Hash Table
해시함수를 사용해 변환한 값을 index로 삼아 key와 value를 저장하는 자료구조이다.
해시 테이블은 특정 값을 받아서 해시 함수에 입력하고, 함수의 출력값을 인덱스로 삼아 데이터를 저장한다.
자바의 Map이 대표적 예이다.
해시란?
해시란 단방향 암호화 기법으로 해시 함수를 이용하여 고정된 길이의 암호화된 문자열로 바꿔버리는 것을 의미한다.
이때 매핑 전 원래 데이터의 값을 key, 매핑 후 데이터의 값을 hash value, 매핑하는 과정을 hashing이라고 한다.
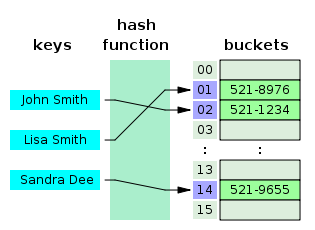
해시 함수를 이용해서 key를 hash value로 매핑하고, 이 hash value를 index로 삼아 데이터의 value를 buckets(혹은 slots)에 저장하는 과정
해시 함수란?
해시함수는 임의의 길이를 갖는 임의의 데이터에 대해 고정된 길이의 데이터로 매핑하는 함수를 말한다.
같은 입력 값(key)에 대해서는 같은 출력 값(index)가 출력 된다.
어떤 해시 함수를 사용하느냐에 따라 해시 검색의 성능이 결정되기 때문에 좋은 해시 함수를 사용해야 한다.
좋은 해시 함수의 조건
- 키를 고르게 분포시킬 수 있어야 함.
- 충돌 발생 빈도가 적어야 함.
- 빠른 연산.
특징
- 기본 연산으로는 search, insert, delete가 있다.
- 순차적으로 데이터를 저장하지 않는다.
- key를 통해서 value를 얻을 수 있다. => 이진탐색트리나 배열에 비해서 속도가 획기적으로 빠름
- 커다란 데이터를 해시해서 짧은 길이로 축약할 수 있기 때문에 데이터를 비교할 때 효율적이다.
- value는 중복 가능하지만 key는 유니크해야 한다.
- 수정 가능하다. (=> mutable)
- 보통 배열로 미리 hash table 사이즈만큼 생성 후에 사용한다.
- 인덱스 주소와 값이 저장되는 곳을 버킷(bucket) 또는 슬롯(slot)이라고 한다.
해시 충돌
하나의 원 데이터는 하나의 해시값(index)만 가지지만, 하나의 해시값을 만들어낼 수 있는 원본 데이터는 매우 많다.
예시
- 해시 테이블을 활용한 해싱은 0 ~ 10까지 데이터를 담을 수 있는 리스트(해시테이블)을 생성하고 ‘cake’이라는 단어에 해시함수를 적용하여 ‘4’라는 인덱스가 생성되면 리스트 4번 인덱스에 ‘cake’를 저장하는 방식이다.
- 해시 함수는 언제나 동일한 입력에 대해 동일한 값을 반환하므로 ‘cake’를 입력하면 항상 ‘4’라는 인덱스가 나오므로 해당 인덱스를 통해 바로 원 데이터에 접근할 수 있다.
- 이때, ‘taco’ 라는 단어의 해시 값이 ‘4’로 나온다면 cake와 동일한 인덱스를 갖는 해시 충돌이 발생한다.
충돌 완화
해시 충돌을 완화하는 데는 다양한 방법이 있다. 개방 주소법(open addressing)으로 해시 테이블 크기는 고정하면서 저장할 위치를 잘 찾거나,
분리 연결법 (seperate chaining)으로 해시 테이블의 크기를 유연하게 만드는 방법이 대표적이다.
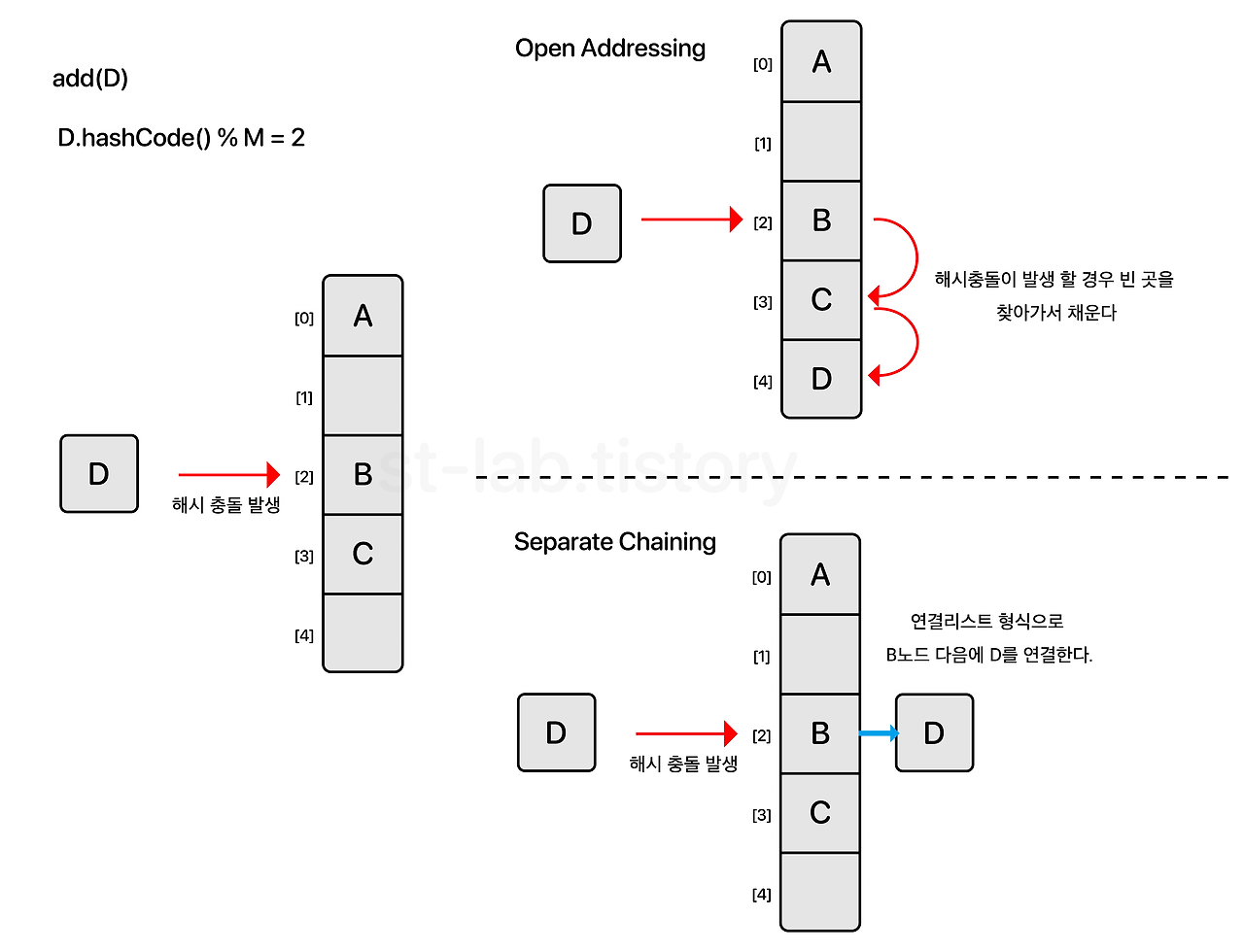
1. 개방 주소법
open addressing은 한 버킷 당 들어갈 수 있는 엔트리는 하나이지만 해시 함수로 얻은 주소가 아닌, 다른 주소에 데이터를 저장할 수 있도록 허용하는 방법이다.
하지만 이 방법은 부하율(load factor)이 높을 수록(= 테이블에 저장된 데이터의 밀도가 높을수록) 성능이 급격히 저하된다.
개방 주소법의 주요 목적은 저장할 엔트리를 위한 다음의 slot을 찾는 것인데 이 방법으로 3가지가 널리 쓰인다.
(1) 선형 탐사법 Linear Probing
말 그대로 가장 간단하게 선형으로 순차적 검색을 하는 방법이다. 해시 함수로 나온 해시 index에 이미 다른 값이 저장되어 있다면, 해당 해시값에서 고정 폭을 옮겨 다음 해시값에 해당하는 버킷에 액세스한다.
(2) 제곱 탐사법 Quadratic Probing
선형 탐사법과 동일한데, 고정폭이 아니라 제곱으로 늘어난다. 따라서 2^1, 2^2, 2^3로 이동해서 데이터를 할당한다.
(3) 이중 해싱 Double Hashing
이 외에도 이중 해싱(double hashing) 방법이 있다. 이 방법은 탐사할 해시값의 규칙값을 없애서 클러스터링을 방지한다.
즉 해시 함수를 이중으로 사용하는데, 하나는 최초의 해시값을 얻을 때, 다른 하나는 해시 충돌이 일어났을 때 탐사 이동폭을 얻기 위해 사용한다.
이렇게 되면 최초 해시값이 같더라도 탐사 이동폭이 달라지고, 탐사 이동폭이 같더라도 최초 해시값이 달라져 위의 두 방법을 모두 완화할 수 있다.
2. 분리 연결법
분리 연결법은 개방 주소법과는 달리 한 버킷(슬롯) 당 들어갈 수 있는 엔트리의 수에 제한을 두지 않는다.
이때 버킷에는 링크드 리스트(linked list)나 트리(tree)를 사용한다.
해시 충돌이 일어나더라도 linked list로 노드가 연결되기 때문에 index가 변하지 않고 데이터 개수의 제약이 없다는 장점이 있다.
하지만 메모리 문제를 야기할 수 있으며, 테이블의 부하율에 따라 선형적으로 성능이 저하된다. 따라서 부하율이 작을 경우에는 open addressing 방식이 빠르다.
시간복잡도
해시 테이블은 key-value가 1:1 매핑되어 있기 때문에 검색, 삽입, 삭제 과정에서 모두 평균적으로 O(1)의 시간복잡도를 갖는다.
공간 복잡도는 O(N)인데 여기서 N은 키의 개수다.
하지만 데이터의 충돌이 발생한 경우 Chaining에 연결된 리스트들까지 검색을 해야 하므로 O(N)까지 시간복잡도가 증가할 수 있다.
