- 정규표현식(regular expression)은 문자열의 규칙을 표현하는 검색패턴으로 주로 문자열 검색과 치환에 사용된다.
기본 문법
1. POSIX 연산자
- 정규표현식의 기본 연산자이다.

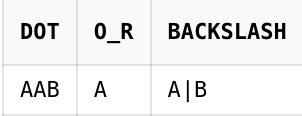
입력✏️
SELECT REGEXP_SUBSTR('AAB', 'A.B') AS DOT a
,REGEXP_SUBSTR('A', 'A|B') AS O_R
,REGEXP_SUBSTR('A|B', 'A\|B')AS BACKSLASH
FROM DUAL;출력💻
앵커(anchor)는 검색패턴의 시작과 끝을 지정한다.
- ^ (carrot) : 문자열의 시작
- $ (dollar): 문자열의 끝
입력✏️
SELECT REGEXP_SUBSTR('AB' || CHR(10) || 'CD', '^.',1,1)AS C1
,REGEXP_SUBSTR('AB' || CHR(10) || 'CD', '^.',1,2)AS C2
,REGEXP_SUBSTR('AB' || CHR(10) || 'CD', '.$',1,1)AS C3
,REGEXP_SUBSTR('AB' || CHR(10) || 'CD', '.$',1,2)AS C4
FROM DUAL;출력💻

수량사(quantifier)는 선행표현식의 일치횟수를 제공한다. 패턴을 최대로 일치시키는 탐욕적 방식으로 동작한다.

입력✏️
SELECT REGEXP_SUBSTR('AC','AB?C')AS C1 // 0,1회 일치
,REGEXP_SUBSTR('ABC','AB?C')AS C2 // 0,1회 일치
,REGEXP_SUBSTR('AC','AB*C')AS C3 //0회, 그 이상의 횟수로 일치
,REGEXP_SUBSTR('ABC','AB+C')AS C4 //1회, 그 이상의 횟수로 일치
FROM DUAL;출력💻

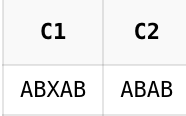
- 역참조를 사용하면 일치한 서브표현식을 다시 참조할 수 있다. 반복되는 패턴을 검색하거나 서브표현식의 위치를 변경하는 용도로 사용할 수 있다.

입력✏️
SELECT REGEXP_SUBSTR('ABXAB','(AB|CD)X\1')AS C1
,REGEXP_SUBSTR('ABAB','(.*)\1+')AS C2 // 동일한 문자열이 1회이상 반복되는 패턴
FROM DUAL;출력💻
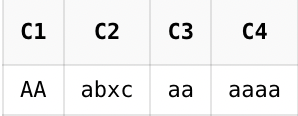
- 문자리스트는 문자를 대괄호로 묶은 표현식이다. 문자리스트중 한문자만 일치하면 패턴이 일치한 것으로 처리된다.


입력✏️
SELECT REGEXP_SUBSTR('AB11,','[[:digit:]]')AS C1 //숫자
,REGEXP_SUBSTR('AB11,','[[:alpha:]]')AS C2 //영문자
,REGEXP_SUBSTR('AB11,','[[:alnum:]]')AS C3 //영문자와 숫자
,REGEXP_SUBSTR('AB11,','[[:punct:]]')AS C4 // 구두점기호
FROM DUAL;출력💻
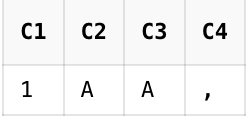
2. PERL 정규표현식 연산자


입력✏️
SELECT REGEXP_SUBSTR('AAAA','A??AA')AS C1
,REGEXP_SUBSTR('abxcxd','\w+?x\w')AS C2
,REGEXP_SUBSTR('aaaa','a{2}?')AS C3
,REGEXP_SUBSTR('aaaa ','a{2,}')AS C4
FROM DUAL;
출력💻
정규표현식 조건과 함수
1. REGEXP_LIKE 조건
REGEXP_LIKE 조건은 source_char가 패턴과 일치하면 true를 일치하지 않으면 false를 반환한다.
REGEXP_LIKE(source_char, pattern [, match_param])- source_char는 검색문자열을 지정한다.
- pattern은 검색 패턴을 지정한다.
- match_param은 일치 옵션을 지정한다.
2. REGEXP_REPLACE 함수
source_char에서 일치한 패턴을 replace_string으로 변경한 문자 값을 반환한다.
REGEXP_REPLACE(source_char, pattern[, replace_string[, position [, occurrence [, match_param]]]])- replace_string은 변경 문자열을 지정한다.
- position은 검색 시작 위치를 지정한다. (default값 : 1)
- occurrence는 패턴 일치 횟수를 지정한다. (default값 : 1)
3. REGEXP_SUBSTR 함수
: REGEXP_SUBSTR 함수는 source_char에서 일치한 pattern을 반환한다.
REGEXP_SUBSTR(source_char, pattern, [, position[, occurrence [, match_param [, subexpr]]]])- subexpr은 서브표현식을 지정한다 (0은 전체패턴, 1이상은 서브표현식, 기본값은 0)
4. REGEXP_INSTR 함수
: REGEXP_INSTR 함수는 source_char에서 일치한 pattern의 시작 위치를 정수로 반환한다.
REGEXP_INSTR(source_char, pattern [,position[, occurrence[, return_opt [, match_param [,subexpr]]]]])- return_opt은 반환 옵션을 지정한다ㅏ(0은 시작위치, 1은 다음위치, 기본값은 0이다)
5. REGEXP_COUNT 함수
: REGEXP-COUNT 함수는 source_char에서 일치한 pattern의 횟수를 반환한다.
REGEXP_COUNT(source_char, pattern [, position [, match_param]])입력✏️
SELECT REGEXP_COUNT('123412341234', '123',1)
FROM DUAL;출력💻

참고자료 : SQL전문가가이드
