
[CS/자료구조] 01. 자료구조 개요와 복잡도 분석
⚡ 한 줄 요약: 데이터를 효율적으로 관리하는 자료구조의 분류(선형/비선형)를 이해하고, Big-O 표기법을 통해 알고리즘의 시간 및 공간 효율성을 판단하는 기준을 배웁니다.
1. 👋 들어가며: 자료구조와 알고리즘이 중요한 이유
프로그램의 성능은 어떤 자료구조를 선택하느냐에 따라 결정됩니다.
단순히 코드가 동작하는 것을 넘어, 데이터의 검색/삽입/삭제 속도를 최적화하기 위해서는 데이터의 특성에 맞는 구조를 선택할 수 있어야 합니다.
이번 글에서는 자료구조의 큰 흐름과 성능 분석의 필수 지표인 복잡도에 대해 알아봅니다.
-
🧐 Why:
- 데이터 규모가 커질수록 알고리즘 간의 성능 차이는 기하급수적으로 벌어지기 때문에,
최악의 상황에서도 안정적인 성능을 보장하는 코드를 작성하기 위함입니다.
- 데이터 규모가 커질수록 알고리즘 간의 성능 차이는 기하급수적으로 벌어지기 때문에,
-
🎯 Goal:
- 자료구조의 두 종류(선형, 비선형)를 구분하고, 시간·공간 복잡도의 개념과 Big-O 표기법을 익힙니다.
📂 2. 자료구조 개요
📌 2-1. 핵심 개념
자료구조를 한마디로 정의하면 데이터를 효율적으로 관리하는 방법입니다.
우리가 효율적인 자료구조를 선택해야 하는 이유는 데이터의 검색, 삽입, 삭제 속도를 높여 결국 프로그램의 성능을 향상시킬 수 있기 때문입니다.
자료구조는 크게 데이터가 배치되는 방식에 따라 선형과 비선형으로 나뉩니다.
-
선형 자료구조(Linear Data Structure)
-
데이터가 일정한 순서에 따라 연속적으로 배치되는 구조입니다.
-
특정 데이터의 앞과 뒤가 명확한 '선후 관계'가 있다는 것이 특징입니다.
-
배열: 같은 자료형의 데이터를 메모리의 연속된 공간에 저장합니다.
-
리스트: 데이터를 순차적으로 저장하며, 동적으로 크기를 조절할 수 있습니다. (ArrayList, LinkedList 등)
-
스택: 나중에 들어온 것이 먼저 나가는 후입선출(LIFO) 방식입니다.
-
큐: 먼저 들어온 것이 먼저 나가는 선입선출(FIFO) 방식입니다.
-
데크: 양쪽 끝에서 삽입과 삭제가 모두 가능합니다.
-
-
비선형 자료구조(Non-linear Data Structure):
-
데이터가 계층적이거나 복잡한 연결 관계를 가지며 비순차적으로 저장되는 구조입니다.
-
해시 테이블: 키-값 쌍으로 데이터를 저장하며, 해시 함수를 통해 매우 빠르게 검색합니다.
-
그래프: 정점(Vertex)과 간선(Edge)을 이용해 복잡한 객체 간의 관계를 표현합니다.
-
트리: 부모-자식 관계를 가지는 계층적 구조입니다.
-
힙: 최솟값이나 최댓값을 빠르게 찾기 위해 고안된 트리 기반 구조입니다.
-
💡 비유로 이해하기
선형 자료구조는 '한 줄로 서서 기다리는 편의점 계산대 줄'과 같고,
비선형 자료 구조는 '가족 관계도'나 '복잡하게 얽힌 지하철 노선도'와 같습니다.
📌 2-2. 헷갈리기 쉬운 포인트 / 오해 정리
- 비선형 자료구조에는 데이터 간의 '앞/뒤' 순서가 존재하지 않나요?
- 네. 비선형 자료구조는 데이터가 순차적으로 저장되지 않기 때문에 특정 데이터들 사이에 절대적인 선후 관계가 존재하지 않습니다.
- 비선형은 '순서'보다는 '관계와 계층'에 초점이 맞춰져 있습니다.
📌 2-3. 한 줄 정리
- 자료구조는 알고리즘의 성능을 결정짓는 핵심 도구이며, 데이터 간의 선후 관계 유무에 따라 선형과 비선형으로 구분됩니다.
💻 참고
프론트엔드 실무에서 마주하는 DOM(Documnet Object Model)은 대표적인 비선형 자료구조인 트리 형태입니다.
우리가
querySelector로 요소를 찾거나 컴포넌트 계층을 설계할 때 이미 비선형 자료구조의 원리를 활용하고 있는 셈입니다.
📂 3. 시간 복잡도 (1)
📌 3-1. 시간 복잡도의 중요성
시간 복잡도는 단순히 코드가 돌아가는 시간을 측정하는 것이 아니라,
입력 데이터의 크기()가 커짐에 따라 연산 횟수가 어떻게 변하는지를 분석하는 것입니다.
-
성능 예측
- 입력이 커질수록 프로그램이 얼마나 더 느려질지 미리 예측할 수 있습니다.
-
효율적 선택
- 같은 기능을 구현하더라도 알고리즘 선택에 따라 속도 차이가 수천 배 이상 날 수 있습니다.
-
실무 필수 지표
- 대용량 데이터 처리나 성능 이슈 디버깅, 특히 기술 면접의 코딩 테스트에서 필수적인 지표입니다.
-
신뢰성
- 실제 코드가 당장은 빨라 보이더라도, 데이터가 쌓였을 때 성능이 급격히 떨어지는 상황을 방지해야 합니다.
📌 3-2. Big-O 표기법
실무에서 개발자는 "언제 어떤 입력이 오더라도 성능이 급격히 나빠지지 않도록" 보장해야 합니다.
가끔씩 느려지는 프로그램은 사용자가 신뢰할 수 없기 때문입니다.
그래서 우리는 최악의 시나리오에서도 안전한 성능을 보장하기 위해 빅-오(Big-O) 표기법을 사용합니다.
📌 3-3. 주요 시간 복잡도 비교
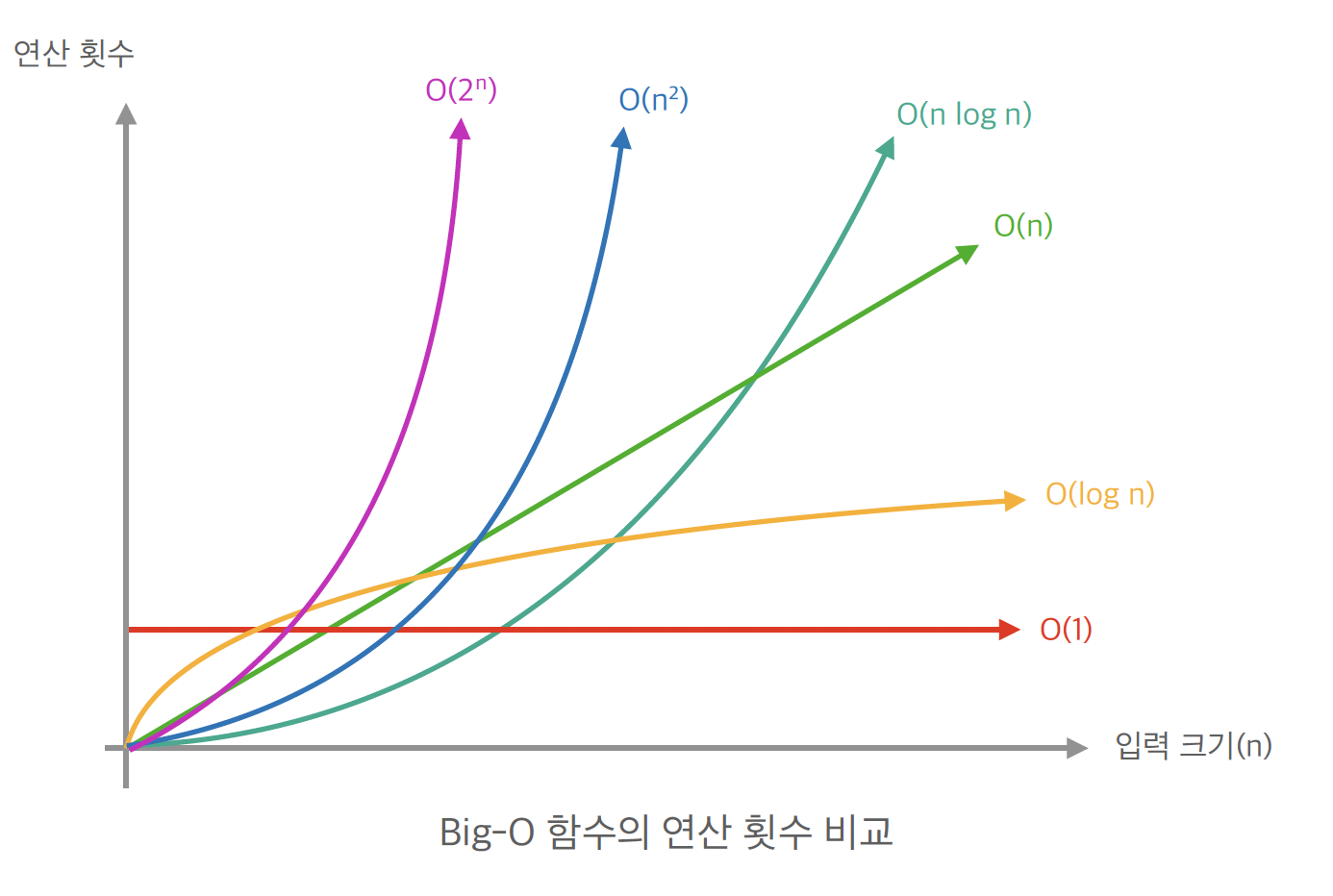
| 입력 크기() | |||||
|---|---|---|---|---|---|
| 10 | 1 | 3.3 | 10 | 33.2 | 100 |
| 100 | 1 | 6.6 | 100 | 664.4 | 10,000 |
| 1,000 | 1 | 9.9 | 1,000 | 9,966 | 1,000,000 |
-
(상수 시간)
- 입력 크기와 상관없이 항상 일정한 연산 횟수가 필요합니다.
- 이 아무리 커져도 안정적이라 시간 복잡도 측면에서 매우 훌륭합니다.
-
(로그 시간)
- 데이터가 늘어나도 연산 횟수가 매우 천천히 증가합니다.
-
(로그 선형 시간)
- 데이터가 늘어나도 연산 횟수가 매우 천천히 증가합니다.
-
(이차 시간)
- 이 커짐에 따라 연산 횟수가 제곱으로 급증합니다.
- 성능 저하의 주범이 될 수 있어 주의해서 사용해야 합니다.
-
(지수 시간)
- 연산 횟수가 폭발적으로 늘어나는 가장 위험한 단계입니다.
💡 비유로 이해하기
은 책장에서 내가 원하는 책의 위치를 이미 알고 있어 바로 꺼내는 것이고,
은 책의 첫 장부터 마지막 장까지 한 장씩 넘기며 원하는 내용을 찾는 것과 같습니다.데이터가 100만 권으로 늘어난다면 그 차이는 어마어마하겠죠?
📌 3-4. 헷갈리기 쉬운 포인트 / 오해 정리
-
"내 컴퓨터에서는 빠른데?"
- 성능은 하드웨어 사양에 따라 달라질 수 있습니다.
- 그래서 우리는 절대적인 '초' 단위가 아니라, 데이터 증가에 따른 '연산 횟수'의 추이인 시간 복잡도를 보는 것입니다.
-
은 무조건 빠르다?
- 연산 횟수가 일정하다는 뜻이지, 그 1번의 연산 자체가 매우 무겁다면 보다 느릴 수 있습니다.
- 하지만 이 커질수록 결국 이 승리하게 됩니다.
📌 3-5. 한 줄 정리
- 어떤 입력값에도 신뢰할 수 있는 성능을 보장하기 위해,
최악의 시나리오를 기준으로 삼는 Big-O 표기법을 항상 염두에 두어야 합니다.
📂 4. 시간 복잡도 (2)
📌 4-1. 왜 상수는 버려지는가?
우리가 Big-O 표기법에서 상수나 낮은 차수의 항을 무시하는 이유는
입력 이 압도적으로 커지는 상황을 가정하기 때문입니다.
- 성장 추세의 중요성
- 이 작을 때는 상수항이 영향을 주지만, 이 커질수록 최고차항이 전체 연산 횟수를 지배합니다.
- 수식의 단순화
- 위 수식에서 이 매우 커지면 의 영향력이 압도적이며, 여기서 계수인 3마저 떼어내어 으로 표기합니다.
📌 4-2. 의 마법: 이진 탐색
-
동작 원리
- 정렬된 배열을 전제로, 항상 탐색 범위를 절반씩 줄여가며 값을 찾습니다.
-
수치로 보는 효율성
- 만약 1,000개의 데이터가 있다면, 중간값을 확인한 뒤 크고 작음에 따라 범위를 500개, 250개, 125개 순으로 절반씩 날려버립니다.
-
결과
- 데이터가 아무리 많아져도 연산 횟수가 매우 안정적으로 증가하기 때문에, 단 몇 번의 시도만으로도 특정 값을 정확히 찾아낼 수 있는 강력한 성능을 자랑합니다.
📌 4-3. 코드 예시로 보는 복잡도
실제 코드에서는 어떤 형태로 나타내는지 파이썬 예시로 확인해 보세요.
-
- 상수 시간: 배열의 인덱스로 즉시 접근하는 경우입니다.
def get_first_element(arr): return arr[0] # 입력 크기와 상관없이 즉시 반환 -
- 선형 시간: 배열의 모든 요소를 하나씩 확인해야 하는 경우입니다.
def find_target(arr, target): for item in arr: # n에 비례해 연산 증가 if item == target: return True return False -
- 이차 시간: 중첩 반복문을 사용하여 모든 쌍을 비교하는 경우입니다.
def print_all_pairs(arr): for a in arr: for b in arr: # n * n 연산 print(a, b)
📌 4-4. 헷갈리기 쉬운 포인트 / 오해 정리
-
이진 탐색은 언제나 쓸 수 있다?
- 아닙니다. 이진 탐색의 전제 조건은 데이터가 정렬되어 있어야 한다는 점입니다.
- 정렬되지 않은 데이터에서 절반씩 날리는 방식은 성립하지 않습니다.
-
은 정렬의 기준
- 퀵 정렬이나 병합 정렬 같은 효율적인 정렬 알고리즘들이 이 복잡도를 가집니다.
- 일반적은 정렬(버블, 선택 정렬)보다 훨씬 빠릅니다.
📌 4-5. 한 줄 정리
- Big-O는 세세한 숫자보다 데이터 증가에 따른 성능의 '급'을 나누는 도구이며,
인 이진 탐색은 정렬된 데이터에서 최강의 효율을 보입니다.
📂 5. 공간 복잡도
📌 5-1. 공간 복잡도
공간 복잡도는 알고리즘이 실행될 때 필요한 메모리 사용량을 분석한 것입니다.
입력 데이터의 크기에 따라 얼마나 많은 추가 공간이 필요한지를 계산하며, 주로 빅-오(Big-O) 표기법을 사용합니다.
📌 5-2. 공간 복잡도의 중요성
-
제한된 자원
- 시간만큼이나 공간도 제한적인 자원입니다.
-
치명적인 에러
- CPU는 조금 느려도 사용자가 기다릴 수 있지만, 메모리는 부족하면 프로그램이 즉시 종료(Out Of Memory)됩니다.
- 특히 모바일이나 임베디드 환경에서도 메모리 제한에 걸리면 서비스 자체가 실패하게 됩니다.
📌 5-3. 코드 예시로 보는 공간 복잡도
-
(상수 공간): 추가적인 메모리 할당 없이 기존 데이터를 출력만 하는 경우입니다.
def print_items(arr): for item in arr: print(item) -
(선형 공간): 입력 크기만큼의 새로운 배열을 생성하거나, 재귀 호출이 번 발생하여 스택 프레임이 쌓이는 경우입니다.
def double_items(arr): result = [] for item in arr: result.append(item * 2) return resultdef factorial(n): if n == 0: return 1 return n * factorial(n - 1)
📌 5-4. 시공간 트레이드오프
우리가 알고리즘을 설계할 때 가장 고민하는 지점이 바로 이 트레이드오프입니다.
-
개념
- 속도를 위해 메모리를 더 쓰거나, 반대로 메모리를 아끼기 위해 속도를 일부 포기하는 결정을 말합니다.
-
관계
- 보통 시간 복잡도와 공간 복잡도는 반비례적인 관계를 갖습니다.
-
실무의 관점
- "어떤 것이 정답이다"라는 건 없습니다.
- 현재 서비스가 돌아가는 서버 환경이나 사용자 단말기 사양에 맞춰 이 트레이드오프를 잘 고려해 적절한 대처를 하는 것이 시니어 개발자의 역량입니다.
📌 5-5. 헷갈리기 쉬운 포인트 / 오해 정리
- 시간 복잡도와 공간 복잡도 중 무엇이 더 중요한가요?
- 둘 다 중요하지만 현대 컴퓨팅 환경에서는 메모리 용량이 비교적 넉넉해졌기 때문에
보통 시간 복잡도를 우선해서 최적화합니다. - 하지만, 두 지표는 반비례 관계에 있는 경우가 많으므로, 메모리가 극도로 제한된 환경에서는 공간 복잡도를 낮추기 위해 연산 횟수(시간)을 늘리는 결정을 내리기도 합니다.
- 결국 상황에 맞는 트레이드오프 선택이 핵심입니다.
- 둘 다 중요하지만 현대 컴퓨팅 환경에서는 메모리 용량이 비교적 넉넉해졌기 때문에
📌 5-6. 한 줄 정리
- 시간과 공간은 서로를 주고받는 관계이므로, 서비스 환경에 맞춰 '속도'와 '메모리' 사이의 최적의 균형점을 찾는 것이 중요합니다.
💻 참고
프론트엔드 실무에서 자주 쓰는 메모이제이션이나 캐싱이 대표적인 '공간을 써서 시간을 사는' 행위입니다.
리액트의
useMemo도 이전 계산값을 메모리에 저장해두고 재사용함으로써 렌더링 속도를 높이는 트레이드오프의 한 예시라고 볼 수 있습니다.
🎁 6. 정리
🔑 요약
-
자료구조의 분류
- 선형 구조: 데이터가 연속적으로 배치됨 (배열, 스택, 큐 등)
- 비선형 구조: 계층적이거나 복잡한 관계를 표현함 (그래프, 트리 등)
-
시간 복잡도와 Big-O
- 입력 크기 에 따른 연산 횟수의 추이를 분석하여 성능을 예측합니다.
- 최악의 시나리오를 기준으로 성능을 보장하는 Big-O 표기법을 주로 사용합니다.
- , 은 매우 빠르며, 이상은 데이터 증가 시 성능 저하에 주의해야 합니다.
-
이진 탐색의 효율성
- 정렬된 데이터에서 탐색 범위를 절반씩 줄여나가며 의 강력한 성능을 가집니다.
-
공간 복잡도와 트레이드오프
- 메모리 사용량을 분석하며, 현대 프로그래밍에서는 보통 시간(속도)를 위해 공간(메모리)를 더 사용하는 트레이드오프 전략을 자주 활용합니다.
