Kafka 1과 이어집니다.
카프카 저장 구조
카프카는 큐와 비슷한 구조로 먼저 들어온 데이터를 파티션에 저장한다.
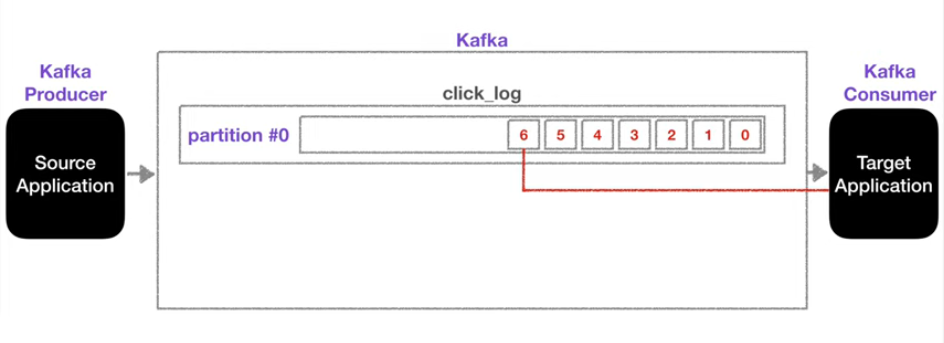
Target Application이 파티션에 들어온 데이터를 순차적으로 consume 하게 되는데, consume을 한다고해서 파티션에 있는 데이터는 없어지지않는다. (파티션 내부 데이터의 삭제 시점은 아래에서 다룬다.)
위와 같은 특성덕분에 두번째 consumer인 TargetApplication2가 그대로 파티션의 데이터를 다시 0번부터 consume 할 수 있게 된다.
동작을 수행하기 위해서는 컨슈머 그룹이 다르고, auto.offset.reset 설정이 earliest로 설정되어야 한다.
만약 파티션이 두 곳이라면 ?
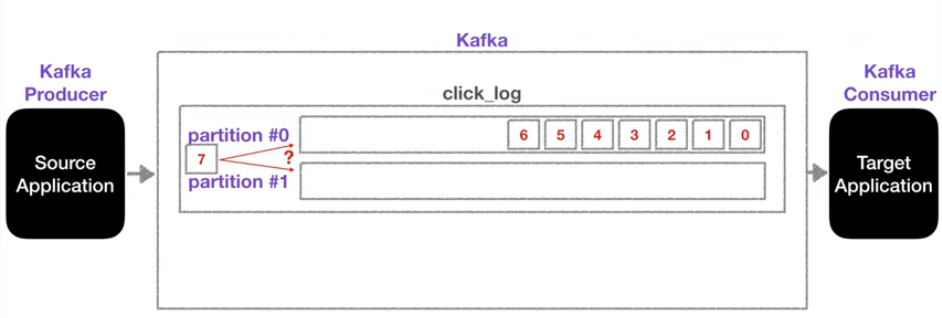
Producer와 Consumer는 하나씩이지만 한 토픽에 파티션을 두 개 이상이 될 수도 있다.
이때, 그림과 같이 7번 순서를 가진 데이터가 파티션에 들어온다면 어떤 파티션에 담기게 될까?
프로듀서가 데이터를 저장하는 과정에서 key 값을 사용해 파티션을 지정할 수 있다.
default, 즉 key 값이 null 인 경우 라운드로빈 방식으로 파티션이 할당된다.
key 값을 지정하는 경우 key에 맞는 파티션이 할당 된다.
파티션은 계속 만들어도 되는가?
앞서 파티션이 하나에서 두개가 된다면? 을 가정해봤다.
그렇다면 파티션을 계속 늘릴 수 있나?

정답은 yes 이다.
파티션을 늘리는 것처럼 consumer도 늘릴 수 있는데 이렇게 되면 consumer가 소비하는 데이터들을 분산시킬 수 있어 장점이 될 수 있다.
하지만 파티션의 개수를 증가시킬때 고려할 사항이 있다.
파티션은 늘릴 수 있지만 줄일 수는 없기때문에 파티션 증가는 신중하게 고민하고 수행해야한다.
파티션 내부 데이터의 삭제 시점
파티션 내부에 있는 데이터를 consumer가 소비한다고 바로 없어지지 않는다고 설명했었다.
그러면 데이터는 언제 삭제가 될까?
log.retention.ms, log.retention.byte 라는 메소드들로 각각 최대 record의 보존시간과 크기를 지정해 삭제 시점을 설정할 수 있다.
공식문서에서 .ms, .byte 이외의 다양한 시간설정을 확인 할 수 있다.

이 설정을 잘 활용하면 만들고자하는 어플리케이션의 규모에 따라 유연하게 사용할 수 있을 것 같다.
Replication
카프카의 장점 중 Kafka는 데이터를 여러 브로커에 복제해서 저장하므로 신뢰성이 높다. 라고 설명한 적이 있다.
Replication을 설명하며 다시 살펴본다.
Replica라는 말을 들어본 사람도 있고 처음 들어보는 사람도 있을 것이다.
나는 스포츠 유니폼을 통해 Replica라는 말을 들어봤는데 정품이 아닌 디자인을 모방한 유니폼을 뜻했다.

설명할 Replication도 복제라는 의미를 가지고 있다.
데이터를 여러 브로커에 복제해서 저장한다라고 할때 그 복제이다.
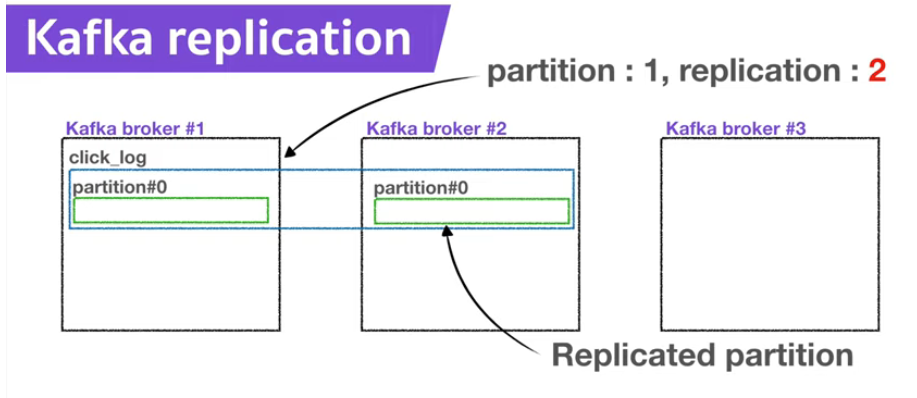
Replication은 복제된 파티션의 개수를 의미한다.
정확히는 원본 + 복제본의 개수이다.
원본 - Leader partition
복제본 - Follower partition
Leader & Follower = ISR(In Sync Replica)
이 또한 무한히 복제되는 것은 아니며 개수의 제한이 있고 이 개수는 브로커의 개수를 넘을 수 없다.
Replication 사용의 이유
그럼 이 Replication (짝퉁) 은 왜 사용하는걸까?


카프카의 장단점을 설명했던 앞선 포스트에 답이 나와있다.
많은 데이터들의 고가용성을 위함인데, 만일 LeaderPartition이 있던 브로커가 알 수 없는 이유로 사용 불능이 된다면 Leader의 복제본인 Follower를 Leader로써 사용할 수 있게되어 데이터 손실에 강하다.
ack
네트워크 수업을 들었을때, 배웠던 개념과 유사한 내용이 존재한다.
replication은 ack 즉, 데이터 수신확인을 할 수 있는 설정이 있다.
ack = 0
ack = 0이라고 설정하게되면 데이터를 잘 전달받았다는 응답을 받지않기때문에 빠르지만 가용성을 높게 유지할 수 없다.
ack = 1
ack = 1 설정을 통해 Producer가 데이터를 Leader Partition에게 전송하고 잘 전달받았다는 응답을 다시 Producer가 받을 수 있다. (이 설정의 경우 Leader Partion이 다른 Follower 들에게 성공적으로 복제했는지에 대한 여부는 알 수 없다.)
ack = all
ack = 1에서 확인 할 수 없던 복제 여부는 이 설정을 통해 확인 할 수 있다.
ack가 0또는 1 인 경우 Follower들에 복제 여부를 확인할 수 없으나 all 설정의 경우 복제 여부까지 확인 할 수 있어 데이터 유실을 방지 할 수 있다. (확인 요소가 많아 비교적 많은 시간이 소요된다.)
Lag
파티션이 하나밖에 없는 토픽에 Producer가 데이터를 지속해서 넣는다고 가정하자.
들어간 데이터를 Consumer도 계속해서 소비할 것이다.
파티션에 데이터가 적제될때, 데이터들은 offset이라는 인덱스 값을 갖게 된다.
그런데 만약 Consumer의 데이터 소비 속도가 Producer의 데이터를 넣는 속도보다 느리다면 어떻게 될까?
당연히 파티션에 데이터가 쌓이게 될 것이고, Producer가 넣은 데이터의 offset과 Consumer가 마지막으로 소비한 offset의 차이가 점차 벌어질 것이다.
이 차이가 바로 Consumer Lag이고, 이 Lag을 통해서 파티션의 상태를 모니터링 해볼 수 있다.
당연히, 한 토픽에 두개의 파티션이 존재하는 경우 두개의 Consumer를 사용할 수 있을테고, consume하는 속도의 차이가 존재할 수 있으므로 Lag 또한 두 개 이상 존재 할 수 있다.
두 개 이상의 Lag에서 가장 높은 숫자를 가지는 Lag을 records-lag-max라고 한다.
출처
모든 Kafka 관련 이미지와 학습 내용의 출처는 카프카 for beginners 에 있습니다.
