
[CS/데이터베이스] 03. 데이터 무결성을 위한 정규화 전략
⚡ 한 줄 요약: 정규화는 중복 데이터를 분해하여 삽입·수정·삭제 시 발생하는 이상 현상을 방지하고 데이터의 무결성을 확보하는 필수적인 설계 과정입니다.
1. 👋 들어가며: 왜 데이터를 굳이 '분해'해야 할까요?
프론트엔드에서 복잡한 객체 데이터를 다루다 보면, 특정 값을 하나 바꿨는데 엉뚱한 곳에서 데이터 불일치가 일어나 고생한 경험이 있을겁니다.
DB에서도 마찬가지입니다.
관리가 편하자고 하나의 테이블에 모든 정보를 몰아넣으면 반드시 '이상 현상'이라는 대가를 치르게 됩니다.
-
🧐 Why:
- 데이터 중복으로 인한 모순을 제거하고, 서비스가 커져도 데이터의 신뢰도(무결성)을 유지하기 위해서입니다.
-
🎯 Goal:
- 3가지 이상 현상을 이해하고, 실무의 표준인 제3정규형(3NF)까지의 단계별 적용 방법과
성능을 위한 반정규화 전략을 익힙니다.
- 3가지 이상 현상을 이해하고, 실무의 표준인 제3정규형(3NF)까지의 단계별 적용 방법과
📂 2. 이상현상
📌 2-1. 정규화와 이상 현상
정규화는 간단히 말해 데이터를 적절히 분해시키는 과정을 의미합니다.
우리가 하나의 테이블에 너무 많은 정보를 몰아넣으려다 보면, 데이터의 중복이 발생하고 결국 데이터를 관리(삽입, 수정, 삭제)할 때 예기치 못한 부작용이 생기는데 이를 이상 현상이라고 부릅니다.
정규화를 통해 테이블을 적절히 분리하면 데이터의 일관성을 유지하고 불필요한 수정 비용을 줄일 수 있습니다.
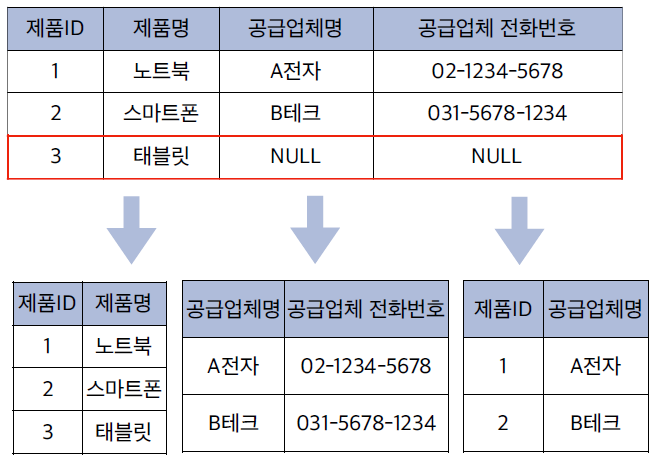
📌 2-2. 삽입 이상 (Insertion Anomaly)
삽입 이상은 데이터를 새로 추가할 때, 내가 원하지 않는 불필요한 데이터까지 강제로 입력해야 하거나, 데이터가 부족해 아예 삽입이 불가능한 경우를 말합니다.
-
예시:
- 제품 정보와 공급업체 정보를 한 테이블에 저장한다고 가정합니다.
- 만약 시스템 설계상 공급업체 정보가 필수 입력값이라면, 아직 공급업체가 결정되지 않은 '신제품'은 테이블에 등록조차 할 수 없는 문제가 발생합니다.
-
해결책:
- 제품 정보만 기록하는 테이블과 공급업체 정보만 기록하는 테이블로 분리하여 정규화하는 것이 좋습니다.
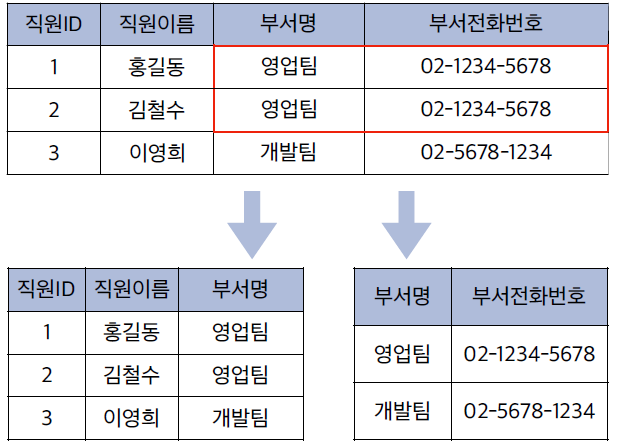
📌 2-3. 수정 이상 (Update Anomaly)
수정 이상은 데이터에 중복이 존재할 때, 특정 정보를 변경하면 바꿔야 할 곳은 여러 군데인데 일부만 수정되어 데이터 불일치가 일어나는 현상입니다.
-
예시:
- 직원 정보와 부서 정보가 한 테이블에 섞여있을 때, 특정 부서의 전화번호가 변경되었다고 가정합니다.
- 해당 부서 소속 직원이 100명이라면 100개 행의 전화번호를 모두 일일이 수정해야 합니다.
- 만약 실수로 몇 명을 누락하면 같은 부서인데 전화번호가 다르게 기록되는 모순이 생깁니다.
-
해결책:
- 역시 테이블을 적절히 분리하여 부서 정보는 단 한 번만 기록되도록 설계해야 합니다.
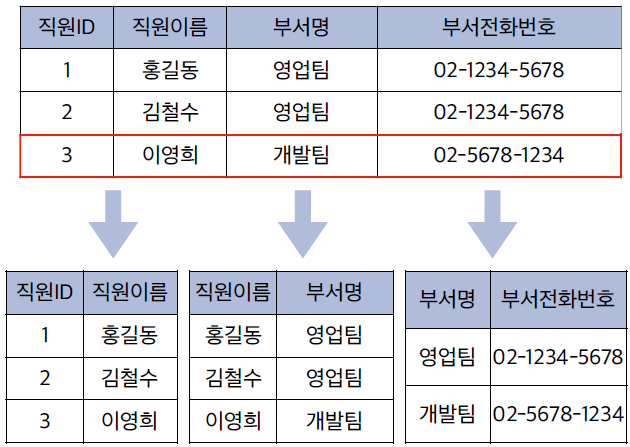
📌 2-4. 삭제 이상 (Deletion Anomaly)
삭제 이상은 하나의 데이터를 지울 때, 지워져서는 안 될 연관된 다른 정보까지 함께 사라지는 데이터 손실 문제를 의미합니다.
-
예시:
- 부서와 직원 정보가 함께 저장되어 있는 경우입니다.
- 만약 특정 부서(예: 개발팀)가 사라져서 그 부서 정보를 삭제했더니,
그 부서에 소속되어 있던 직원의 개인정보까지 몽땅 사라져 버리는 상황입니다.
-
해결책:
- 부서 테이블과 직원 테이블을 독립적으로 운영해야 합니다.
📌 2-3. 헷갈리기 쉬운 포인트 / 오해 정리
-
다대다() 관계의 처리
- 실무에서 테이블을 분리하다 보면 두 엔티티가 다대다 관계에 놓이는 경우가 많습니다.
- 이때는 테이블 구조에서 이를 직접 표현할 수 없으므로, 두 테이블 사이에 중간 테이블을 두어 , 관계로 변환하여 관리하는 것이 정석입니다.
-
정규화는 무조건 좋은가?
- 정규화를 하면 데이터 무결성은 높아지지만, 데이터를 조회할 때 여러 테이블을 합쳐야 하는
JOIN연산이 많아져 성능이 떨어질 수 있습니다. - 그래서 조회 성능이 극도로 중요한 경우, 정규화를 일부 되돌리는 반정규화(Denormalization)를 고민하기도 합니다.
- 정규화를 하면 데이터 무결성은 높아지지만, 데이터를 조회할 때 여러 테이블을 합쳐야 하는
📌 2-4. 한 줄 정리
- 정규화는 데이터 중복으로 인한 3가지 이상 현상(삽입, 수정, 삭제 이상)을 막기 위해 데이터를 적절히 분해하는 필수 설계 과정입니다.
📂 3. 정규화 (1)
📌 3-1. 정규화의 목적과 실무적 균형
정규화는 관계형 데이터베이스 설계에서 중복을 최소화하고 데이터 무결성을 유지하기 위한 필수적인 과정입니다.
데이터를 여러 테이블로 나누어 앞서 배운 이상 현상들을 방지하고, 데이터 변경 시 일관성을 유지하며 수정 비용을 줄여줍니다.
또한 저장 공간을 절약하고 수정 시 발생할 수 있는 오류를 차단하는 장점이 있습니다.
하지만 여기서 꼭 기억해야 할 실무적 포인트가 있습니다.
테이블을 많이 분해할수록, 데이터를 조회할 때 그만큼 조인(JOIN) 연산이 많아지게 됩니다.
조인이 늘어나면 결국 성능 저하를 유발할 수 있으므로,
무조건적인 분해보다는 적절한 수준에서 정규화를 진행하는 것이 중요합니다.
📌 3-2. 정규화의 단계: 어디까지 해야 할까?
정규화는 이전 단계를 만족하면서 추가적인 규칙을 적용하는 방식으로 진행됩니다.
- 제1정규형(1NF): 모든 속성이 원자값을 가짐
- 제2정규형(2NF): 부분 함수 종속 제거
- 제3정규형(3NF): 이행적 종속 제거
- BCNF: 매우 특수한 경우로, 실무에서는 거의 사용되지 않습니다.
보통 제3정규형까지만 제대로 이해하고 적용해도 실무에서 정규화를 충분히 진행할 수 있습니다.
📌 3-3. 성능을 위한 역행, 반정규화
정규화를 거친 DB에서 JOIN 연산이 너무 많아져 조회 성능이 심각하게 떨어질 때 사용하는 해결책이 바로 반정규화입니다.
-
개념:
- 성능 최적화를 위해 일부 정규화를 의도적으로 되돌리는 과정입니다.
-
핵심:
- 데이터 중복을 일부 허용하더라도 읽기 속도를 향상시키는 것이 목적입니다.
📌 3-4. 헷갈리기 쉬운 포인트 / 오해 정리
-
정규화 = 성능 저하?
- 정규화가 조회를 느리게 할 순 있어도, 데이터가 중복되어 발생하는 오류(무결성 파괴)를 막아주는 가치는 훨씬 큽니다.
- 성능은 그 다음 단계(인덱스, 캐싱, 반정규화)에서 해결할 문제입니다.
-
반정규화 = 설계 포기?
- 반정규화는 설계를 못 해서 하는 것이 아니라, 철저히 계산된 성능 최적화 기법입니다.
- 반드시 정규화가 선행된 후에 고려되어야 합니다.
📌 3-5. 한 줄 정리
- 정규화는 무결성을 위해 필수적이지만 JOIN 비용과의 트레이드오프가 존재하며,
실무에서는 보통 제3정규형까지를 권장합니다.
📂 4. 정규화 (2)
📌 4-1. 제1정규형(1NF): 원자값의 원칙
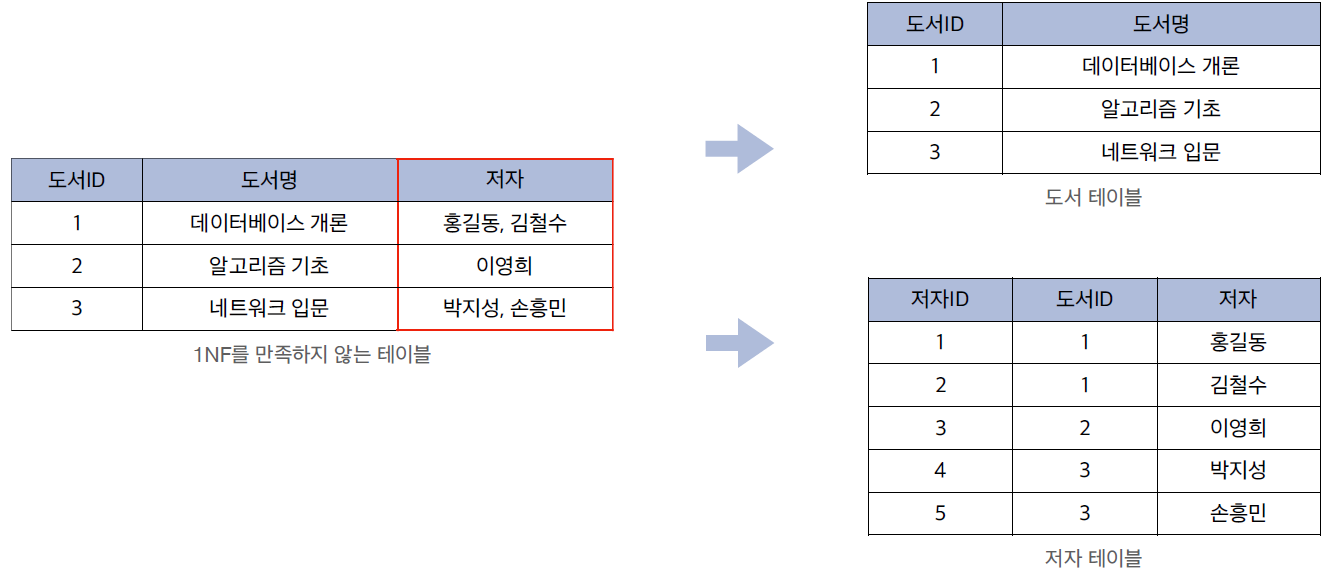
제1정규형의 핵심은 "테이블의 모든 속성이 더는 분해되지 않는 원자값(Atomic Value)을 가져야 한다"는 것입니다.
예를 들어, 저자 컬럼에 한 칸에 여러 명의 이름(홍길동, 김철수)이 들어가 있으면 데이터를 검색하거나 수정할 때 수많은 이상현상을 유발할 수 있습니다.
-
해결:
- 중복되는 요소를 분리하여 각 행이 단 하나의 원자값만 가지도록 테이블을 재구성해야 합니다.
-
제1정규형을 만족시킨 후, 테이블을 더 정교하게 다듬고 싶을 때 다음 단계인 제2정규형으로 넘어갑니다.
💡 비유로 이해하기
제1정규형은 '한 칸에 한 물건만 넣기'입니다.
서랍 한 칸에 온갖 물건을 다 쑤셔 넣어두면 나중에 필요한 물건 하나만 찾거나 꺼내기가 무척 힘든 것과 같습니다.
📌 4-2. 제2정규형(2NF): 부분 함수 종속 제거
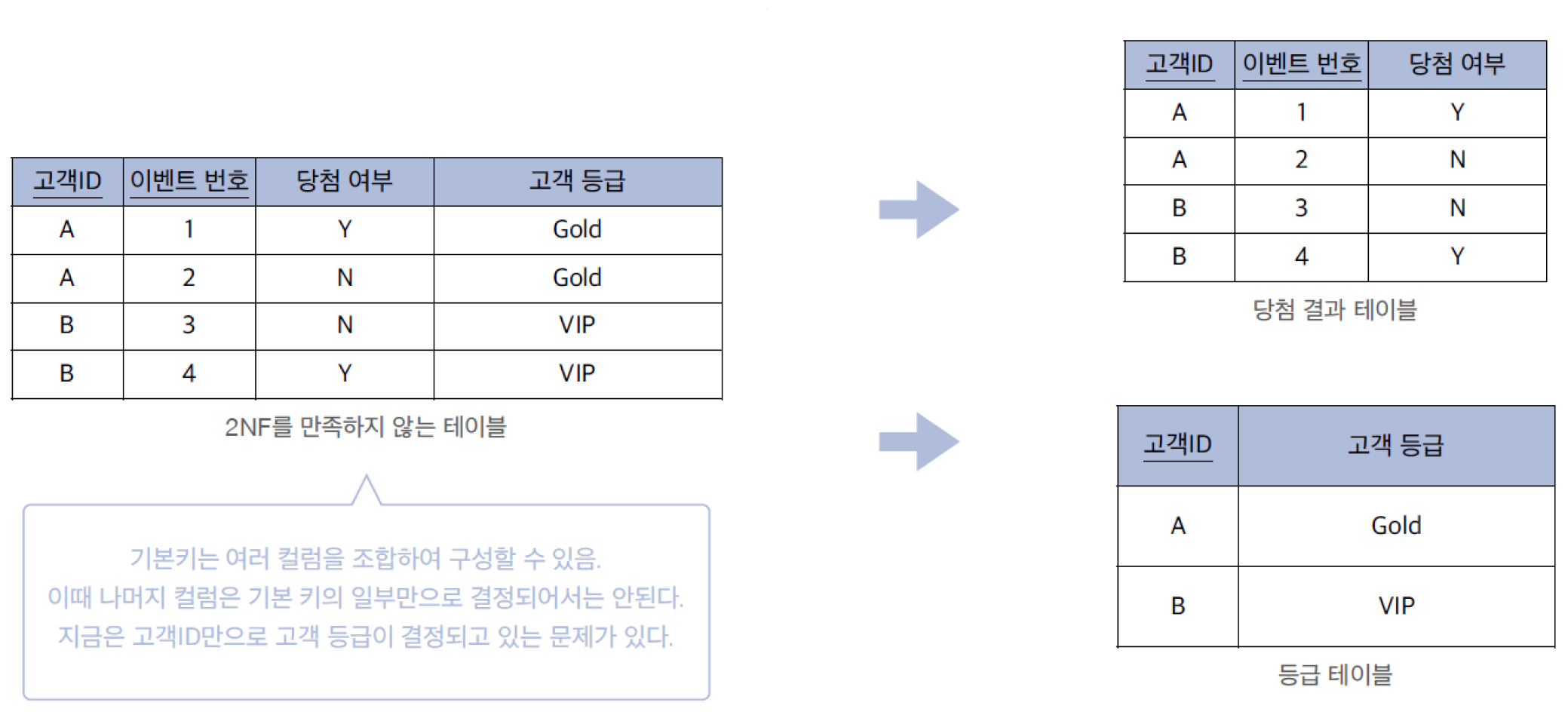
제2정규형은 제1정규형을 만족하면서, 기본키의 일부분에만 의존하는 속성을 제거하는 과정입니다.
-
기본키의 식별
- 보통 설계도에서 컬럼에 밑줄이 그어져 있다면 그 컬럼이 기본키로 사용된다는 뜻입니다.
- 만약 여러 컬럼에 밑줄이 있다면 두 개의 컬럼이 조합되어 기본키(복합키)를 구성하는 것입ㅇ니다.
-
문제 상황
- 특정 컬럼이 기본키 전체가 아니라, 기본키의 일부만으로도 결정되고 있다면 이를 부분 함수 종속이라고 합니다.
-
분해 결과
-
당첨 결과 테이블
- 고객 ID와 이벤트 번호가 모두 있어야 당첨 여부가 결정되므로 그대로 둡니다.
-
등급 테이블
- 고객 등급은 고객 ID에 의해서만 결정되므로 별도 테이블을 분리합니다.
- 이렇게하면 제2정규형을 만족하게 됩니다.
-
📌 4-3. 제3정규형(3NF): 이행적 종속 제거
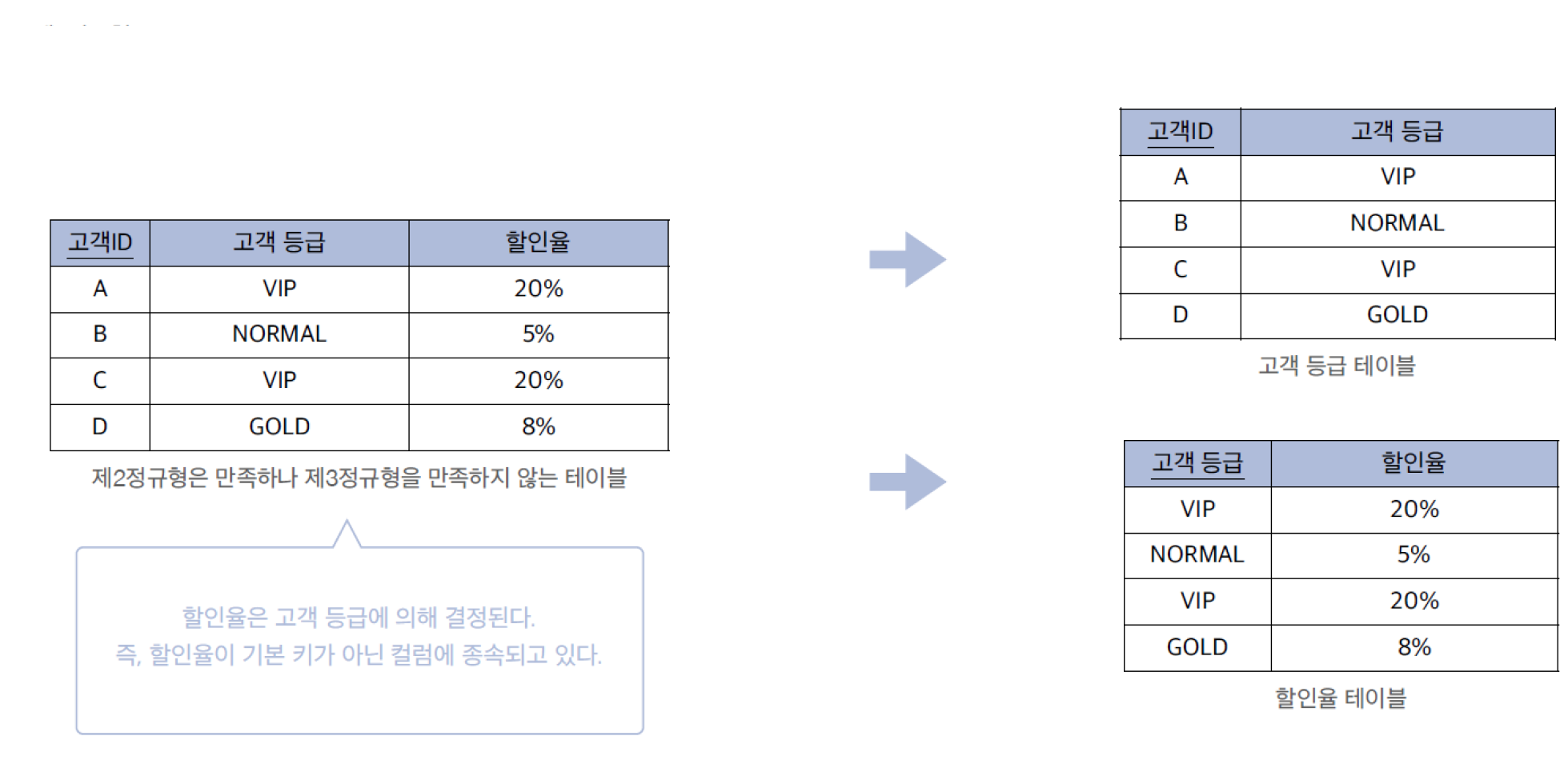
제3정규형은 제2정규형을 만족하면서, 기본키가 아닌 속성 간의 종속 관계를 제거하는 과정입니다.
-
핵심 원칙
- 기본키가 아닌 컬럼은 오직 기본키에만 의존해야 합니다.
- 만약 일반 속성 컬럼이 다른 일반 속성 컬럼에 의존하고 있다면, 이는 이행적 종속 상태입니다.
-
문제 상황
- 고객 테이블에서 '할인율'이 기본키인 '고객 ID'가 아닌 일반 속성은 '고객 등급'에 의해 결정되고 있다면 제3정규형 위반입니다.
-
해결
- '고객 등급 테이블'과 '할인율 테이블'을 분리하여 관리해야 합니다.
-
제3정규형까지 만족했다면 대부분의 이상현상은 해결할 수 있습니다.
📌 4-4. 헷갈리기 쉬운 포인트 / 오해 정리
- 1NF면 다 해결된다?
- 1NF는 단순히 '값의 형태'를 정리한 것이지, 데이터 간의 '의존 관계'로 인한 이상현상(2NF, 3NF 위반)은 여전히 남아 있을 수 있습니다.
📌 4-5. 한 줄 정리
- 정규화는 원자값(1NF), 부분 종속(2NF), 이행 종속(3NF)을 차례로 제거하여 데이터 무결성을 확보하는 필수 설계 과정입니다.
🎁 5. 정리
🔑 요약
-
데이터 무결성 전략의 핵심은 다음과 같습니다.
-
3대 이상 현상 차단
- 삽입 이상: 불필요한 정보 없이는 새 데이터를 넣지 못하는 상황
- 수정 이상: 중복된 데이터 중 일부만 수정되어 데이터 불일치가 발생하는 상황
- 삭제 이상: 특정 정보를 지울 때 원치 않는 정보까지 덩달아 사라지는 상황
-
실무형 정규화 3단계
- 제1정규형: 모든 속성은 '원자값'을 가져야 합니다.
- 제2정규형: 기본키의 일부에만 의존하는 '부분 함수 종속'을 제거합니다.
- 제3정규형: 일반 속성 간의 의존 관계인 '이행적 종속'을 제거합니다.
- 보통 3NF까지만 완벽히 수행해도 실무 데이터의 무결성은 충분히 확보됩니다.
-
트레이드오프와 반정규화
- 정규화는 무결성을 높이지만,
JOIN으로 조회 성능을 떨어뜨릴 수 있습니다. - 무조건적인 분해보다는 성능이 병목이 되는 지점에서 '철저히 계산된 중복'인 반정규화를 고려하는 유연함이 필요합니다.
- 정규화는 무결성을 높이지만,
-
