
개요
해당 글은 웹 프로그래머를 위한 데이터베이스를 지탱하는 기술 Chapter 2 를 정리한 글입니다.
Velog에서는 어떻게 우리에게 게시물을 보여줄까요? 서버로 https://velog.io/@iamtaehoon/왜 데이터베이스는 빠른 검색이 가능할까? 요청을 보내면 지금 보고 계신 이 글에 들어올 수 있습니다.
Velog 서버는 블로그 이름과 제목을 통해 DB에서 게시물에 관련된 데이터를 가져온다는 걸 알 수 있습니다.
신기하지 않나요? Velog에는 적게잡아도 수만개, 아마 수십만개의 글이 있을텐에 굉장히 빠르게 게시물을 불러왔습니다.
바로 데이터베이스가 이걸 가능하게 해줍니다. 과연 어떤 원리로 만들어졌기에 이런 작업이 가능한건지 함께 알아보겠습니다.
데이터를 찾는 방법
게시물에는 어떤 정보들이 필요할까요? 단순하게 살펴보면 블로그 이름, 제목, 내용, 작성자 등의 정보를 담고 있어야합니다.
이해를 쉽게 하기 위해서 Velog는 게시물에 접근할 때 순차적으로 늘어나는 ID를 사용한다고 가정해볼게요. 이 글의 ID는 12345라고 가정하겠습니다.
순차 검색
가장 쉽게 생각할 수 있는 방법은 모든 데이터를 하나씩 살펴보는겁니다.
id가 12345인 레코드를 찾아서 반환하면 됩니다.
하지만 너무 느릴 거 같습니다. 수많은 게시물 중에서 언제 저걸 찾고 있나요.
그 다음으로 생각할 수 있는 방법은 게시물을 저장할 때 고정된 크기로 블로그의 정보들을 담는 겁니다.
고정된 크기로 게시물을 저장하기

예를 들어 블로그의 글을 저장할 때 한 개당 100KB라는 저장공간을 할당해줍니다.
데이터들은 하드웨어에 순차적으로 저장될 겁니다. id가 12345라면 시작위치 + 12345 * 10000 를 해주면 해당 게시물에 접근할 수 있게 됩니다.
속도는 빠르겠지만 문제가 있습니다. 게시물이 100KB가 넘어가면 더이상 내용을 추가할 수 없습니다.
저장공간을 여유롭게 할당하면 되지 않을까요?
고정된 크기로 게시물을 저장하기(여유롭게)
두 가지 문제가 있습니다. 여유롭다의 기준이 어디인지도 모를 뿐더러, 크기를 크게 잡을수록 저장공간의 낭비가 심해집니다.
1MB짜리 게시물을 담기 위해서는 1KB, 100KB짜리 게시물도 1MB 게시물과 같은 크기의 공간에 담겨야 합니다.
고정크기를 사용하는 방법은 문제가 있습니다. 여기에서 인덱스라는 개념이 나옵니다.
인덱스를 사용하기

책 가장 뒤 페이지를 펴면 볼 수 있는 이것이 인덱스(색인)입니다.
인덱스를 사용하면 해당 글자가 어디 위치에서 나왔는지를 확인할 수 있습니다.
이제 게시물을 저장할 때 다음과 같은 방식으로 저장이 가능합니다.
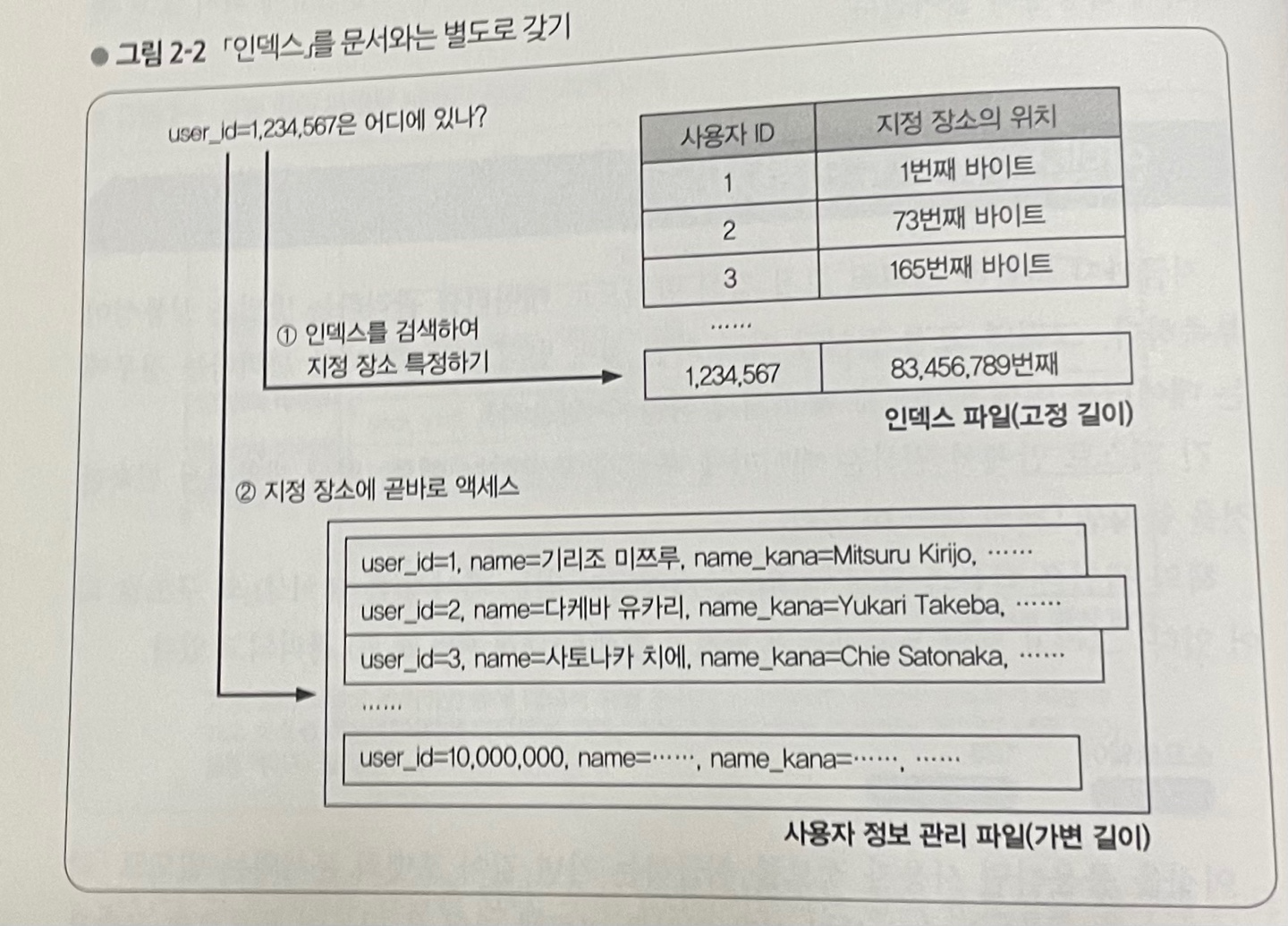
인덱스를 통해 우리는 찾으려는 데이터를 순식간에 찾을 수 있게 되었습니다. 데이터 역시 고정된 크기로 관리할 필요가 없어졌습니다.
참조를 사용해 저장하는 방식은 빈번하게 사용되는 테크닉입니다.
크기가 고정되지 않은 무언가를 저장할 때는 참조만한 게 없다고 보여집니다.
Elasticsearch도 참조 개념으로 만들어졌고,
Java의 Heap 메모리 역시 참조 개념을 사용해 객체를 저장합니다.
인덱스 만들기
인덱스를 사용하면 효과적으로 데이터를 저장할 수 있다는 걸 알게 되었습니다.
인덱스를 어떻게 만드는지 MySQL을 기준으로 알아보겠습니다.
해시 인덱스
첫 번째 방법은 해시를 사용해 인덱스를 만드는 겁니다. Velog에서 블로그를 찾는 상황이라고 생각해보겠습니다.
인덱스로 사용할 컬럼을 선택합니다. Velog는 블로그를 찾기 위해 블로그명을 사용합니다. iamtaehoon을 Hash 함수를 돌려 10이라는 값을 받아왔습니다.
<구림필요>
이제 시작지점 + 10 *
핵심은 value 형태로 인덱스가 저장된다는 것입니다.
key에는 식별자, value에는 데이터가 저장되어 있는 주소가 들어갑니다.
iamtaehoon을 Hash 함수에 넣고 돌리면 항상 10이라는 결과가 나옵니다. 즉, 해시를 사용해 인덱스를 만들면 상수 시간으로 게시물에 접근할 수 있습니다.
문제점 - 범위 검색 불가능
해시 함수는 단일값을 조회하는 데 있어서는 최적의 성능을 내지만, 범위 검색이 불가능하다는 문제가 있습니다.
블로그 이름이 a로 시작하는 모든 블로그를 찾아야 한다면 해시 인덱스를 사용할 수 없습니다. 전체 탐색이 필요합니다.
a로 시작하는 ab, aaa, apple, ... 등 몇 개의 key가 존재하는지 알 수 없고, 여러 key들에 대해서 해시 함수의 결과값을 예측할 수 없기 때문입니다.
정리하면 해시 인덱스는 단일 값을 찾아오는 데 있어서는 최고의 성능을 내지만, 여러 값을 찾아오기에는 부적절하다고 할 수 있겠습니다.
그렇다면 select * from post where id > 1 and id < 1000 이런 쿼리를 처리하려면 어떤 구조를 가져가야 할까요?
B+ Tree 인덱스
바로 B+ Tree를 사용해 인덱스를 만드는 겁니다. B+ Tree가 무엇이냐,
B+ Tree는 자식을 N개 가진 트리로, Leaf 노드에만 값을 저장할 수 있다는 특징이 있습니다.
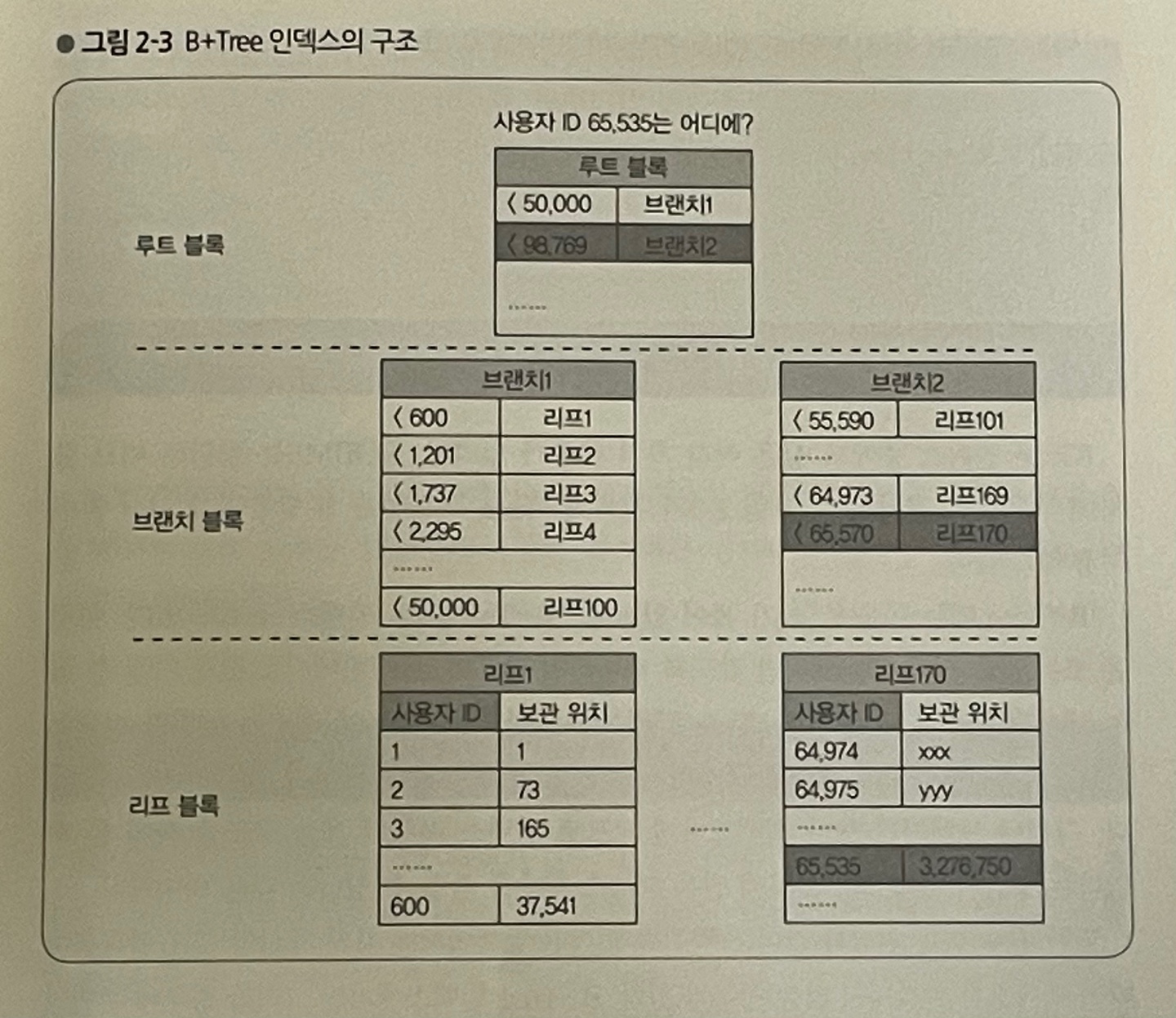
위에서 보이는 B+ Tree에서 65535라는 사용자를 찾아보겠습니다.
- 65535는 50000과 98769 사이에 있으므로 브랜치 2로 넘어갑니다.
- 브랜치 2에서 범위에 맞는 리프 170으로 넘어갑니다.
- 리프 170에서 사용자 ID가 65535를 찾아 보관 위치를 확인합니다.
- 보관 위치를 찾아가 실제 사용자에 대한 정보를 가져옵니다.
고작 4번의 접근으로 1부터 98769까지의 숫자 중 65535를 찾을 수 있었습니다. B+ Tree를 사용하면 이처럼 굉장히 빠른 속도로 데이터를 찾을 수 있습니다.
범위 탐색
B+ Tree를 사용하면 해시 테이블에서 하지 못했던 범위 탐색이 가능해집니다.
위 예시에서 ID가 600부터 65536까지인 사용자들을 찾으라는 문제가 주어졌다고 가정하겠습니다.
먼저 MySQL은 리프 블록에서 사용자 ID가 600인 계정을 찾습니다. 그 후, 65535라는 데이터가 나올 때까지 계속해서 리프를 타고 이동합니다.
즉, 리프 노드는 데이터들이 정렬되어 있는데 시작점과 끝 점 사이에 있는 값들을 선택함으로써 범위 탐색이 가능해집니다.
이러한 이유로 MySQL은 인덱스를 만들 때 기본값으로 B+ Tree를 사용합니다.
B+ Tree의 특징을 정리하며 다음으로 넘어가겠습니다
1. Leaf Node에만 값을 저장할 수 있다.
2. Leaf Node 간에 편리한 이동을 위해 pointer로 연결되어 있다.
3. 모든 Leaf Node는 같은 depth에 위치한다.
- 데이터를 리프 노드에만 저장하는 이유는 범위 탐색을 편리하게 하기 위함입니다.
- B- Tree는 리프 노드 외에 다른 노드들에도 데이터를 저장할 수 있습니다.
- MySQL을 제외한 대부분의 RDB에서는 B- Tree를 사용한다고 합니다.
- B+ Tree(and B- Tree)는 굉장히 중요한 개념입니다. 추가적인 학습을 권장합니다.
Velog가 해당 글을 찾는 방법
드디어 처음 예시로 돌아와보겠습니다.
우리는 블로그명, 그리고 게시물의 제목을 사용해 게시물을 찾아왔습니다.
Posts 테이블에는 다음 컬럼들이 존재할 것으로 예상합니다.
// 실제 구조는 다를 수 있습니다!!
Posts 테이블
- id
- blog_name
- writer_id
- title
- contents
- ...성능의 최적화를 위해 blog_name 컬럼에 대한 인덱스를 생성합니다.
해당 글을 조회하기 위해 아래 쿼리를 사용합니다.
select * from Posts where blog_name='iamtaehoon' and title='왜 데이터베이스는 빠른 검색이 가능할까?'
MySQL 실행엔진은 인덱스를 사용해 제 블로그의 모든 글을 가져오고, 거기에서 title을 가지고 filtering을 걸어줍니다.
이렇게 Velog에 존재하는 수많은 글 중 제 글을 빠르게 찾아 반환하게 되었습니다.
마치며
Velog 내부 구조를 알 수는 없지만 blog_name과 title에 대해 Multi Column Index가 걸려 있을 수도 있겠다는 생각을 합니다.
만약 제목의 변경이 빈번하다면 위에서 설명한대로 filtering을 사용할 거고, 잘 바뀌지 않는다면 Multi Column Index가 걸려 있을 거라고 추측해봅니다.
개인적인 견해로는 블로그 이름 + 별도의 게시물 식별자를 사용하는게 성능상 더 좋지 않았을까.. 생각도 들지만, Velog 측에서는 이름이 보이는 게 더 사용성 면에서 좋겠다고 판단한거겠죠? 성능에 있어서 큰 차이가 없을 수도 있고요.
멀티 컬럼 인덱스에 대한 글을 여기 적어뒀습니다. 궁금하신 분들은 함께 읽어주시면 감사하겠습니다.
출처
웹 프로그래머를 위한 데이터베이스를 지탱하는 기술 - 마쯔노부 요리노시
