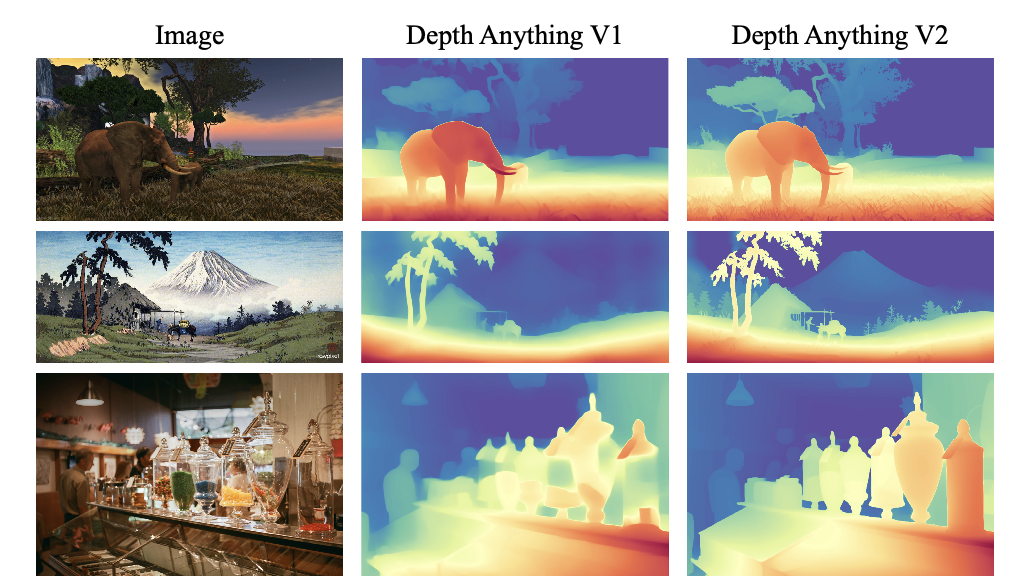
3. 모델 개요 및 구조
모델 개요
- Teacher-Student Framework:
- Teacher 모델: 고성능 DINOv2-G 기반으로 합성 데이터를 통해 학습
- Student 모델: Teacher가 생성한 pseudo label을 활용해 경량화된 모델로 학습
- 전략:
- 합성 데이터로 정밀한 라벨 확보
- 대규모 실제 데이터의 다양성을 pseudo labeling으로 보완
모델 구조
- 데이터 흐름:
- 합성 데이터 → Teacher 모델 학습
- Unlabeled real images → Teacher 모델로 pseudo label 생성
- Pseudo-labeled 데이터 → Student 모델 학습
- 구성 요소:
- Encoder: DINOv2 계열 모델 (small, base, large, giant 등)

4. Dataset
- 합성 데이터:
- 고정밀 라벨이 가능한 합성 이미지 데이터셋을 활용하여 미세한 객체 경계와 얇은 구조를 정확하게 캡처
- 실제 데이터:
- 약 62M의 unlabeled real images를 수집하여, Teacher 모델을 통해 의사 라벨을 생성
- 평가 데이터셋:
- 기존 NYU-D, KITTI 외에 다양한 장면과 해상도를 포함하는 새로운 평가 벤치마크 DA-2K 구축
5. 아키텍처 및 Reducing Overfitting
아키텍처
- Teacher 모델:
- 대규모 합성 데이터셋을 사용하여, 정밀한 깊이 정보를 학습
- Student 모델:
- Teacher로부터 생성된 고품질 pseudo label을 활용해, 보다 경량화된 모델을 학습
Reducing Overfitting
- Synthetic-to-Real Transfer:
- 합성 이미지의 정밀 라벨과 실제 이미지의 다양성을 결합, 도메인 갭을 줄여 일반화 능력을 향상
- Pseudo Label 활용:
- 노이즈가 많은 실제 라벨 대신 Teacher가 생성한 의사 라벨로 오버피팅 문제를 완화
- 데이터 증강:
- 다양한 변형 기법을 통해 데이터의 다양성을 높여 모델이 다양한 패턴을 학습하도록 유도
6. Details of Learning
학습 과정
- Teacher 모델 학습:
- 합성 데이터셋을 사용해 정밀한 깊이 정보를 학습
- Pseudo Label 생성:
- 학습된 Teacher 모델로 unlabeled real images에 대한 의사 라벨 생성
- Student 모델 학습:
- 생성된 pseudo label을 바탕으로 다양한 규모의 모델을 학습하여, 경량화와 실시간 추론 지원 달성
7. 결과 및 성과
- 세밀한 예측 성능:
- Depth Anything V2는 기존 V1보다 얇은 구조, 미세한 객체 경계, 그리고 투명/반사 표면에 대해 더욱 정확한 예측을 보임
- 견고성 및 일반화:
- 다양한 실제 장면에서 우수한 성능을 기록하며, 새로운 평가 벤치마크에서 높은 정확도를 달성
- 모델 확장성:
- 25M부터 1.3B까지 다양한 파라미터 크기를 제공, 응용 분야에 따라 최적의 모델 선택이 가능
- 실험 결과:
- 기존 모델 대비 10% 이상의 성능 향상 및 상대 깊이 판별 정확도 향상 등 여러 지표에서 우수한 성과를 기록
8. 장점 및 단점
장점
- 세밀한 예측: 미세한 구조와 얇은 객체 경계까지 정확하게 예측
- 우수한 일반화: 다양한 복잡한 장면에서도 견고한 성능 발휘
- 유연한 모델 확장성: 다양한 모델 크기를 제공하여, 실시간 및 후처리 적용 모두 가능
단점
- 연산 및 학습 비용: 대규모 데이터와 고성능 Teacher 모델 사용으로 인한 높은 자원 소모
- 합성 데이터 한계: 합성 이미지의 장면 다양성이 실제 환경의 모든 변수를 반영하기에는 제한적
9. 개인 인사이트
1. 합성 이미지와 대규모 실제 데이터 결합의 혁신성
- 합성 데이터의 정밀한 라벨링과 실제 데이터의 현실적인 다양성을 결합하는 방식은 두 데이터 소스의 강점을 모두 활용 가능
2. 실제 서비스 및 프로젝트 적용 시 도전 과제
- 연산 비용: 대규모 데이터와 고성능 teacher 모델 운영으로 인한 높은 자원 소모는 실제 적용 시 큰 도전 과제
- 데이터 다양성 확보: 합성 데이터의 한계로 인해 실제 환경의 모든 변수를 반영하기 위해 추가적인 데이터 확보와 정제가 필요
3. 비교
- 제 경험상, 데이터의 정밀도가 모델 성능에 미치는 영향은 매우 크며, 논문에서 합성 이미지의 정밀 라벨링을 강조한 점은 깊이 공감함
4. 제한된 리소스 환경에서의 추가 아이디어
- 모델 압축 및 최적화: Pruning, quantization, 또는 sparse training 기법을 활용해 모델의 크기를 줄이고 추론 속도를 높이는 전략을 고려할 수 있음
- 효율적인 데이터 샘플링: 전체 데이터를 모두 사용하기보다는 대표성 높은 데이터 샘플을 선별해 학습함으로써 연산 비용을 절감하는 전략이 도움이 될 것 같음
10. 참고 문헌
- Depth Anything V1 논문
- MiDaS 시리즈 논문
- Marigold 및 기타 단안 깊이 추정 관련 최신 연구
추가 설명
Pseudo Label:
: 실제로 라벨이 없는 데이터를 고성능 모델이 예측하여 생성한 '가짜' 라벨
-> 실제 라벨이 부족한 상황에서도 모델을 추가로 학습시킬 수 있어 데이터 확장을 도와줌
Reducing Overfitting:
: 모델이 학습 데이터에 너무 치중되어 새로운 데이터에서 성능이 떨어지는 현상을 방지하는 방법
-> 다양한 기법(데이터 증강, 정규화)을 사용하여 모델이 일반화되어 다양한 상황에서도 잘 작동하도록 함
Synthetic-to-Real Transfer:
: 합성 데이터로 모델을 학습시킨 후, 실제 데이터로 전이하는 과정을 의미
-> 합성 데이터는 라벨링이 정확하다는 장점이 있지만, 현실과 약간의 차이가 있을 수 있기 때문에 실제 데이터에 맞게 모델을 조정하는 전략
