프로젝트를 진행하면서 일정 시간마다 특정 로직을 실행시켜줘야 하는 경우가 여러 번 있었고 그때마다 나는 @Scheduled(cron = "0 0 12 * * ?") 어노테이션을 사용해서 특정 로직을 일정 시간마다 실행시켜줬다. 그런데 대량의 데이터를 처리하거나 더욱 더 복잡한 비즈니스 로직을 포함한 작업을 효율적으로 실행시키기 위해서는 스프링의 Batch를 사용한다는 글을 봐서 이번 기회에 스케줄러 대신에 배치를 사용해 보기로 했다.
내가 스프링 배치를 사용해보기 전에 우선 스케줄러와 배치의 개념에 대해서 알아보기로 했다.
1. 스케줄러 (Scheduler)
스케줄러의 주된 목적은 특정 시간 간격 또는 일정에 따라 단순 작업을 반복적으로 실행하는 것이다.
사용하는 방법은 위에서 말했듯이 @Scheduled 어노테이션을 사용하면된다.
스케줄러의 특징은
- 어노테이션 하나만 붙이면 되는만큼 간단하고 빠르게 설정할 수 있다.
- 주로 짧은 기간 동안 실행되는 작업 즉 짧은 시간 안에 완료되는 작업에 적합하다.
- 기본적으로 스프링의
TaskScheduler를 사용하며, 멀티스레드로 동작 가능하다 - 상태 관리가 복잡하지 않고, 트랜잭션 관리나 대규모 데이터 처리에는 부적합하다.
여기서 스프링의 TaskScheduler란 스프링에서 제공하는 스케줄링 인터페이스로, 주기적으로 반복 실행되거나 특정 시간에 실행되는 작업을 관리하는 데 사용된다.
2. 배치 (Batch)
배치의 주된 목적은 위에서 말했듯이 대량의 데이터를 처리하거나 복잡한 비즈니스 로직을 포함한 작업을 효율적으로 실행하는 것이다.
배치의 사용 방법은 Spring Batch를 사용해서 배치 잡(Job), 스텝(Step), 리더(Reader), 프로세서(Processor), 라이터(Writer) 등을 정의해서 작업을 수행한다.
배치의 특징은
- 대규모 데이터 처리, 트랜잭션 처리, 실패 관리, 체크포인트 등의 기능을 제공한다
- 병렬 처리나 대량의 데이터 작업, 복잡한 로직을 실행하는 데 적합하다
- 배치 작업의 흐름(Flow)를 관리하고, 여러 단계(Step)으로 구성할 수 있다
- 데이터베이스 또는 외부 시스템과의 연동을 통해 데이터를 읽고 쓰는 작업을 쉽게 구현할 수 있다
- 스케줄러와 결합해서 특정 시간에 배치 작업을 실행하는 것도 가능하다
@Bean
public Job sampleJob() {
return jobBuilderFactory.get("sampleJob")
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<InputType, OutputType>chunk(10)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
언뜻 봐도 스케줄러에 비해 배치의 난이도가 훨씬 높아 보이긴 하는 것 같다.
스케줄러 VS 배치
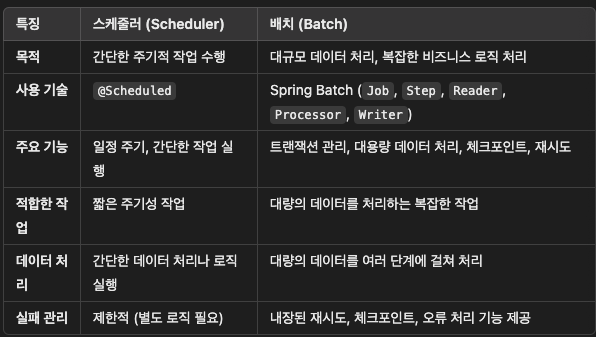
결론적으로 스케줄러는 단순하고 주기적으로 수행할 작업을 실행하는 데 적합하며, 배치는 대규모 데이터 처리를 수행하고 복잡한 로직이 필요한 경우에 적합하다. 스케줄러를 사용해 배치 작업을 주기적으로 실행할 수도 있으며, 두 가지 기능을 서로 상호 보완적으로 사용할 수 있다
그럼 내가 작성한 스케줄러를 사용한 코드를 배치와 함께 사용할 수 있도록 리팩토링 해보겠다.
@Slf4j
@RequiredArgsConstructor
@Service
@EnableScheduling
public class MemberScheduled {
private final MemberRepository memberRepository;
@Scheduled(cron = "*/10 * * * * *")
public void deleteMembersFromDb() {
log.info("Deleting members");
log.info("삭제 처리 중");
List<MemberEntity> deleteMembers = memberRepository.findAllByIsDeletedTrue();
for (MemberEntity memberEntity : deleteMembers) {
LocalDateTime lastConnectionAt = memberEntity.getLastConnectionAt();
if (lastConnectionAt != null) {
if (ChronoUnit.DAYS.between(lastConnectionAt, LocalDateTime.now()) > 7) {
memberRepository.delete(memberEntity);
log.info("Delete member: {}", memberEntity.getProviderId());
}
}
}
log.info("Deleting members");
}
}일단 위의 코드는 매일 자정마다 memberRepository에서 isdeleted가 true인 member들 중에 lastConnectionAt이 일주일이 지난 member를 memberRepository에서 삭제하는 스케줄러를 사용한 로직이다. 그래서 이 로직을 배치와 함께 사용하는 것으로 바꿔보기로 했다.
첫번쨰로 전체적인 배치를 설정하는 BatchConfig 클래스를 만들어야 한다
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Bean
public Job deleteMemberJob(Step deleteMemberStep, JobRepository jobRepository) {
return new JobBuilder("deleteMemberJob", jobRepository)
.start(deleteMemberStep)
.build();
}
@Bean
public Step deleteMemberStep(ItemReader<MemberEntity> reader, ItemProcessor<MemberEntity, MemberEntity> processor,
ItemWriter<MemberEntity> writer, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("deleteMemberStep", jobRepository)
.<MemberEntity, MemberEntity>chunk(10, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
}우선 @EnableBatchProcessing 어노테이션으로 Spring Batch 기능을 활성화 시켜줘야 한다.
그리고 Job을 설정해야 한다. JobBuilder를 사용해서 배치 작업(Job)을 구성한다. Job은 하나 이상의 Step으로 구성된 전체 배치 작업의 흐름을 정의하는 객체이다.
start(deleteMemberStep) 현재 메소드의 Job이 deleteMemberStep 을 첫 번째 단계로 설정한 것이다.
이
Job은deleteMemberStep이라는 단일Step을 실행하며, 회원 삭제 작업을 처리한다.
다음으로 회원 삭제 작업을 처리하는 Step을 설정한다.
chunk(10) 이 부분에서 CHunk 기반 처리를 설정한다 즉 ItemReader는 한 번에 10개의 데이터를 읽고, ItemProcessor는 이 10개의 데이터를 처리하며, ItemWriter는 처리된 데이터를 한 번에 10개씩 DB에 반영한다.
그 후 이 Step에서 사용할 itemReader, writer, ItemReader를 지정한다
이 메소드의 Step의 역할은 ItemReader를 사용해서 회원 데이터를 DB에서 읽어오고, ItemProcessor를 사용해서 읽어온 데이터 중에서 조건에 맞는 데이터를 필터링 또는 처리하고 ItemWriter를 사용해 처리된 데이터를 DB에 반영하거나 삭제한다.
다음은 Spring Batch의 ItemReader를 구현한 MemberItemReader 클래스이다. 이 클래스는 삭제 대상 회원의 목록을 읽어 오는 역할을 한다. ItemReader가 배치 작업에서 데이터를 읽는 단계를 담당하며, 그 후에 ItemProcessor와 ItemWriter로 데이터를 전달한다.
즉 MemberRepository를 사용해서 isDeleted가 true로 설정된, 삭제 대상인 회원 목록을 DB에서 가져온 후에 하나씩 반환하며, 더 이상 반환할 데이터가 없으면 null 을 반환하여 읽기 작업을 종료한다.
@Component
public class MemberItemReader implements ItemReader<MemberEntity> {
private final MemberRepository memberRepository;
private List<MemberEntity> membersToDelete;
public MemberItemReader(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Override
public MemberEntity read() {
if (membersToDelete == null || membersToDelete.isEmpty()) {
// 삭제 대상 회원 목록을 DB에서 읽어옴
membersToDelete = memberRepository.findAllByIsDeletedTrue();
}
// 목록이 비어있으면 null을 반환하여 읽기 종료
return membersToDelete.isEmpty() ? null : membersToDelete.remove(0);
}다음은 ItemProcessor를 구현한 MemberItemProcessor이다. 회원의 마지막 접속 시간을 확인하고, 7일 이상 접속하지 않은 회원만 다음 단계로 넘기도록 처리하는 역할을 한다
@Component
public class MemberItemProcessor implements ItemProcessor<MemberEntity, MemberEntity> {
@Override
public MemberEntity process(MemberEntity memberEntity) throws Exception {
LocalDateTime lastConnectionAt = memberEntity.getLastConnectionAt();
if (lastConnectionAt != null && ChronoUnit.DAYS.between(lastConnectionAt, LocalDateTime.now()) > 7) {
return memberEntity; // 삭제 대상으로 처리
}
return null; // 처리할 필요 없는 경우 null 리턴
}
}ItemProcessor<T,R> 은 Spring Batch의 핵심 인터페이스 중 하나로, 데이터를 처리하는 역할을 담당한다.
- T는 입력 타입으로 MemberEntity 객체가 입력으로 들어온다
- R은 출력 타입으로 처리된 후 반환되는 타입이다. 여기서는 다시
MemberEntity객체를 반환한다. 만약 처리가 필요하지 않은면null을 반환해서 해당 데이터를 무시할 수 있다
그 후 마지막 처리 작업인 MemberItemWriter 코드이다.
@Component
public class MemberItemWriter implements ItemWriter<MemberEntity> {
private final MemberRepository memberRepository;
public MemberItemWriter(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Override
public void write(Chunk<? extends MemberEntity> members) throws Exception {
for (MemberEntity member : members) {
if (member != null) {
memberRepository.delete(member);
}
}
}
}위의 클래스는 회원 삭제 작업을 수행하는 Writer 역할을 한다.
ItemWriter 인터페이스를 구현해서 처리할 회원 데이터를 삭제하는 로직을 정의하고, writer 메서드는 Chunk 단위로 데이터를 받아오며, 여기서 memberRepository.delete()를 통해서 회원 정보를 삭제한다.
여기서 Chunk 단위란 Spring Batch에서 데이터를 읽고, 처리하고, 쓰는 작업을 묶음 단위로 처리하는 방식이다. 즉 데이터를 한 번에 하나씩 처리하는 것이 아니라, 일정한 개수의 데이터 묶음(Chunk)을 만들어서 일괄적으로 처리하는 개념이다.
Spring Batch에서는 Chunk 기반 프로세싱을 통해서 대용량 데이터를 효과적으로 처리한다. 예를 들어서 1000개의 데이터를 처리한다고 할 때, 한 번에 1000개를 처리하는 것이 아니라, 10개씩 묶음으로 나누어 처리하는 방식이다.
마지막으로 현재까지 작성한 MemberItemReader -> MemberItemProcessor -> MemberItemWriter 을 지나 최종 종착역인 BatchScheduler(스케줄러) 코드이다.!
@Configuration
@EnableScheduling
@Slf4j
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final Job deleteMemberJob;
public BatchScheduler(JobLauncher jobLauncher, Job deleteMemberJob) {
this.jobLauncher = jobLauncher;
this.deleteMemberJob = deleteMemberJob;
}
@Scheduled(cron = "0 0 0 * * ?")
public void runDeleteMemberJob() {
log.info("Deleting members");
try {
jobLauncher.run(deleteMemberJob, new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters());
} catch (Exception e) {
e.printStackTrace();
}
}
}이 클래스는 스케줄러로 배치 작업을 일정한 주기로 실행한다.
JobLauncher는 Spring Batch에서 배치 작업을 실행하는 역할을 담당하는 인터페이스로, JobLauncher는 정의된 배치 작업(Job)을 실행하고, 실행 시 JobParameters를 전달할 수 있다.\
또한 Job deleteMemberJob은 회원 삭제 작업을 정의한 Spring Batch의 Job이다. 이 작업이 스케줄러에 의해 매일 자정에 실행되며 삭제 작업을 수행한다.
여기서 JobParametersBuilder를 사용해서 현재 시간을 파라미터로 전달한다. 파라미터로 전달하는 이유는 매번 배치 작업을 실행할 때 새로운 실행 인스턴스로 관리하기 위함이다.
Spring Batch는 동일한 파라미터로는 새로운 인스턴스를 실행하지 않는다
위의 이유를 더 풀어서 설명하면 Spring Batch는 배치 작업이 중복해서 실행되는 것을 방지하기 위한 메커니즘을 가지고 있다. 예를 들어, 동일한 데이터에 대해 배치 작업을 중복으로 실행하는 경우, 같은 데이터를 여러 번 처리하게 되면 데이터 오류가 발생할 수 있기 떄문이다. 이를 방지하기 위해 Spring Batch는 동일한 JobParameters로 동일한 배치 작업을 여러 번 실행 하지 않도록 설계되었다.
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Bean
public Job deleteMemberJob(Step deleteMemberStep, JobRepository jobRepository) {
return new JobBuilder("deleteMemberJob", jobRepository)
.start(deleteMemberStep)
.build();
}
@Bean
public Step deleteMemberStep(ItemReader<MemberEntity> reader, ItemProcessor<MemberEntity, MemberEntity> processor,
ItemWriter<MemberEntity> writer, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("deleteMemberStep", jobRepository)
.<MemberEntity, MemberEntity>chunk(10, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
}지금 여기서 config 파일을 다시 확인해보면 deleteMemberStep에서 reader, processor, writer를 builder 하는 것으로 보아 reader -> processor -> writer 로 데이터를 전송하는 것을 build를 함으로써 해주는 것으로 예상하고 있고,
여러개의 step을 jopRepository에 넣어서 .start(deleteMemberStep)으로 자동화 시키는 것이다.
이렇게 배치를 사용해봤는데 뭔가 스케줄러보다 체계적인 것 같고 동시에 여러 개의 스케줄러를 사용할 수 있을 것 같다. 좋은 시간이었다.

스프링 배치와 스케줄러를 잘 정리해주셨네요!! 저도 도전해봐야겠어요~!