
"또 알람이네... 조금 있으면 자동으로 복구되겠지"
모니터링 알람이 너무 자주 와서 오히려 무시하게 되는 문제를 겪고 있었습니다.
문제는 명확했습니다. 알람에 대한 이해 부족, 불명확한 임계치, 해결 방법 부재로 인해 장애가 발생해도 "조금만 있으면 바로 다시 올라오겠지" 하고 기다리기만 하는 상황이었죠.
이 문제를 해결하기 위해 장애 알람 체계 T/F 팀이 구성되었고, 저는 System 파트를 담당하게 되었습니다. 팀 인프라 운영에 필요한 서버 및 시스템들을 모니터링하는 역할이었죠.
현재 상황 분석
먼저 어떤 문제들이 있었는지 정리해봤습니다.
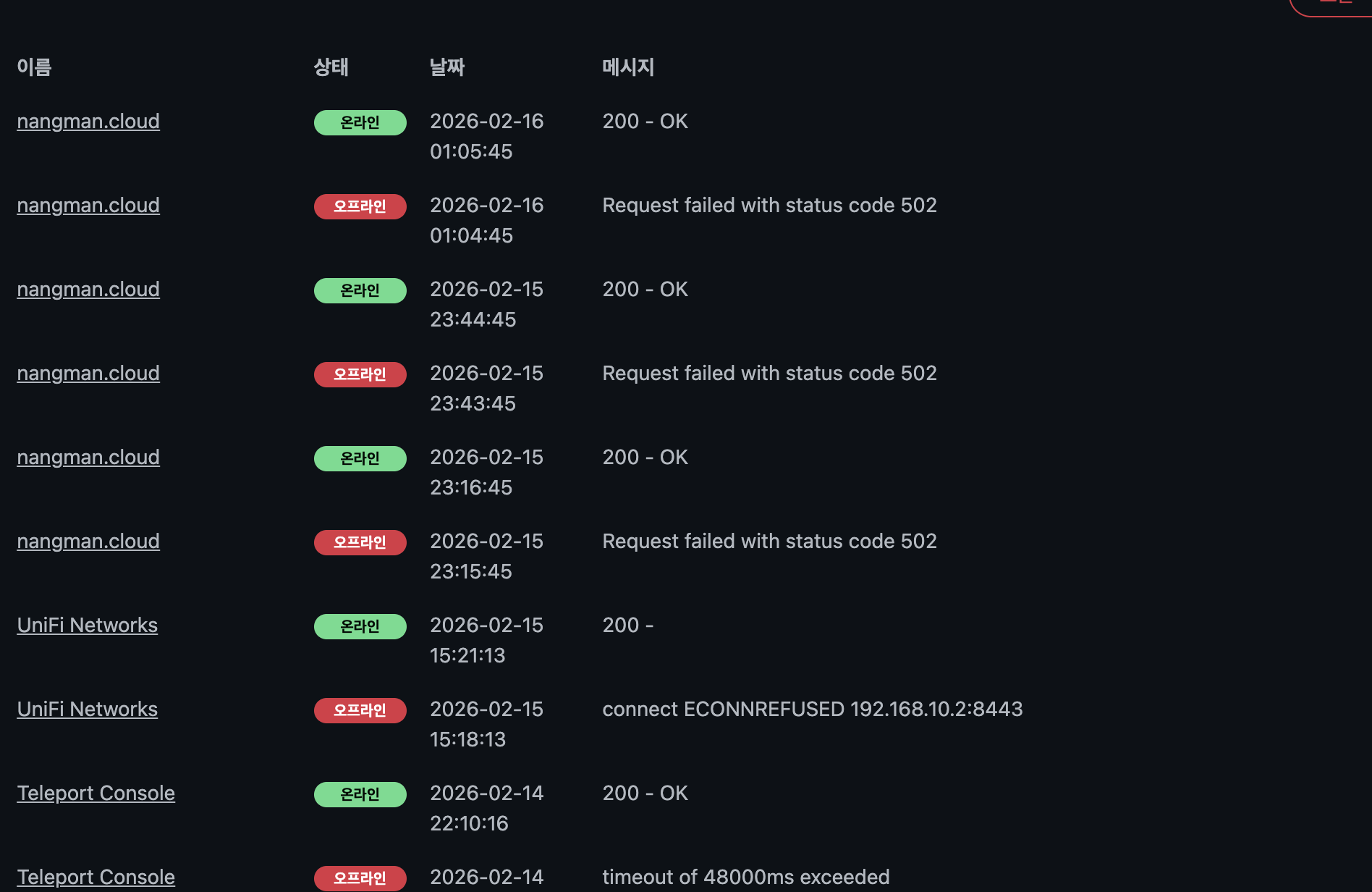
현재는 Uptime Kuma와 Mattermost를 연동하여 서버가 다운되고 올라갈 때마다 알람이 오게 되어 있습니다.
주요 문제점
- 알람에 대한 이해 부족: 왜 이 알람이 오는지, 무엇을 의미하는지 불명확
- 과도한 알람: 너무 자주 와서 오히려 무시하게 됨
- 원인 파악 불가: 장애 발생 시 어디서부터 봐야 할지 모름
- 해결 방법 부재: 알람이 와도 어떻게 대응해야 할지 모름
이런 상황에서는 제대로 된 모니터링 체계 구축이 절실했습니다.
모니터링 대상 선정
먼저 모니터링 대상 서비스를 특정했습니다. 팀 인프라 운영에 필수적인 8개 시스템을 선정했죠.
- Ansible-AWX: 자동화 작업 관리
- Wazuh: 보안 모니터링
- Harbor: 컨테이너 이미지 레지스트리
- RustFS: 파일 시스템
- Uptime-Kuma: 서비스 가용성 모니터링
- Authentik: 인증 시스템
- Jenkins: CI/CD 파이프라인
- Zabbix & Grafana: 모니터링 시스템 자체
알람 체계 설계
알람 체계를 설계하면서 다음과 같은 질문들에 답을 찾아야 했습니다.
핵심 질문들
어떤 지표를 모니터링할 것인가?
그 지표들을 어떤 주기로 모니터링할 것인가?
각 지표들의 임계점은 어느 정도인가?
임계점을 넘었다면 누구에게 어떻게 알람을 보낼 것인가?
알람 메시지에 표시할 내용은 어떻게 구성할 것인가?
각 알람의 해결 방법을 어떻게 문서화할 것인가?
Zabbix 알람 설정
1. 임계치 설정
가장 먼저 한 일은 명확한 임계치 설정이었습니다. CPU, Memory, Disk 사용률에 대해 두 단계로 구분했죠.
임계치 정책:
- 80% 이상: Warning (경고)
- 90% 이상: Critical (치명적)
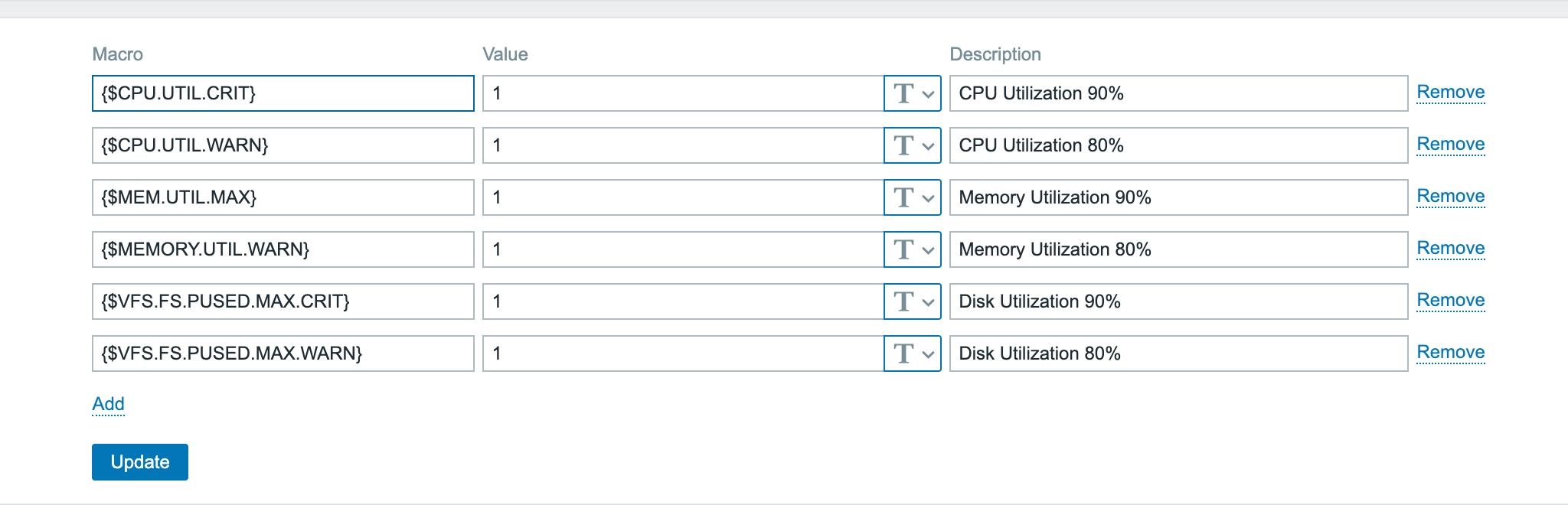
Zabbix의 Macro 기능을 활용해서 모든 서버에 일관된 기준을 적용했습니다.
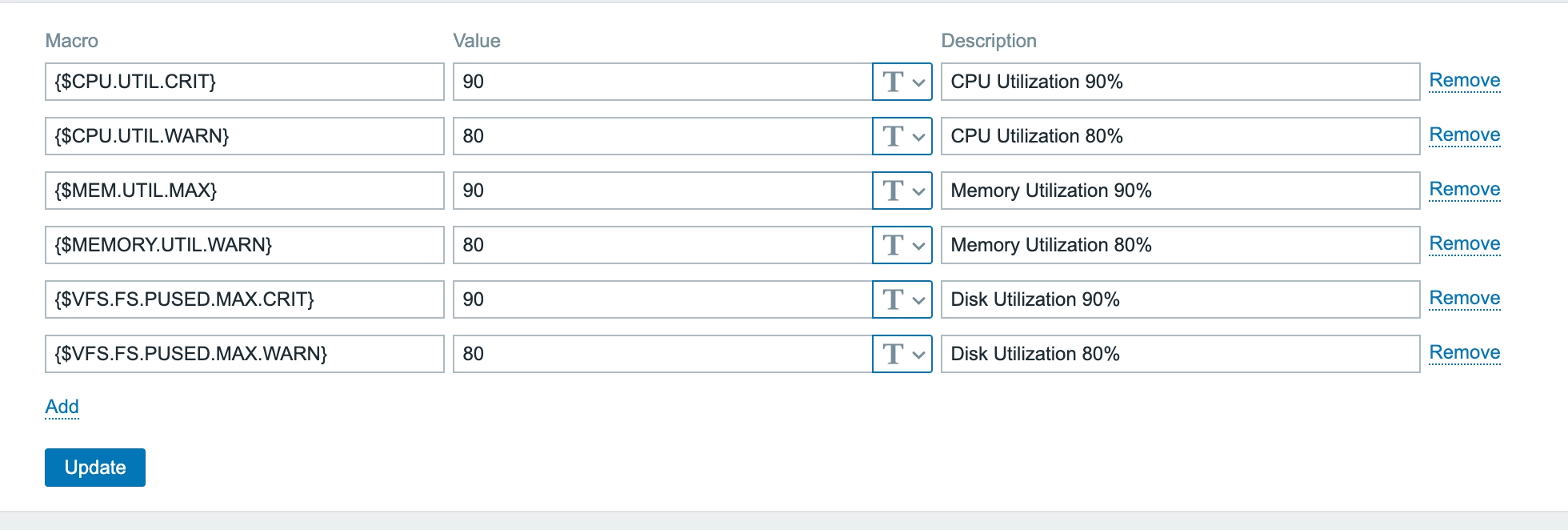
{CPU.UTIL.WARN} = 80 {CPU.UTIL.CRIT} = 90
{MEMORY.UTIL.WARN} = 80 {MEMORY.UTIL.MAX} = 90
{VFS.FS.PUSED.MAX.WARN} = 80 {VFS.FS.PUSED.MAX.CRIT} = 90
2. Zabbix Template 활용
Zabbix는 Template 시스템을 통해 기본적인 모니터링 항목을 자동으로 제공합니다.
각 서버에 "Linux by Zabbix agent active" Template을 적용하면 다음과 같은 항목들이 자동으로 모니터링됩니다:
- OS 레벨 기본 메트릭 (CPU, Memory, Disk, Network)
- 파일 변경 감지 (/etc/passwd 등)
- Zabbix Agent 연결 상태
- 시스템 설정 임계치 체크
기본 Template이 제공하는 항목들은 그대로 사용하고, CPU/Memory/Disk 임계치만 Macro로 커스터마이징했습니다.
이렇게 하면 모든 서버에 일관된 기준을 쉽게 적용할 수 있죠.
3. Mattermost 연동 - 첫 번째 삽질
알람을 받을 채널로 Mattermost를 선택했습니다. Slack과 유사하지만 온프레미스로 운영 가능한 협업 도구입니다.
Zabbix의 Users → Media 설정에서 Mattermost를 추가하고, Warning과 High(Critical) 레벨만 받도록 설정했습니다.
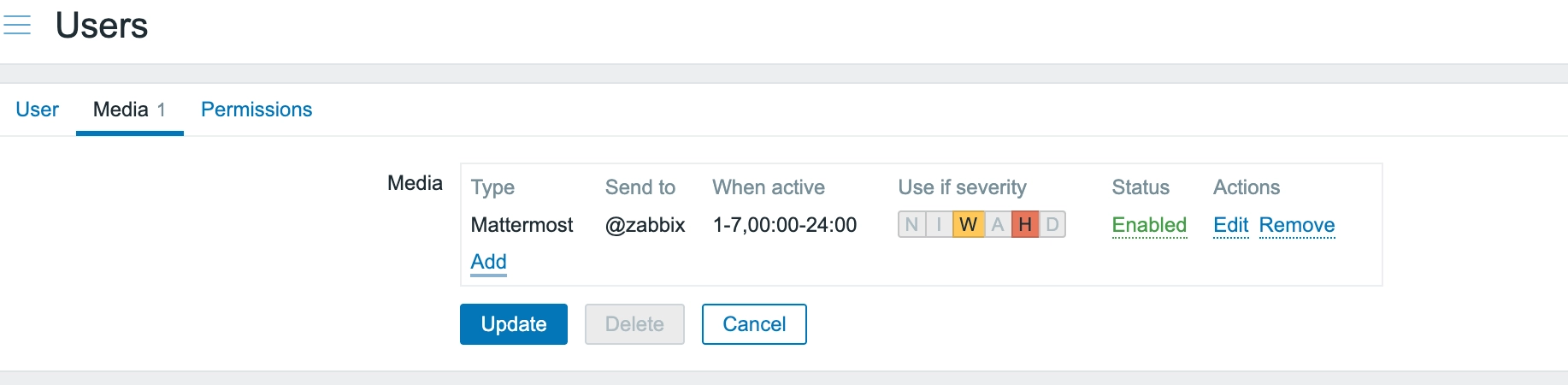
그런데 문제가 발생했습니다.
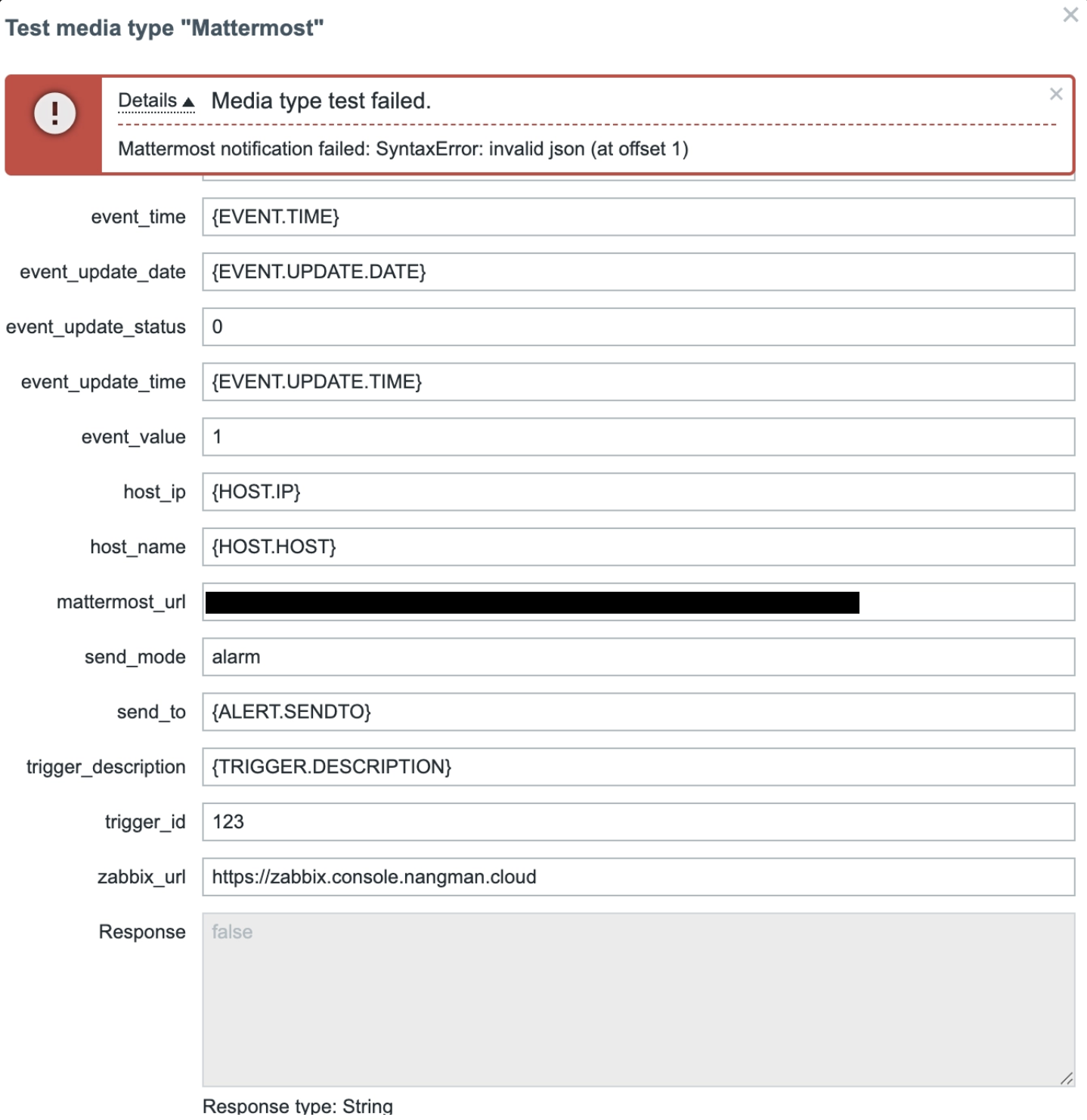
Media type test failed.
Mattermost notification failed: SyntaxError: invalid json (at offset 1)
테스트 메시지를 보내려고 하니 JSON 파싱 에러가 발생하는 겁니다.
원인을 찾아보니 Zabbix에서 Mattermost로 보내는 파라미터가 너무 많아서 JSON이 제대로 생성되지 않았던 것이었습니다.
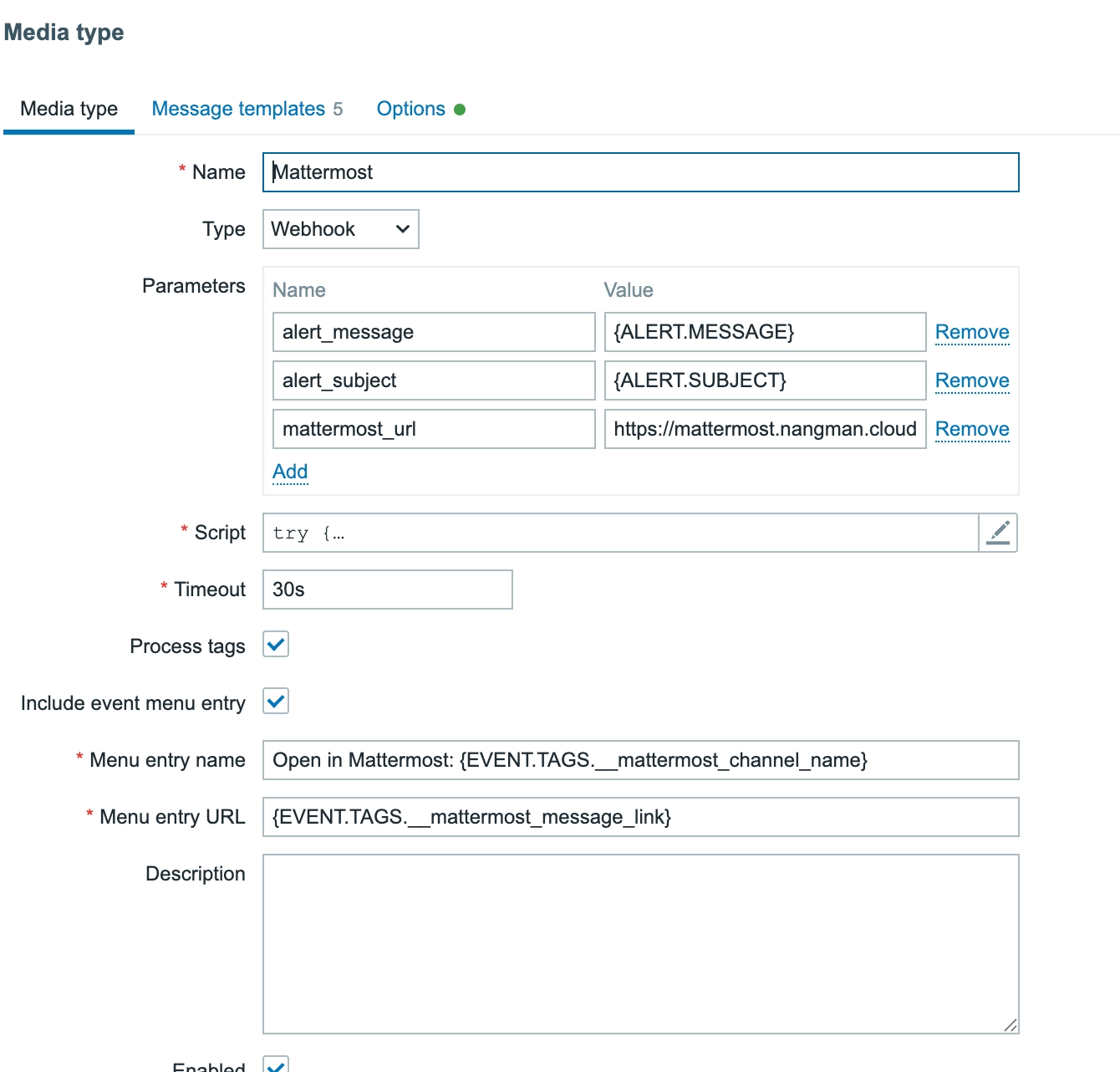
해결 방법: 파라미터를 최소화하고 JavaScript로 직접 Webhook을 작성했습니다.
javascripttry {
var params = JSON.parse(value);
// CurlHttpRequest가 안 되면 HttpRequest 사용
var req = new HttpRequest();
req.addHeader('Content-Type: application/json');
var payload = {
"text": "#### " + params.alert_subject + "\n" + params.alert_message,
"username": "Zabbix Alert"
};
req.post(params.mattermost_url, JSON.stringify(payload));
return "OK";
} catch (error) {
return "Error: " + error;
}Media Type 설정:
- Name:
alert_message→ Value:{ALERT.MESSAGE} - Name:
alert_subject→ Value:{ALERT.SUBJECT} - Name:
mattermost_url→ Value:https://mattermost.nangman.cloud/...
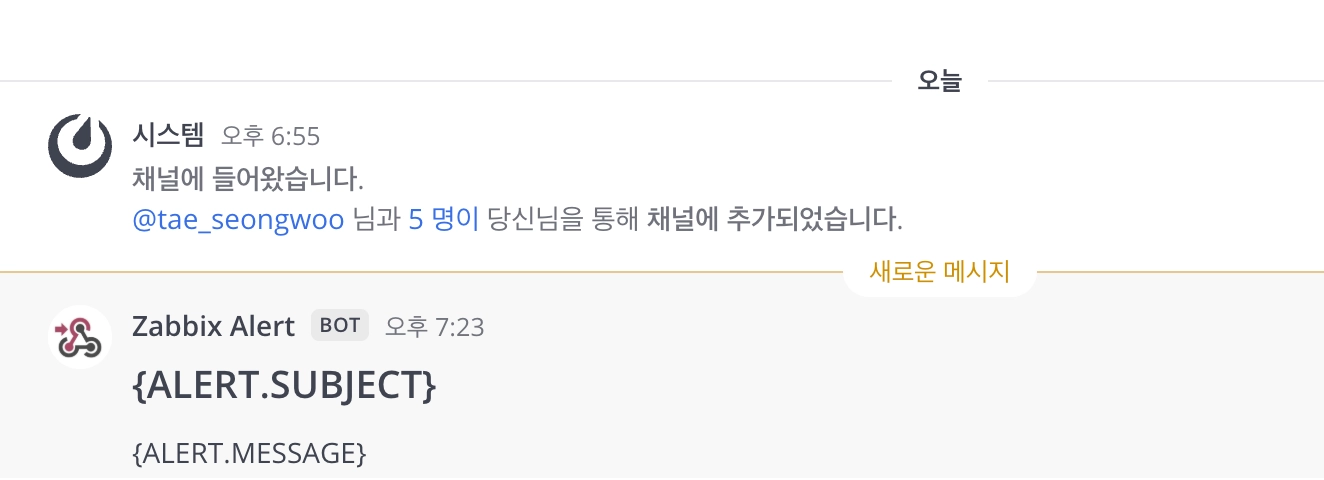
이제 테스트 메시지는 성공적으로 전송되었습니다!
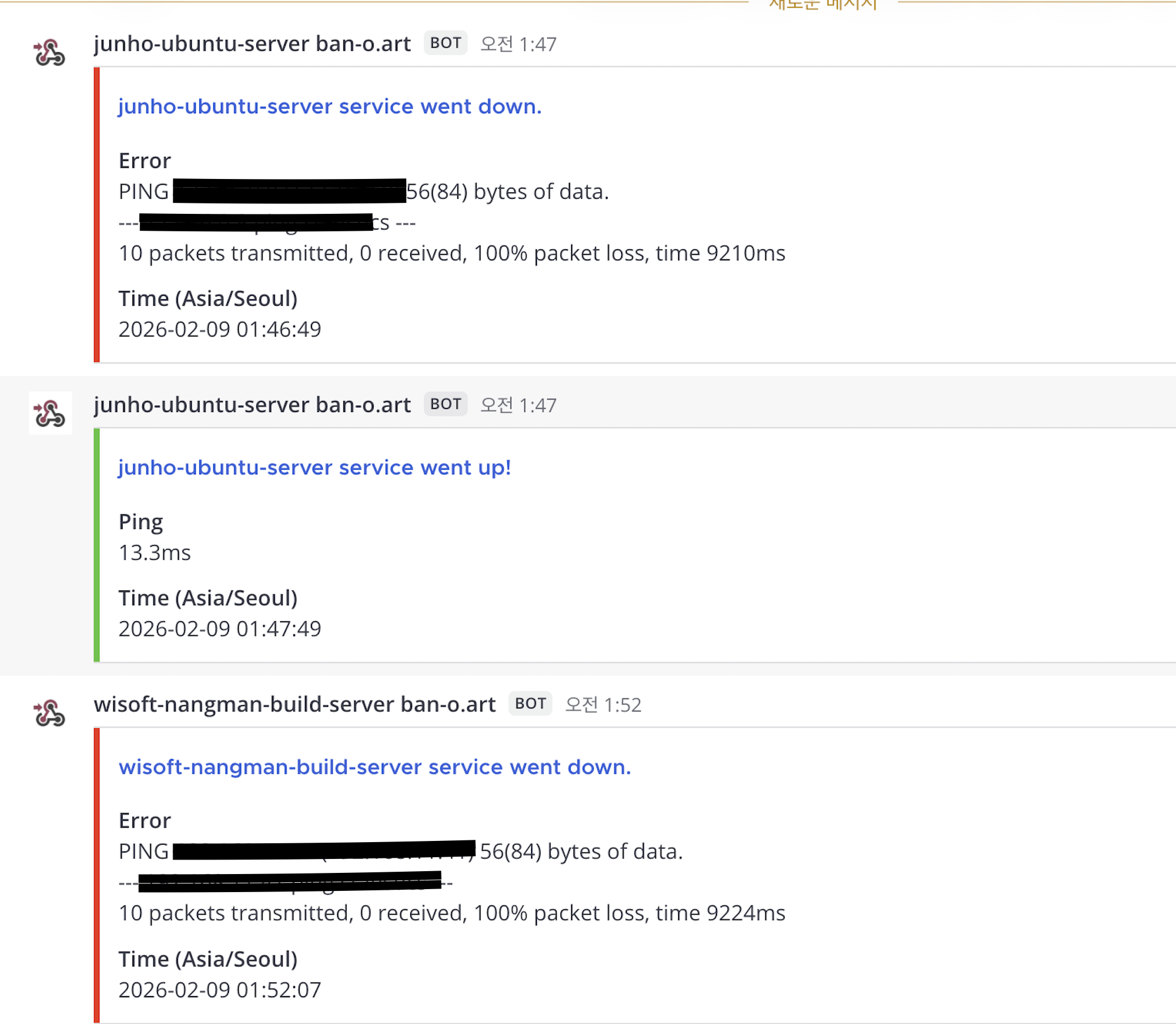
4. Recovery 알람 설정
장애가 발생했을 때 알람을 보내는 것도 중요하지만, 복구되었을 때도 알람을 보내는 것이 중요합니다. 그래야 장애가 해결되었는지 확인할 수 있으니까요.
Alert → Action 설정에서:
- Operations: 장애 발생 시 알람
- Recovery operations: 장애 복구 시 알람
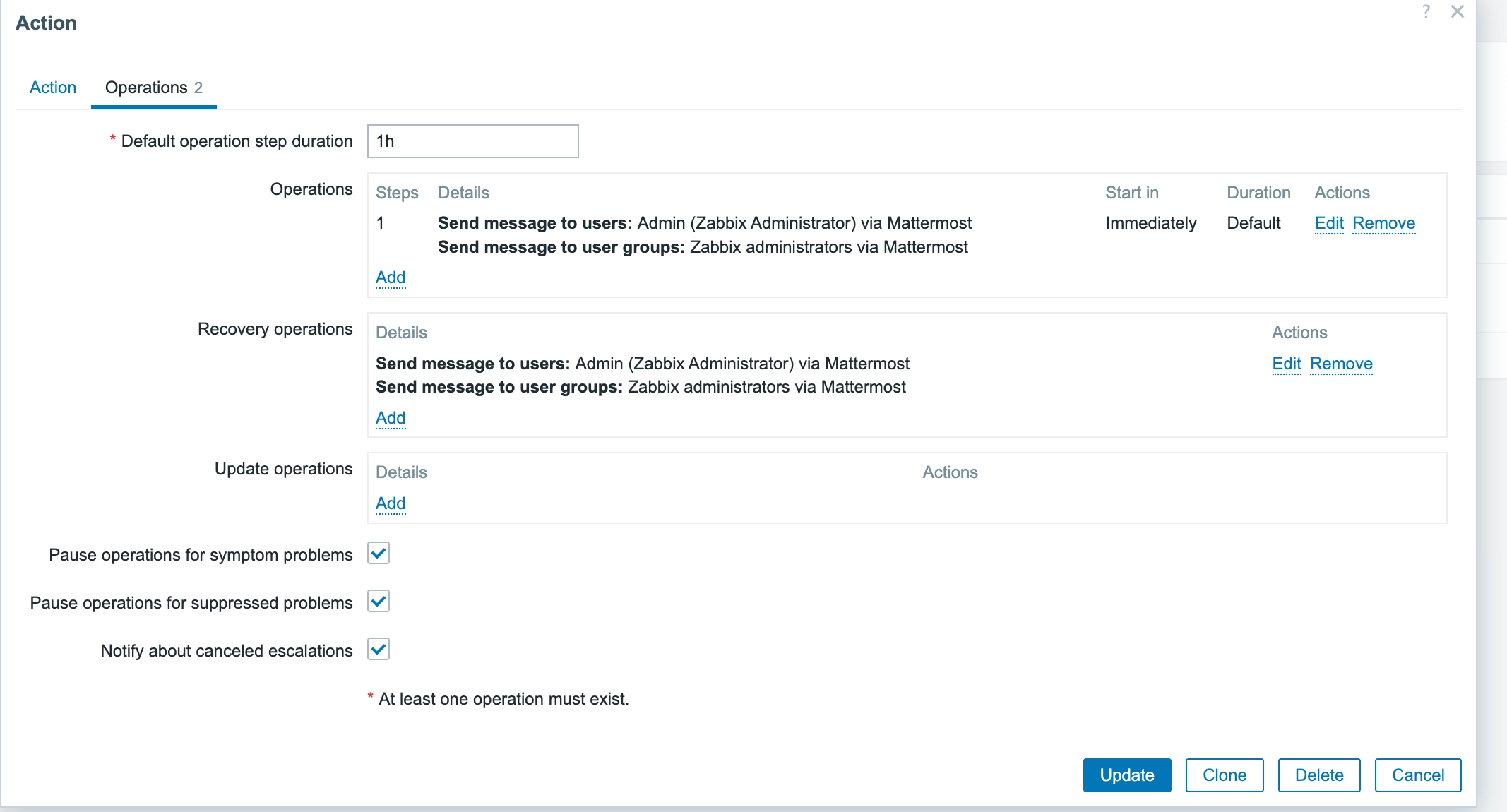
두 가지 모두 설정했습니다.
5. 테스트 - 두 번째 삽질
자, 이제 실제로 알람이 잘 오는지 테스트해봐야겠죠?
임계치를 잠깐 낮춰서 테스트를 진행했습니다. CPU 임계치를 1%로 설정하고... 기다렸습니다.
그런데 알람이 안 옵니다.
10분을 기다려도, 20분을 기다려도 알람이 오지 않았습니다. 설정을 다시 확인해봐도 문제가 없는데 말이죠.
원인 발견:
각 서버의 Trigger 설정을 자세히 들여다보니, 수식이 이렇게 되어 있었습니다:
avg(/donggoon-ubuntu-server/system.cpu.util,5m) > {$CPU.UTIL.CRIT}5m이 보이시나요? 이건 "5분 동안의 평균"을 의미합니다. 즉, CPU가 90%를 넘어도 5분 동안 평균을 계산한 후에야 알람이 발생하는 겁니다.
테스트 방법 변경:
트리거를 임시로 클론해서 수식을 바로 적용되게 변경했습니다:
last(/donggoon-ubuntu-server/system.cpu.util) > 1이렇게 하니 즉시 알람이 왔습니다!
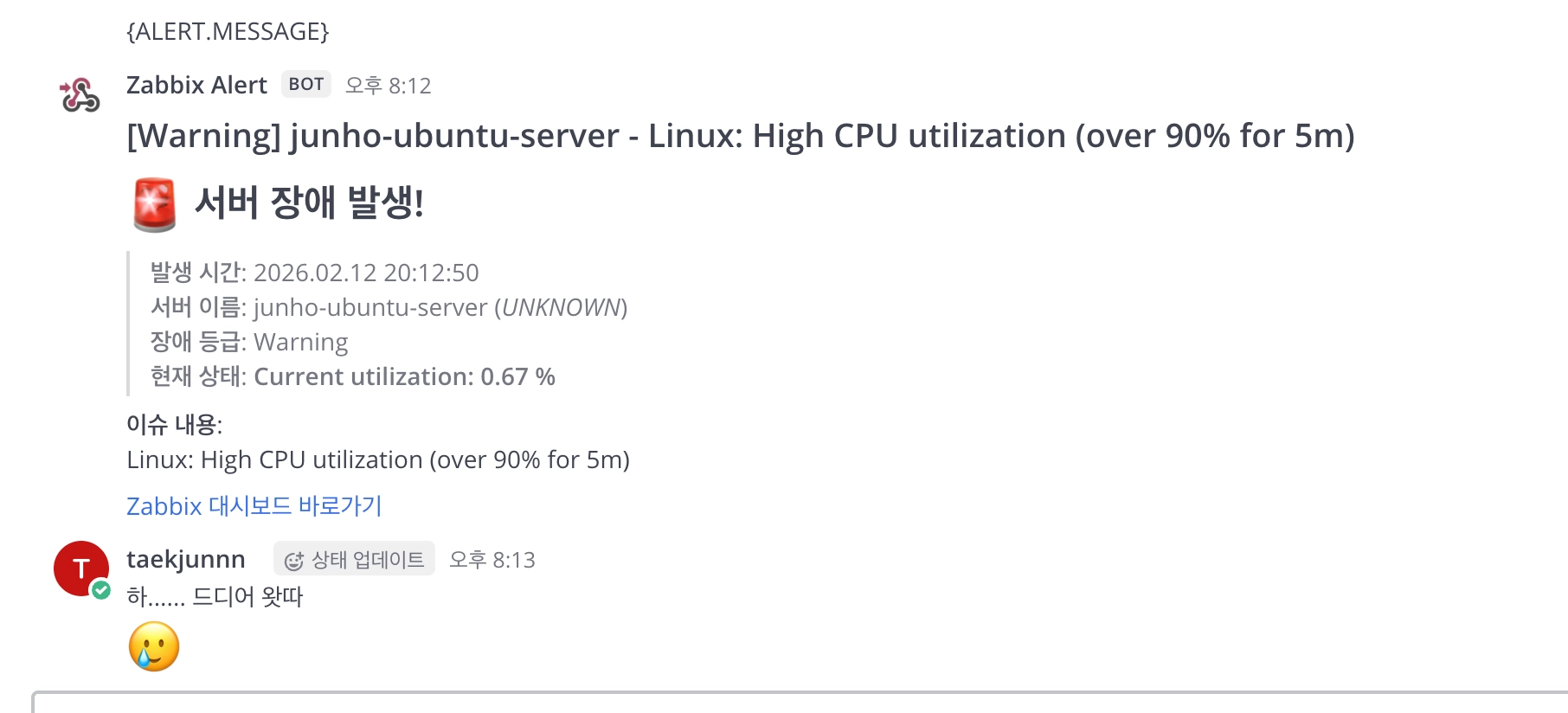
설정의 세부 사항을 제대로 이해하고 있어야 합니다.
"알람이 안 와요"라는 문제의 원인은 설정 오류가 아니라 설정에 대한 이해 부족이었던 것이죠.
테스트 완료 후에는 트리거를 원래대로 되돌리고, Macro에서 임계치를 다시 80%, 90%로 설정했습니다.
아키텍처 변경: Grafana 통합으로
Zabbix에서 직접 Mattermost로 알람을 보내는 구조를 완성했지만, 팀 회의를 통해 더 나은 방향을 찾게 되었습니다.
왜 Grafana 통합인가?
기존 방식 (Zabbix → Mattermost):
- Zabbix에서 직접 알람 전송
- 알람 메시지만 확인 가능
- 대시보드를 보려면 별도로 Grafana 접속 필요
개선 방식 (Zabbix → Grafana → Mattermost):
- Grafana Alert를 통한 통합 알람
- 알람 메시지에 대시보드 링크 포함
- 여러 데이터 소스 통합 모니터링
- 시각화된 그래프와 함께 알람 확인
특히 "Grafana 대시보드에 안 들어와도 해당 지표의 그래프를 볼 수 있게 설계하고 싶다"는 요구사항을 만족시킬 수 있었습니다.
"Grafana로 쏘면 대시보드 링크도 같이 보낼 수 있어요"
"Zabbix 직접 알람이랑 시간 차이 거의 안 나요"
"나중에 다른 데이터 소스 추가할 때도 Grafana로 통합 가능해요"
결과적으로 Grafana 통합 알람 체계로 방향을 전환하기로 결정했습니다.
배운 점
1. 알람도 설계가 필요하다
모니터링은 단순히 "메트릭을 수집하고 알람을 보내는 것"이 아닙니다. 체계적인 설계가 필요합니다:
- 무엇을 모니터링할 것인가: 중요한 지표 선정
- 임계치는 적절한가: 너무 낮으면 알람 피로, 너무 높으면 장애 놓침
- 누구에게 알릴 것인가: 온콜 담당자, 팀 전체, 관리자
- 어떻게 알릴 것인가: 메시지 포맷, 대시보드 링크, 해결 가이드
2. 도구의 동작 방식 이해
Zabbix Media Type의 파라미터 제한, Trigger 수식의 동작 방식(5분 평균) 등 도구의 세부 동작을 이해하지 못하면 예상치 못한 문제에 직면하게 됩니다.
"왜 안 되지?" 보다는 "이게 어떻게 동작하는 거지?"를 먼저 물어봐야 합니다.
3. 테스트의 중요성
설정을 완료했다고 끝이 아닙니다.
실제로 알람이 제대로 오는지, 복구 알람도 오는지, 메시지 포맷은 적절한지 반드시 테스트해야 합니다.
테스트 과정에서 발견한 문제들:
- JSON 파싱 에러
- 5분 평균 트리거 동작
- 파라미터 과다
이런 것들은 실제로 장애가 발생했을 때 발견하면 큰 문제가 됩니다.
4. 문서화는 필수
각 알람의 의미와 해결 방법을 문서화해야 합니다.
그래야 온콜 담당자가 새벽에 알람을 받았을 때 무엇을 해야 할지 알 수 있습니다.
문서화 항목:
- 알람 발생 조건
- 의미 (왜 이게 문제인가)
- 1차 대응 방법
- 에스컬레이션 절차
Next Steps
현재 Zabbix 알람 체계는 구축되었지만, 아직 할 일이 남아있습니다.
- Grafana Alert 설정 완료
- 대시보드 링크 포함 알람 구현
- 알람 해결 가이드 문서화
- 1개월 운영 후 임계치 재조정
마치며
"알람이 와도 무시한다"는 문제는 단순히 기술적인 문제가 아닙니다.
조직 문화, 프로세스, 그리고 도구의 적절한 활용이 모두 필요한 복합적인 문제죠.
이번 T/F 활동을 통해 기술적인 부분(Zabbix 설정, Mattermost 연동)뿐만 아니라, 팀원들과 함께 "좋은 모니터링이란 무엇인가"에 대해 고민해볼 수 있었습니다.
좋은 모니터링이란:
- 필요한 순간에 정확한 정보를 제공하고
- 불필요한 노이즈는 최소화하며
- 문제 해결을 돕는 것
감사합니다.
정택준
Email taekjunnnn@gmail.com
Team https://nangman.cloud/
