
Clean Architecture 구조를 적용하면서 모든 계층은 각각의 모델이 존재해야하는지에 대한 의문이 생겼고, 이 의문을 해결한 과정을 담은 글입니다.
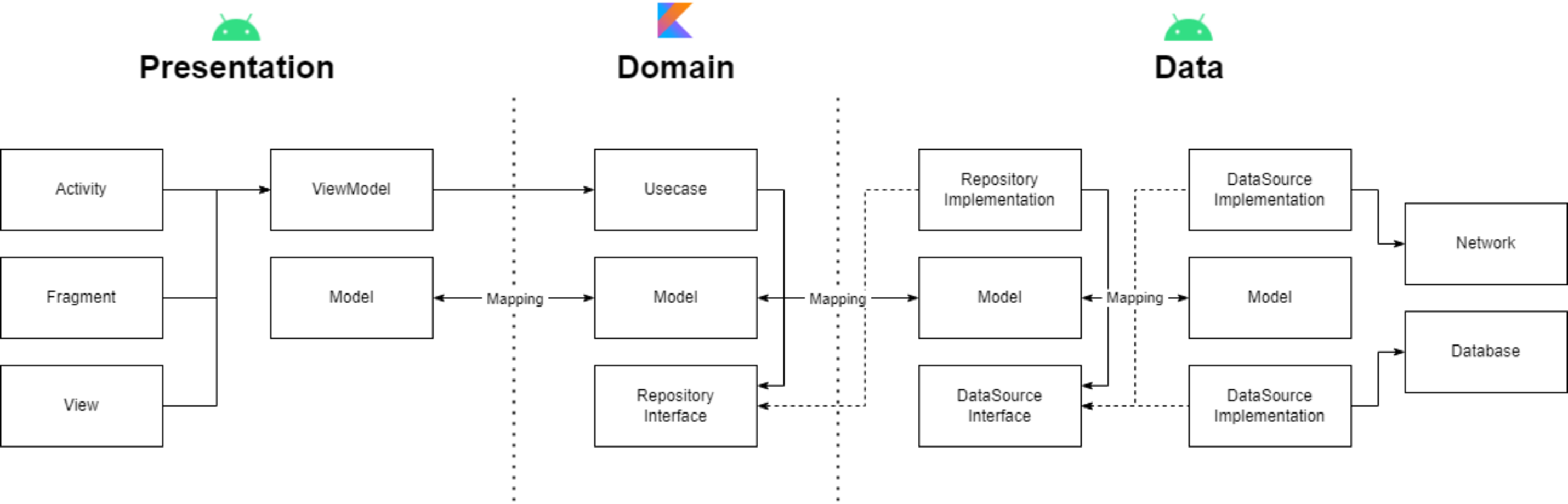
설계한 전체적인 구조는 다음과 같습니다. 총 3개의 계층으로 분리하였고 presentation, domain, data 계층으로 분리하였습니다. presentation은 뷰와 뷰모델을 담당하고 있고, domain 에서는 각 기능에 대한 usecase가 구현되어 있습니다. data 계층에서는 local이나 remote에 직접적으로 접근하는 datasource가 존재하고 repository에서 데이터를 가공하여 넘겨줍니다. presentation과 data 계층은 안드로이드 모듈로 만들었습니다. 아무래도, Room 라이브러리가 안드로이드 의존성을 가지고 있기 때문에 data계층을 안드로이드 모듈로 만들 수 밖에 없었습니다. 도메인 계층은 어떠한 플랫폼에 종속되어 있지 않은 순수 Entity 계층입니다. 그렇기 때문에 domain 계층을 순수 코틀린 라이브러리 모듈로 생성하였습니다. 그리고, 제가 설계한 구조에서는 각 계층마다 모델이 존재합니다. 심지어 data 계층에서는 두 개의 모델이 존재하며, 각 계층마다 모델이 있어야 하는 이유에 대해서 고민해 보았습니다.
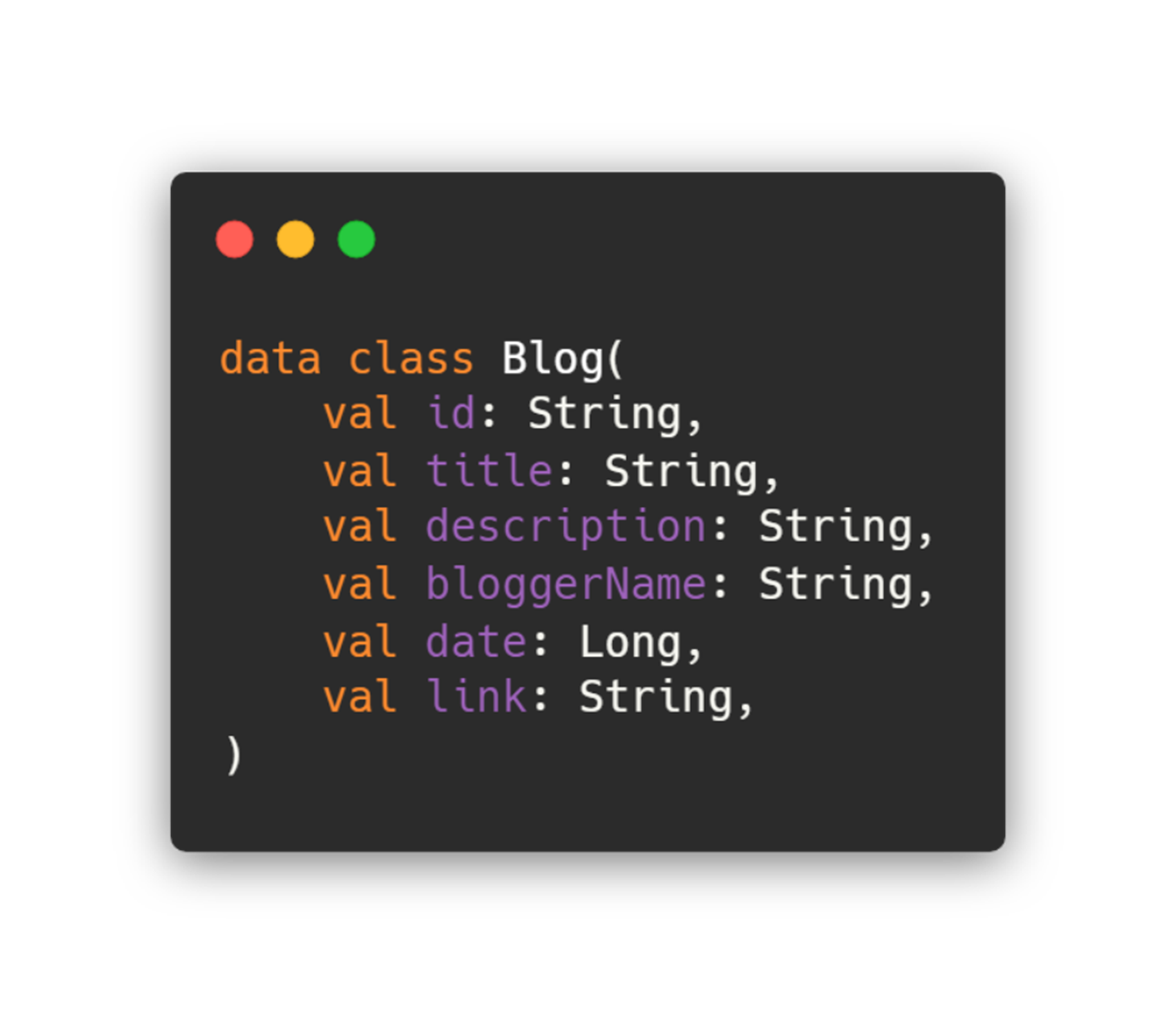
먼저, domain 계층의 모델과 data 계층의 모델을 분리해야하는 이유는 쉽게 찾을 수 있었습니다. 그림은 블로그 속성들을 담을 수 있는 도메인 계층의 데이터 클래스입니다. 도메인 계층의 특성에 맞게 어떠한 라이브러리에도 의존되어 있지 않는 순수 데이터 클래스입니다. 해당 데이터 클래스를 data 계층에서는 그대로 사용할 수 없습니다. 그 이유는
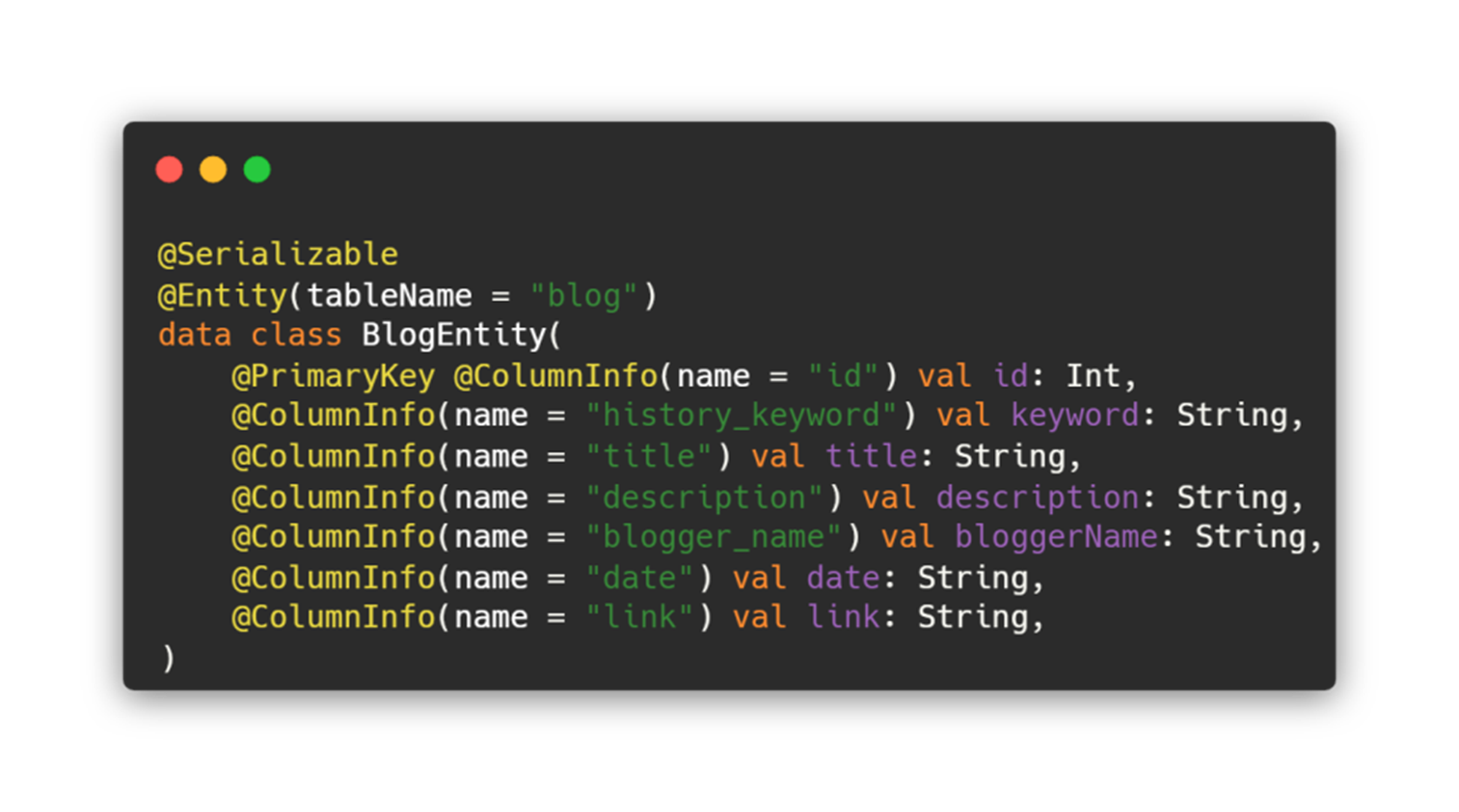
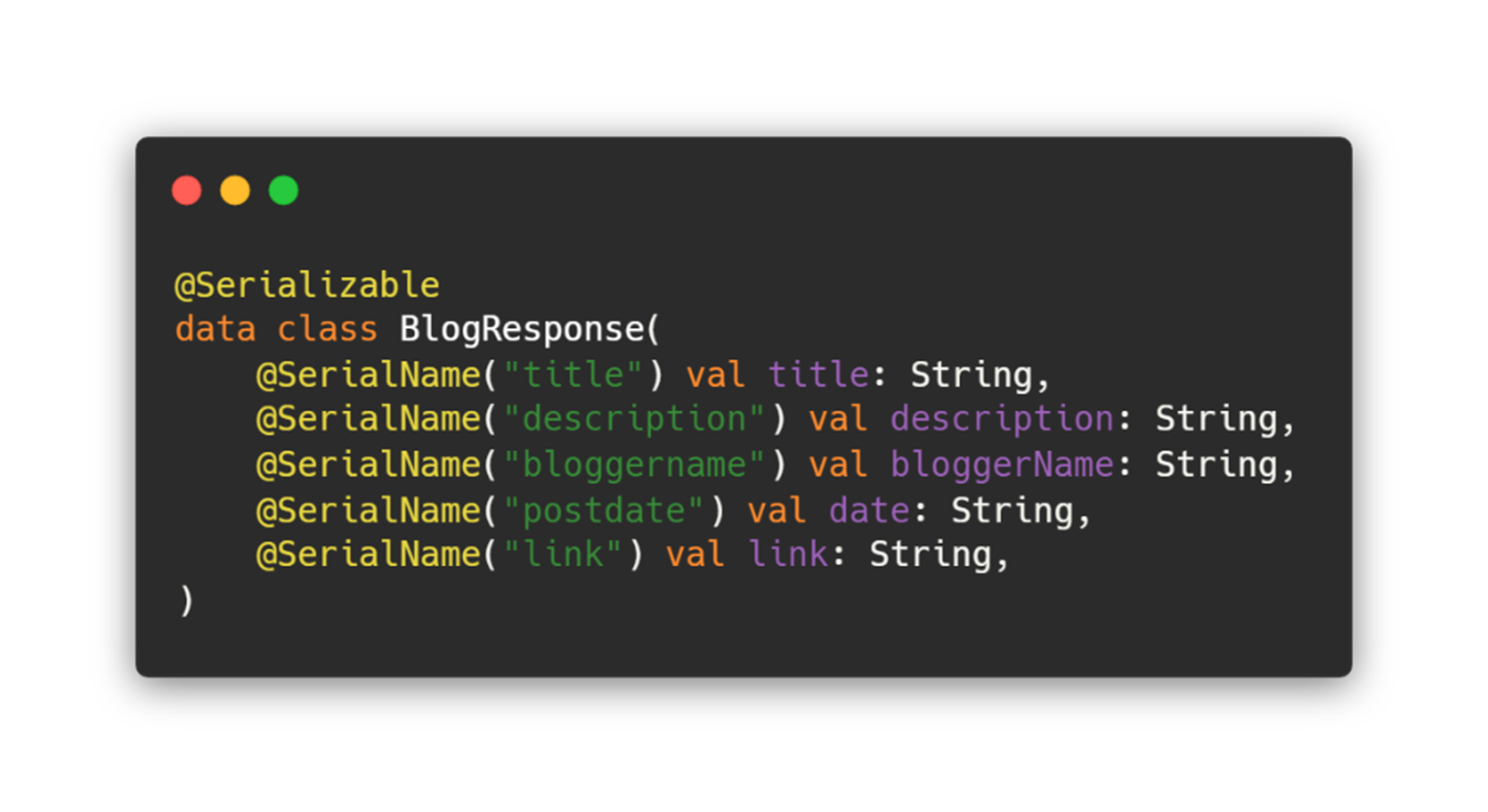
이와 같이 local에서 가져온 데이터와 remote에서 가져온 데이터의 형태가 다르고 각각 다른 라이브러리에 의존된 형태를 사용하기 때문입니다. 그렇기에 도메인과 데이터 계층의 모델 분리는 필수적이라 생각했습니다.
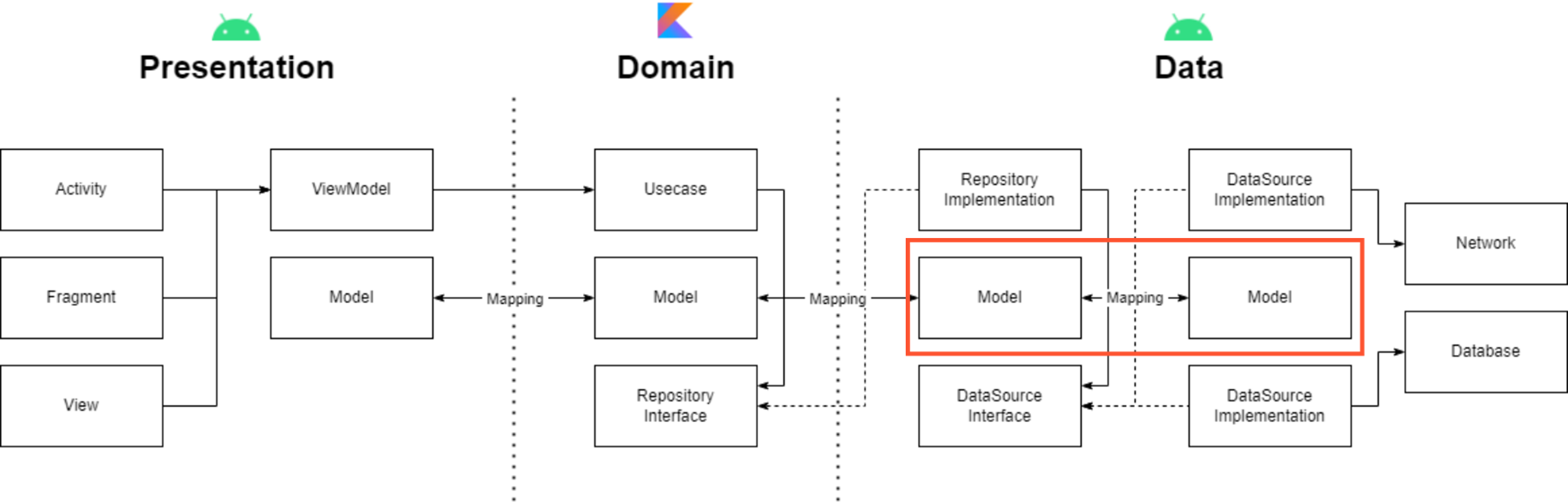
그런데, 데이터 계층의 모델이 두 개가 존재합니다. 왜 데이터 계층을 두 모델로 분리하였는지 설명드리겠습니다.
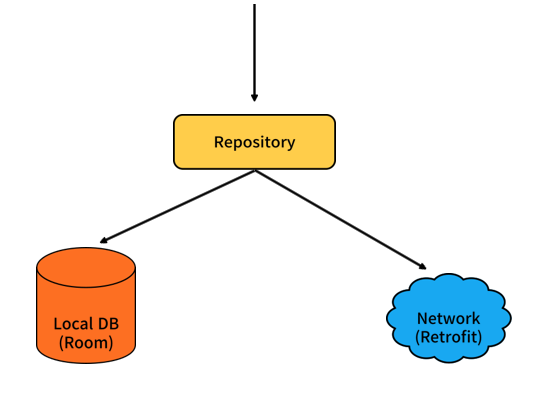
먼저 repository의 역할을 고민해보았습니다. repository 패턴을 활용하게 되면 repository는 로컬의 데이터와 remote 데이터를 가공하여 도메인 계층으로 넘겨주기 때문에 해당 데이터가 로컬에서 가져온 데이터인지 네트워크 요청으로 가져온 데이터인지 알 필요가 없게 됩니다.

만약 똑같은 구조에서 Local DB로 사용하던 라이브러리를 Room에서 Realm으로 변경하였을 때, 기존의 구조에서는 repository가 Local DB = Room으로 알고있는 구조였고 Room 라이브러리에 종속된 애노테이션들을 사용하는 데이터를 넘기게 됩니다. 단순히 local과 remote의 데이터를 가공하여 넘겨주었던 repository가 Local DB에서 사용하는 라이브러리를 변경하는 경우 대응하기 힘들어집니다. 즉, repository는 Local과 Remote의 데이터를 가공하여 넘겨주는 역할을 하고 datasource 에서 변경된 라이브러리에 대한 작업을 수행하고 repository로 데이터를 넘겨주며 관심사를 분리하고 확장에 용이하도록 만들기 위해 이와 같이 모델을 분리하였습니다.
이렇게 분리를 하게 되니까 presentation, domain, data 계층 뿐만 아니라 data 계층을 remote, local 계층으로도 분리할 수 있겠다 라는 생각이 들었습니다.
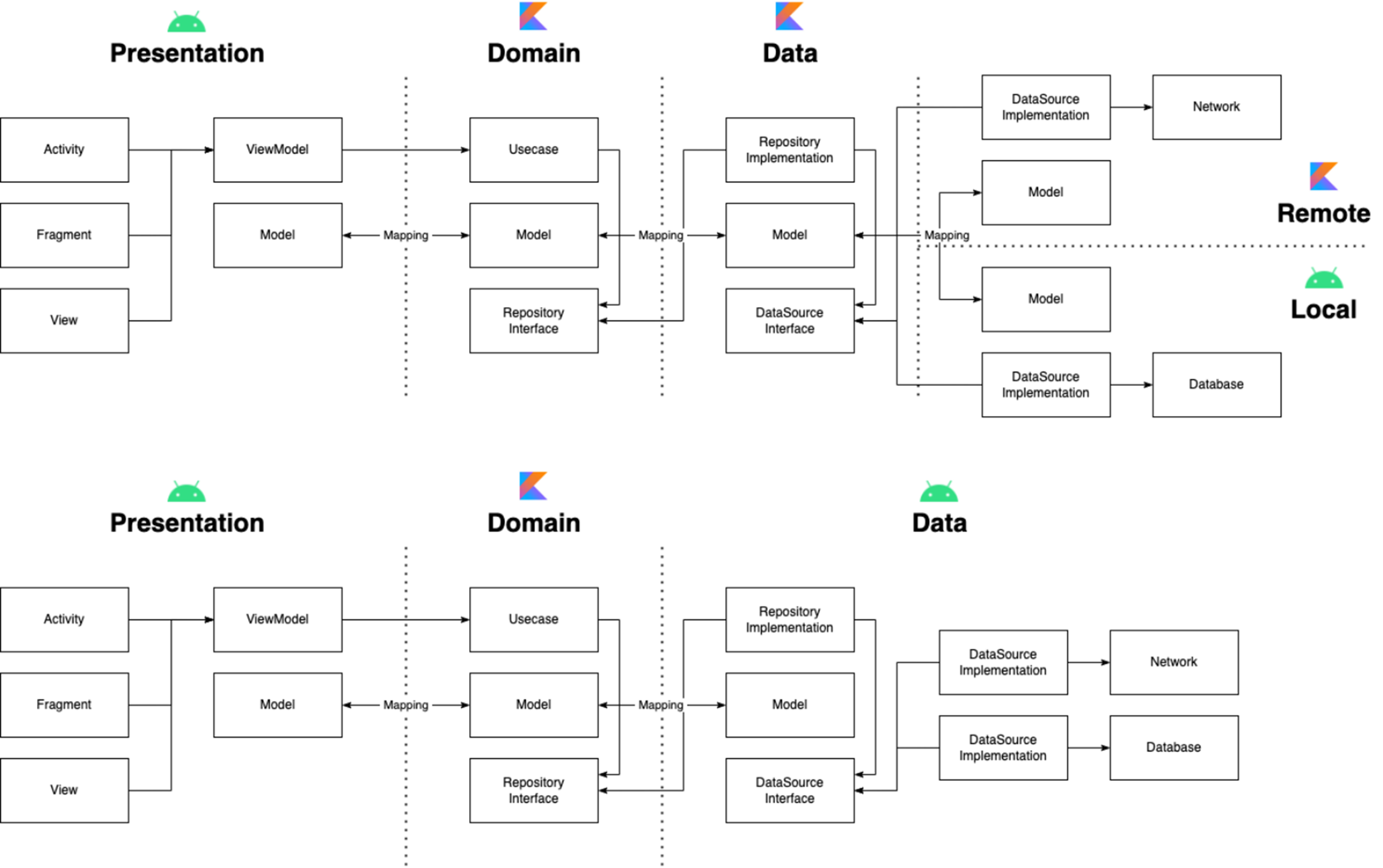
그래서 remote와 local 모듈을 분리했을 때도 설계해보았습니다. 위 구조를 보시면 remote와 local을 모듈로 분리하였습니다. 각각 모델이 존재하고 local 계층은 안드로이드 라이브러리 모듈을 사용하게 되고 data과 remote 계층은 코틀린 라이브러리 모듈을 사용하게 됩니다. 모듈로 분리하게 되면 각 모듈에 대한 테스트 코드를 쉽게 작성할 수 있고 각 모듈에 대한 관심사를 분리할 수도 있고 멀티 모듈로서의 이점도 얻을 수 있습니다.
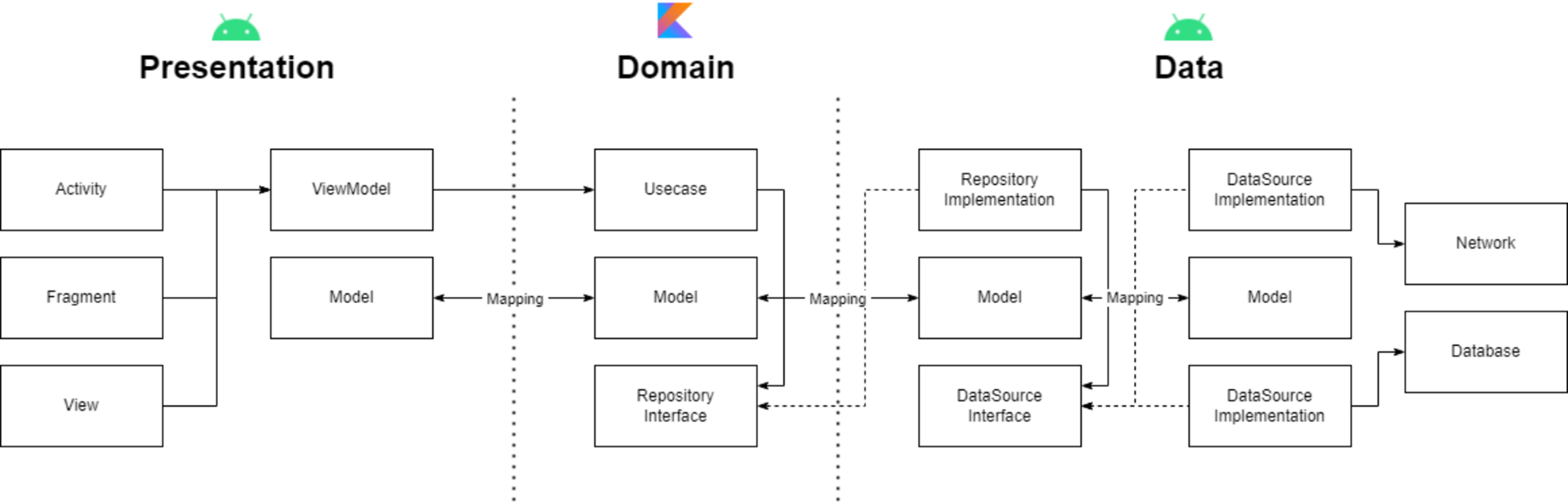
마지막으로 presentation 계층의 모델을 분리한 이유를 설명드리겠습니다. presentation 계층의 모델은 domain 계층의 모델을 그대로 가져와 사용해도 문제가 없지 않을까 생각했지만 직렬화 때문에 분리하게 되었습니다.
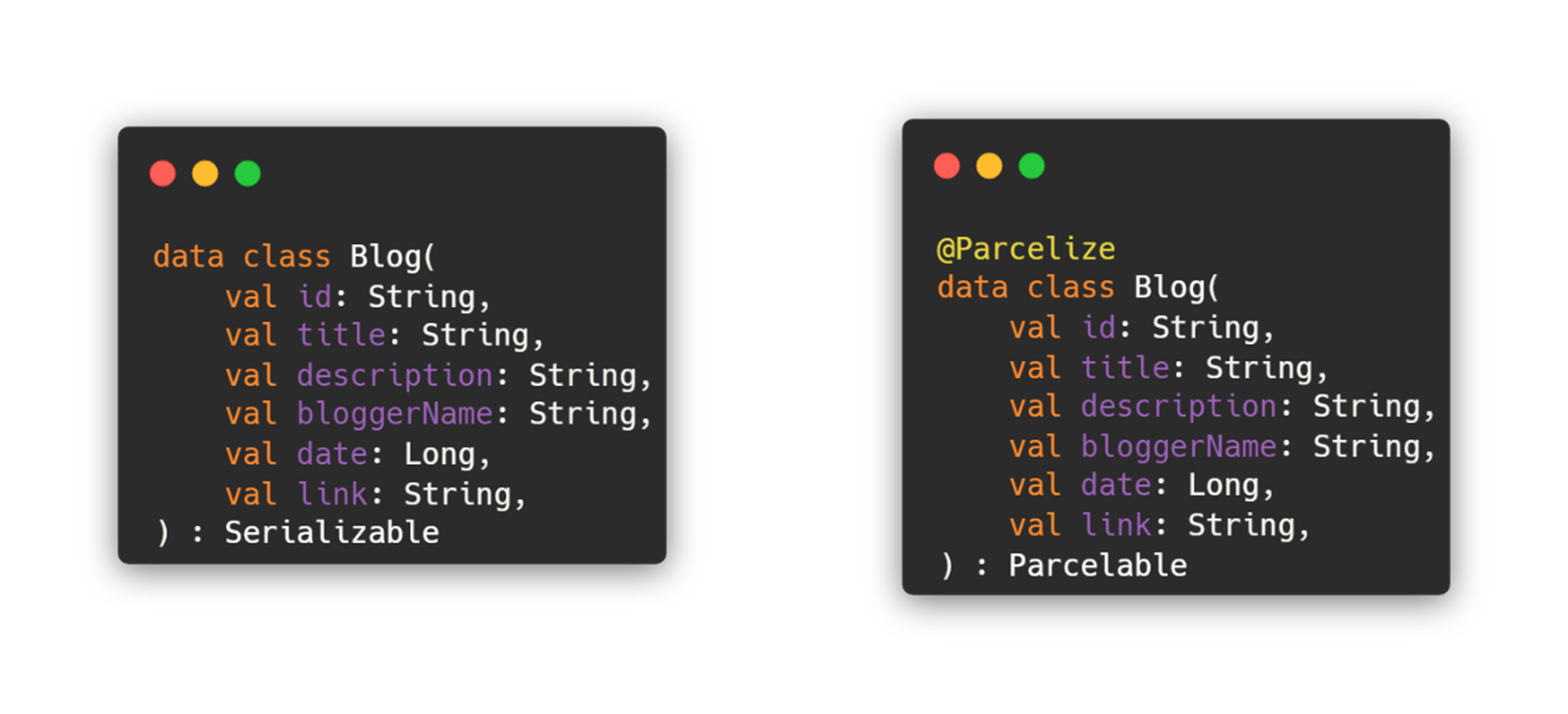
만약 객체를 전달해야하는 경우가 있을 때는, 해당 객체를 직렬화해주는 작업이 필요합니다. 그래서, Serializable이나 Parcelable을 활용하여 직렬화 작업을 할 수 있는데 이 작업은 데이터와 관련 없이 UI에서만 필요한 작업입니다. 즉, Domain 계층에서 해당 데이터가 직렬화가 필요한 데이터인지 알 필요가 없다는 것입니다. 그래서 분리하게 되었습니다.
이와 같이 각 계층에 모델들이 각각 존재한다면 계층 간에 데이터를 전달할 때마다 데이터를 변환해주는 과정이 필요합니다. 이 과정이 굉장히 번거롭다고 생각할 수도 있다고 생각하고 Domain의 모델이 직렬화 처리가 필요한 데이터 라고 정의되어도 상관없다면 presentation과 domain의 모델이 구분될 필요는 없다고 생각한다. 다른 플랫폼에서 해당 Domain을 재활용하게 된다면 문제가 발생할 수 있지만 프로젝트의 기획에 따라 적절한 방법을 선택해야 할 것 같습니다.
