들어가기에 앞서
Isolation Level은 트랜잭션의 속성 중 Isolation 과 관련된 개념입니다.
트랜잭션은 여러 트랜잭션이 동작해도 하나의 트랜잭션처럼 동작하게 보여져야 합니다.
그것이 Isolation이니까요(끄덕)
그런데 실제 데이터베이스는 트랜잭션을 항상 Isolation하게 실행하지 않습니다.
이유는 성능 때문입니다. 해당 속성을 엄격하게 지킬수록 데이터베이스의 성능이 나빠집니다. 확인해야 할 게 많으면 당연히 처리량이 줄어듭니다.
그래서 개발자들은 성능을 위해 어느정도 타협을 합니다. 상황에 따라 적용 가능한 4가지 선택지를 만들었는데요. 이게 Isolation Level이라는 개념입니다.
우선 Isolation을 지키지 않았을 때, 어떤 문제들이 일어날 수 있는지를 살펴보겠습니다.
발생 가능한 문제
Dirty Read
다른 트랜잭션에서 변경함 + 아직 커밋되지 않은 데이터를 읽을 때 발생 가능한 문제입니다. 예시를 통해 설명하겠습니다.

x와 y라는 자원에 대해 2개의 트랜잭션이 일어납니다. 트랜잭션 1이 성공한다 가정하면 우리는 두 가지 결과가 될 거라고 예상할 수 있습니다.
1. x=80, y=70 (트랜잭션 2 성공)
2. x=30, y=20 (트랜잭션 2 실패)하지만 아래 사진과 같이 동작한다면 어떻게 될까요?
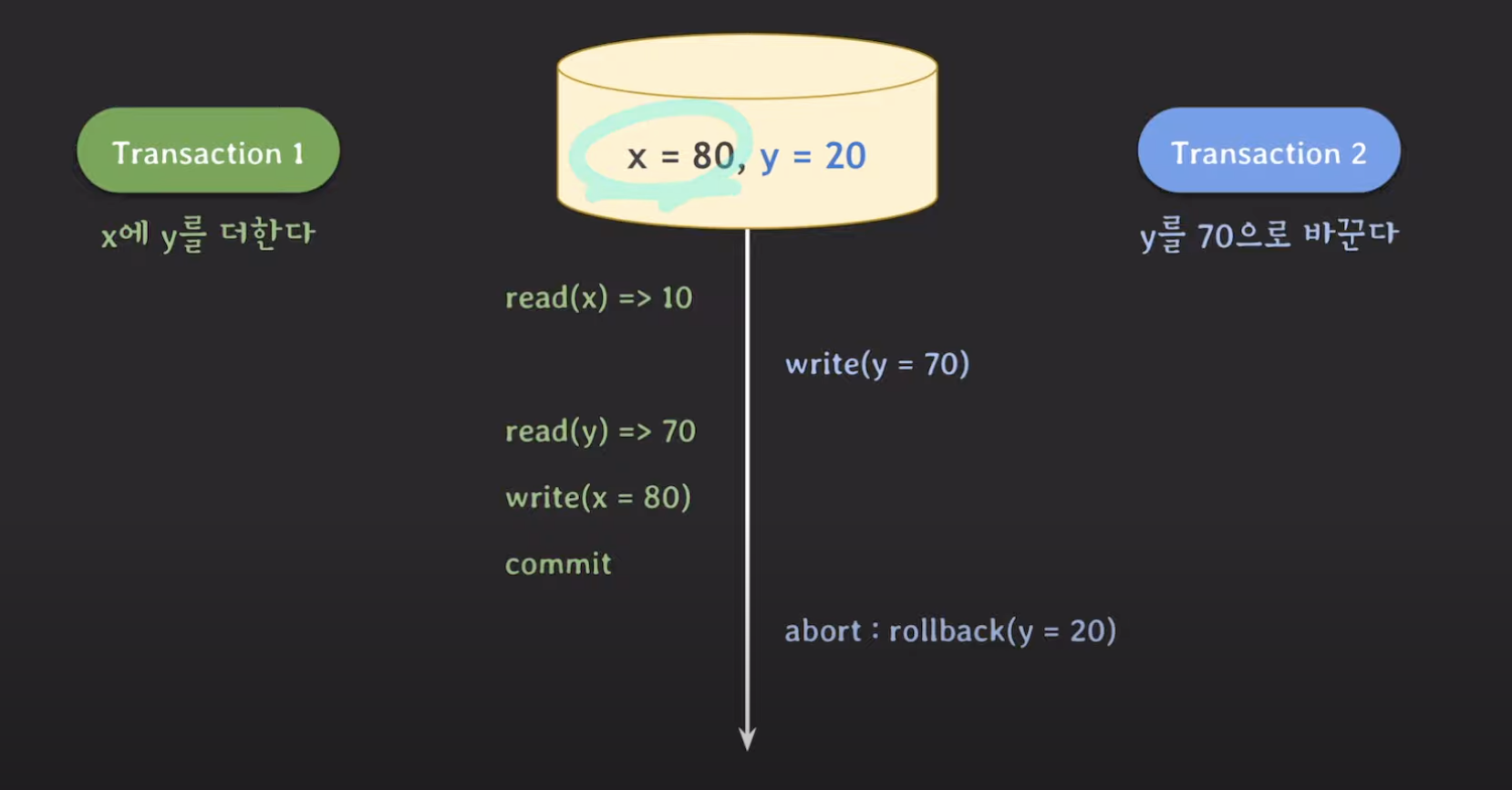
트랜잭션 1은 y가 70으로 바뀐 다음 읽어왔는데, 트랜잭션 2가 롤백되면서 y가 70이라는 정보는 사라졌습니다.
결과값은 x=80, y=20이라는 예측하지 못한 값이 나왔습니다.
Non Repeatable Read
다음 문제상황은 하나의 트랜잭션에서 동일한 자원을 두 번 읽어올 때 발생할 수 있는 문제입니다.
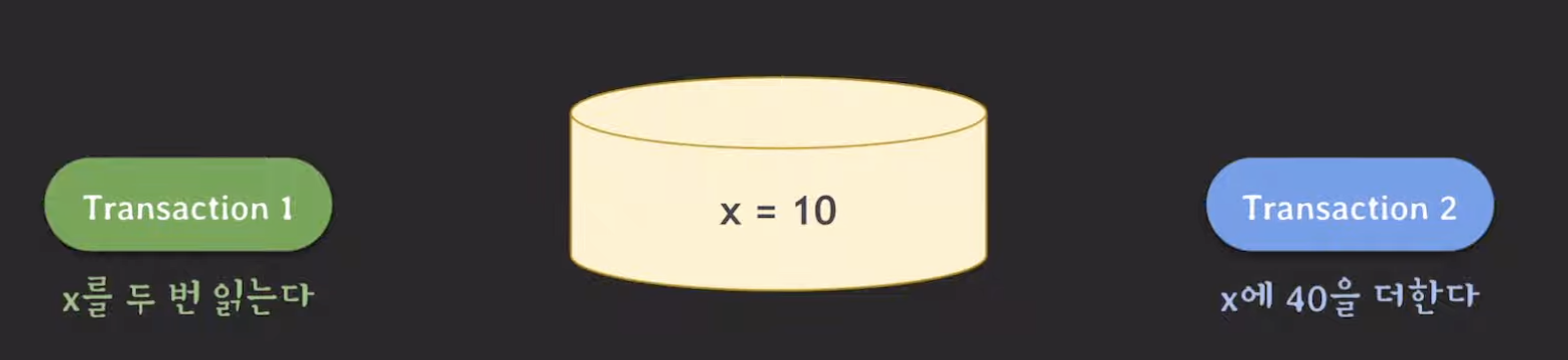
두 번째 문제는 데이터를 두 번 읽어오는 상황에서 발생할 수 있습니다. 원칙대로라면 Transaction 1 read(x)에 대한 결과가 동일해야 합니다. 왜? 하나의 트랜잭션만 동작하는데, Transaction 1이 변경하지 않았으면 값이 변경될 이유가 없으니까요. 하지만 아래 예시에서는 결과값이 달라집니다.

Phantom Read
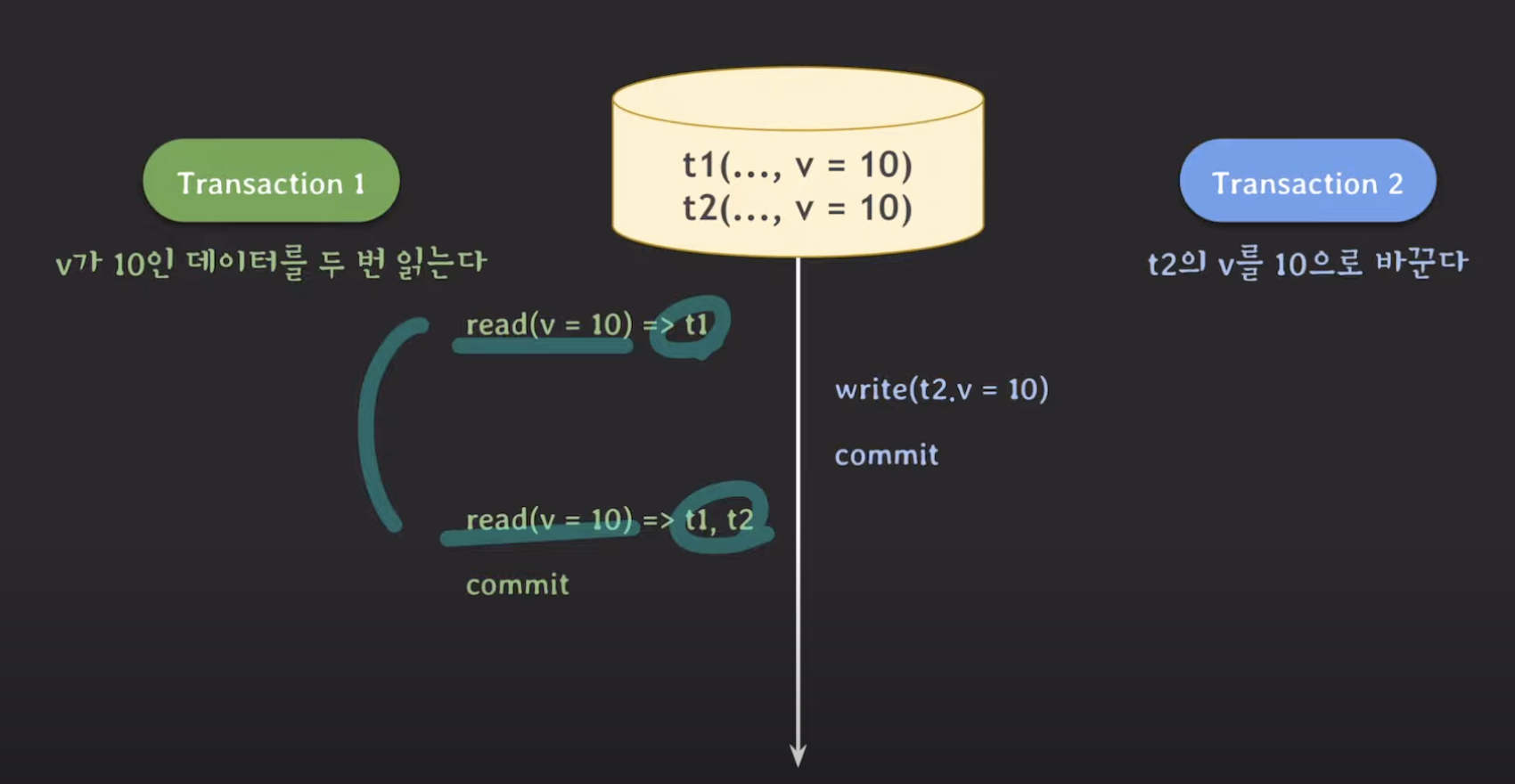
세 번째 상황은 존재하지 않던 데이터가 생길 때 발생할 수 있는 문제입니다.
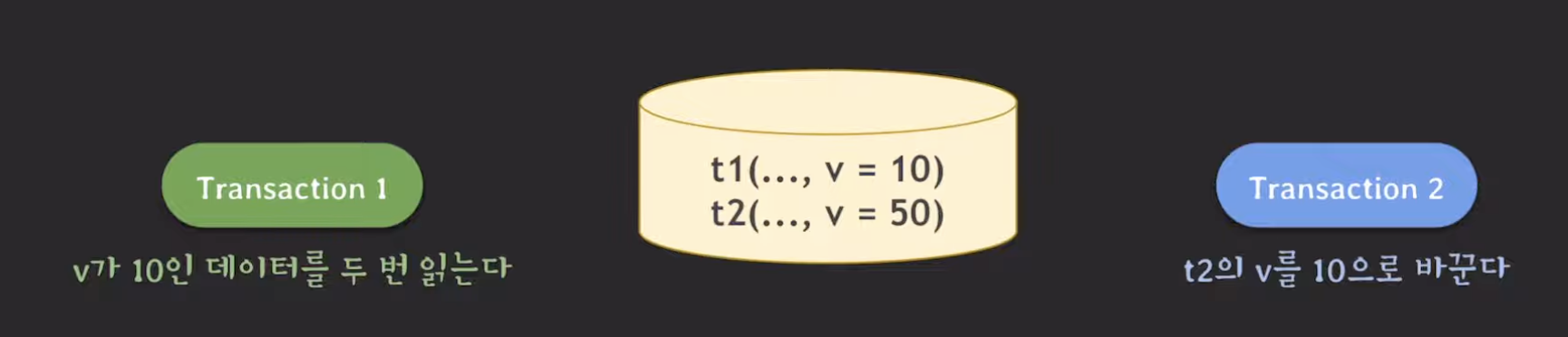
마찬가지로 트랜잭션 안에서 동일한 요청에 대해 결과값이 달라졌습니다.
Isolation Level

위의 표는 Isolation Level에 따른 발생가능한 문제들을 보여줍니다.
개발자들은 상황에 따라 적절한 Isolation Level을 선택합니다.
Serializable은 Isolation을 만족하는 level로, 어떤 문제도 발생하지 않는 level입니다.
복구 안정성
Read uncommitted level은 Rollback이 안전하게 일어났다고 보장할 수 없습니다. 앞선 Dirty read 문제의 예시를 보면 Rollback이 일어날 때 문제가 발생하는 걸 확인할 수 있습니다.
다른 Level들은 Rollback이 안전하게 일어났다고 보장할 수 있습니다.
Read uncommited level을 쓰는 경우는 정말 없습니다. 데이터를 안전하게 Rollback 할 수 없다는 건 치명적인 문제입니다. 알고 가자구요.
출처
쉬운코딩 유튜브 : https://www.youtube.com/watch?v=DwRN24nWbEc&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=15
