구조적, 집합적, 선언적 질의 언어
SQL은 Structured Query Language의 줄임말이다. 말 그래도 구조적 질의 언어다.
원하는 결과집합을 구조적,집합적으로 선언하지만 그 결과 집합을 만드는 과정은 절차적일 수 밖에 없다. 즉 프로시저가 필요한데 그런 프로시저를 만들어내는 DBMS내부엔진이 바로 SQL옵티마이저이다.
SQL처리과정
Oracle 기준으로 자세히 표현하면 아래 그림과 같다.
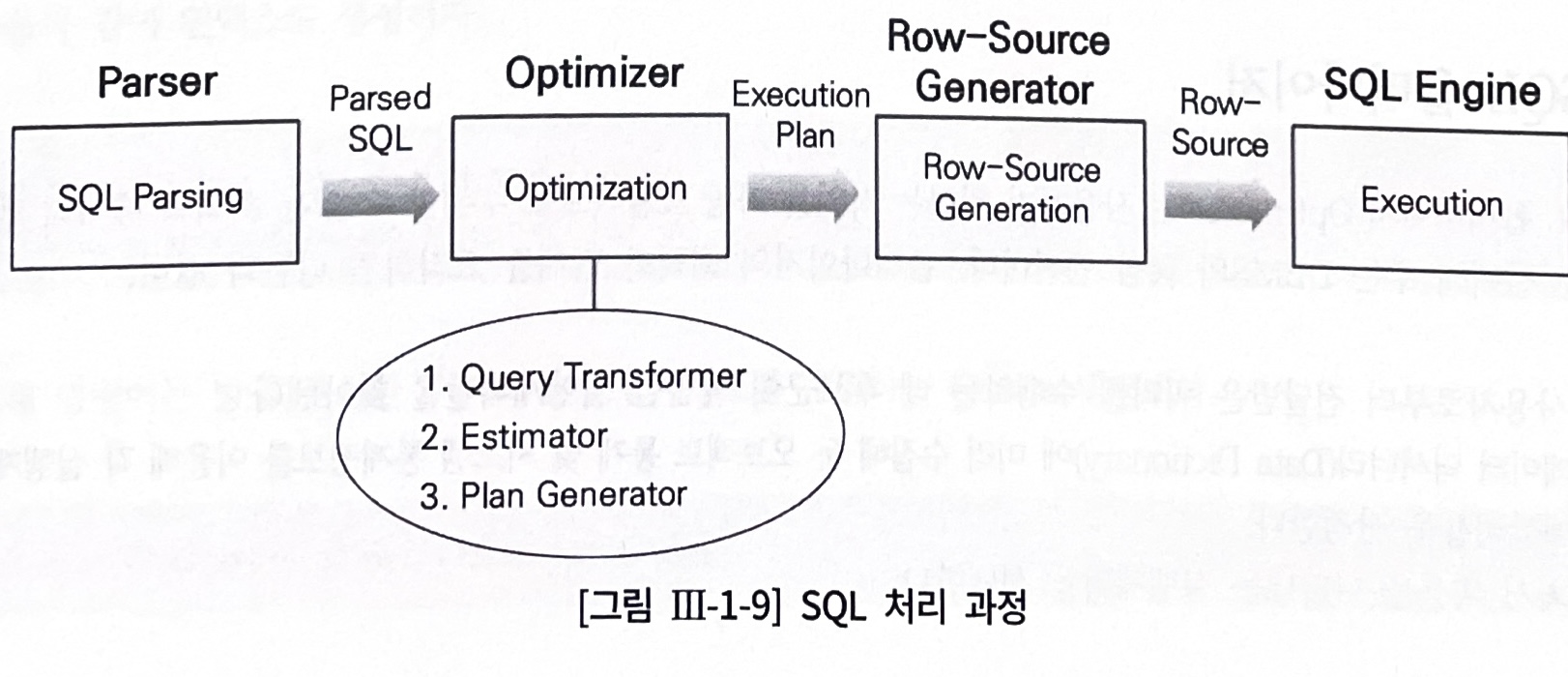
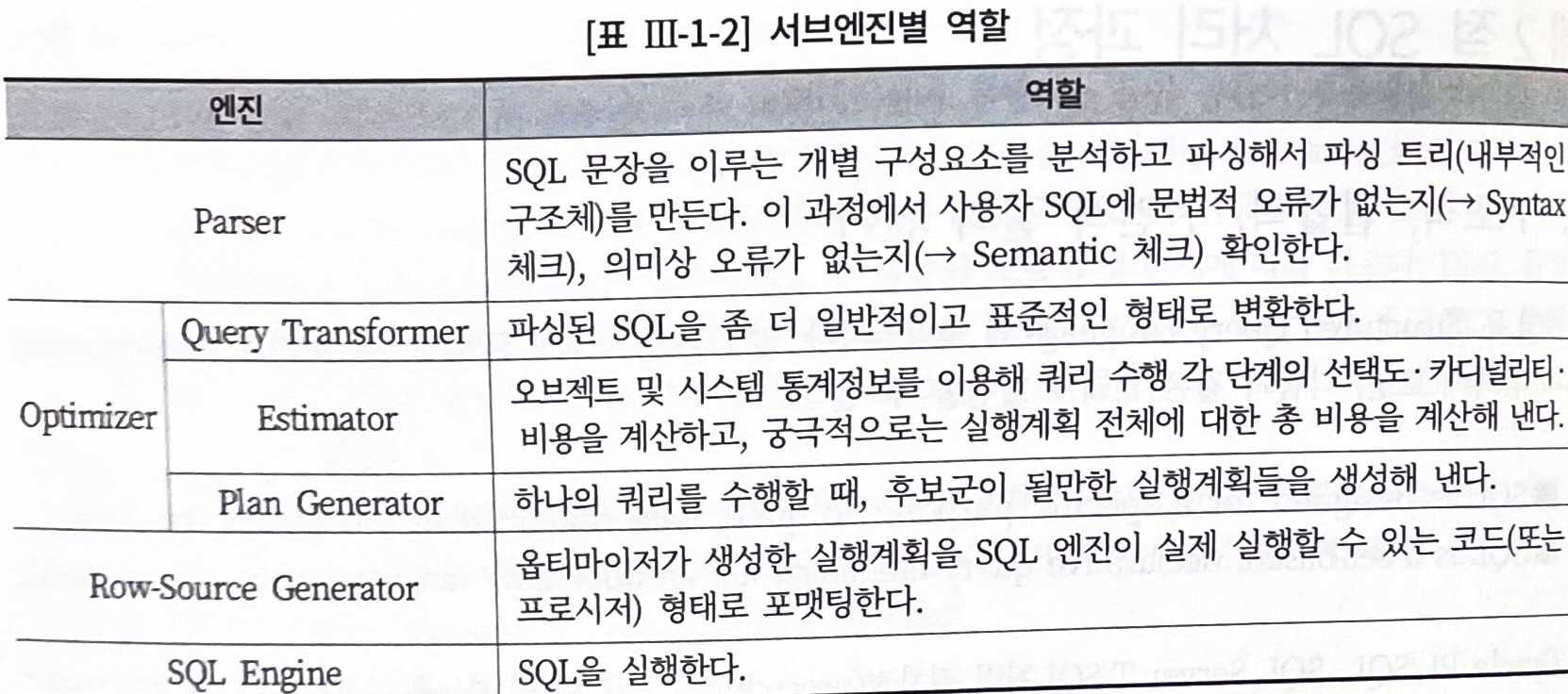
아래의 표는 위의 사진에서 표현된 각 서브엔진의 역할을 요약한 것이다.
쿼리 최적화 과정을 다음과 같이 설명하고 있다. Parser와 Optimizer역할에 해당하는 내용임을 알 수 있다.
- 쿼리를 내부 표현방식으로 변환
- 표준적인 형태로 변환
- 후보군이 될 만한 프로시저를 선택
- 실행계획을 생성하고 가장 비용이 적은 것을 선택
SQL 옵티마이저
: SQL 옵티마이저는 사용자가 원하는 작업을 가장 효율적이고 수행할 수 있는 최적의 데이터 액세스경로를 선택해 주는 DBMS의 핵심엔진이다.
- 옵티마이저의 최적화 단계
- 사용자로부터 전달받은 쿼리를 수행하는 데 후보군이 될만한 실행계획들을 찾아낸다.
- 데이터 딕셔너리에 미리 수집해 둔 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
- 최저 비용을 나타내는 실행계획을 선택한다.
실행계획과 비용
비용은 쿼리를 수행하는 동안 발생할 것으로 예상되는 I/O 횟수또는 예상소요시간을 표현한 값이다. 실행경로를 선택하기 위해 옵티마이저가 여러 통계정보를 활용해서 계산해 낸 값이다. 실측치가 아니므로 실제 수행할 때 발생하는 I/O 또는 시간과 많은 차이가 날 수 있다.
옵티마이저 힌트
: 통계정보가 정확하지 않거나 기타 다른 이유로 옵티마이저가 잘못된 판단을 할 수 있다. 그럴 때 프로그램이나 데이터 특성 정보를 정확히 알고 있는 개발자가 직접 인덱스를 지정하거나 조인 방식을 변경함으로써 더 좋은 실행계획으로 유도하는 메커니즘이 필요한데 옵티마이저 힌트가 바로 그것이다.
1. Oracle 힌트
- 힌트 기술방법
SELECT /* LEADING(E2 E1) USE_NM(E1) INDEX(E1 EMP_EMP_ID_OK
USE_MERGE(J) FULL(J)*/
E1.FIRST_NAME, E1.LAST_NAME, J.JOB_ID, SUM(E2.SALARY) TOTAL_SAL
FROM EMPLOYEES E1, EMPLOYEES E2, JOB_HISTORY J
WHERE E1.EMPLOYEE_ID = E2.MANAGER_ID
AND E1.EMPLOYEE_ID = J.EMPLOYEE_ID
AND E1.HIRE_DATE = J.START_DATE
GROUP BY E1.FIRST_NAME, E1.LAST_NAME, J.JOB_ID
ORDER BY TOTAL_SAL;Index 힌트에는 인덱스명 대신 다음과 같이 컬럼명을 지정할 수 있다.
SELECT /*LEADING(E2 E1) USE_NM(E1) INDEX(E1(EMPLOYEE_ID))*/- 힌트가 무시되는 경우
다음과 같은 경우에 Oracle 옵티마이저는 힌트를 무시하고 최적화를 진행한다.- 문법적으로 안 맞게 힌트를 기술
- 잘못된 참조 사용
- 논리적으로 불가능한 액세스 경로
- 의미적으로 안 맞게 힌트를 기술
- 힌트 종류
Oracle은 공식적으로 다음과 같이 많은 힌트를 제공한다. 비공식 힌트까지 합치면 350여개에 이른다.

