Naver Cloud Platform 기반 3-Tier 아키텍처로 구현한 Todo Calendar
안녕하세요! 클라우드스퀘어에서 현장실습을 진행하면서 Naver Cloud Platform을 활용한 3-Tier 아키텍처 설계 및 Todo Calendar 서비스를 구현한 경험을 공유하고자 합니다.
프로젝트 개요
이번 프로젝트는 단순히 Todo Calendar 서비스를 만드는 것을 넘어, 왜 3-Tier 아키텍처를 선택했는가에 대한 명확한 근거를 가지고 진행했습니다.
3-Tier 아키텍처는 웹 애플리케이션을 세 개의 논리적 계층으로 분리하는 구조입니다:
- Presentation Tier (Web Layer): 사용자 인터페이스
- Application Tier (WAS Layer): 비즈니스 로직 처리
- Data Tier (DB Layer): 데이터 저장 및 관리
단일 서버 vs 3-Tier 아키텍처

전체 아키텍처
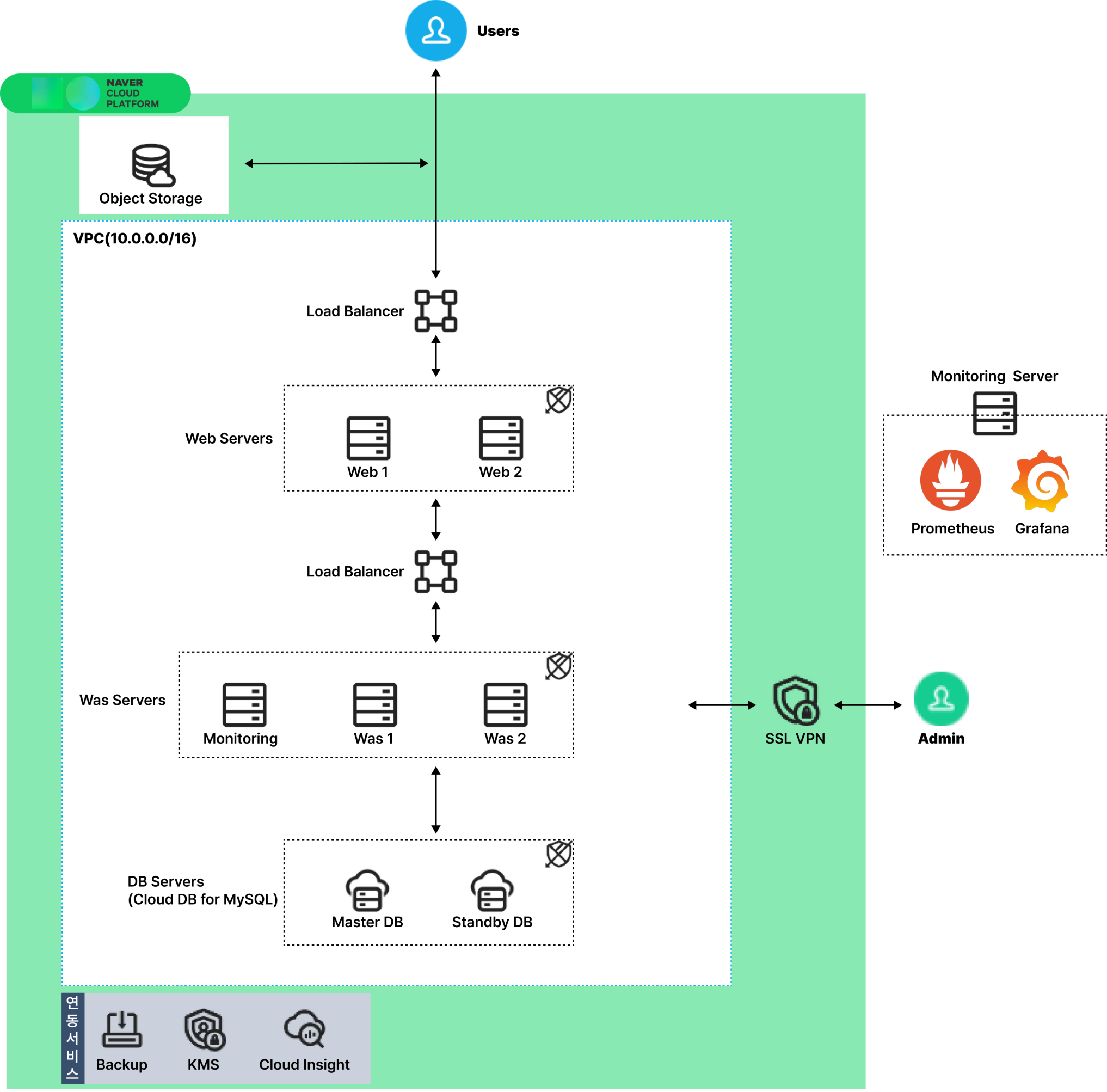
이번 프로젝트에서 구현한 아키텍처는 다음과 같은 특징을 가지고 있습니다:
보안
- 5단계 ACG 방화벽: 각 계층별로 세분화된 접근 제어
- KMS 데이터 암호화: 민감 데이터 보호
- SSL VPN: 관리자 접근 제어
가용성
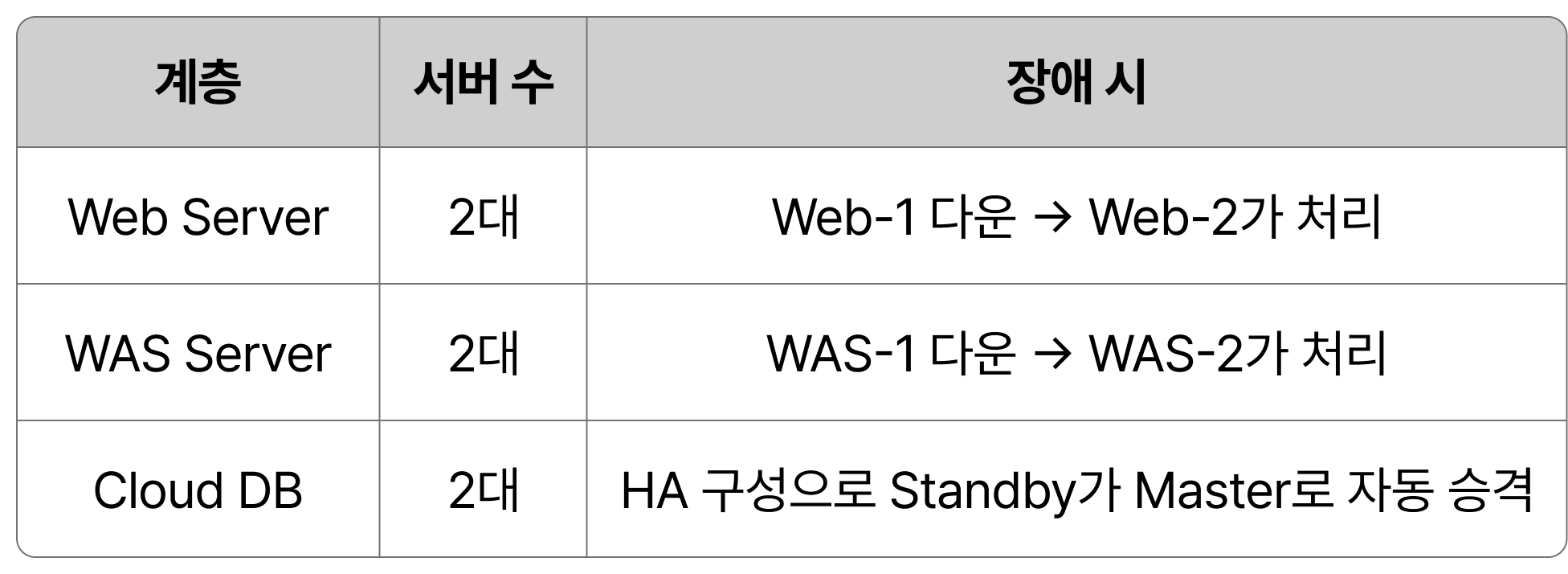
- Web/WAS 이중화: 장애 발생 시 자동 전환
- LB Health Check: 장애 서버 자동 제외
- Cloud DB Failover: 자동 복구 체계
운영
- Prometheus/Grafana: 실시간 모니터링
- 자동 백업: 데이터 손실 방지
- GitHub Actions CI/CD: 자동화된 배포
보안 설계
ACG(Access Control Group) 구성
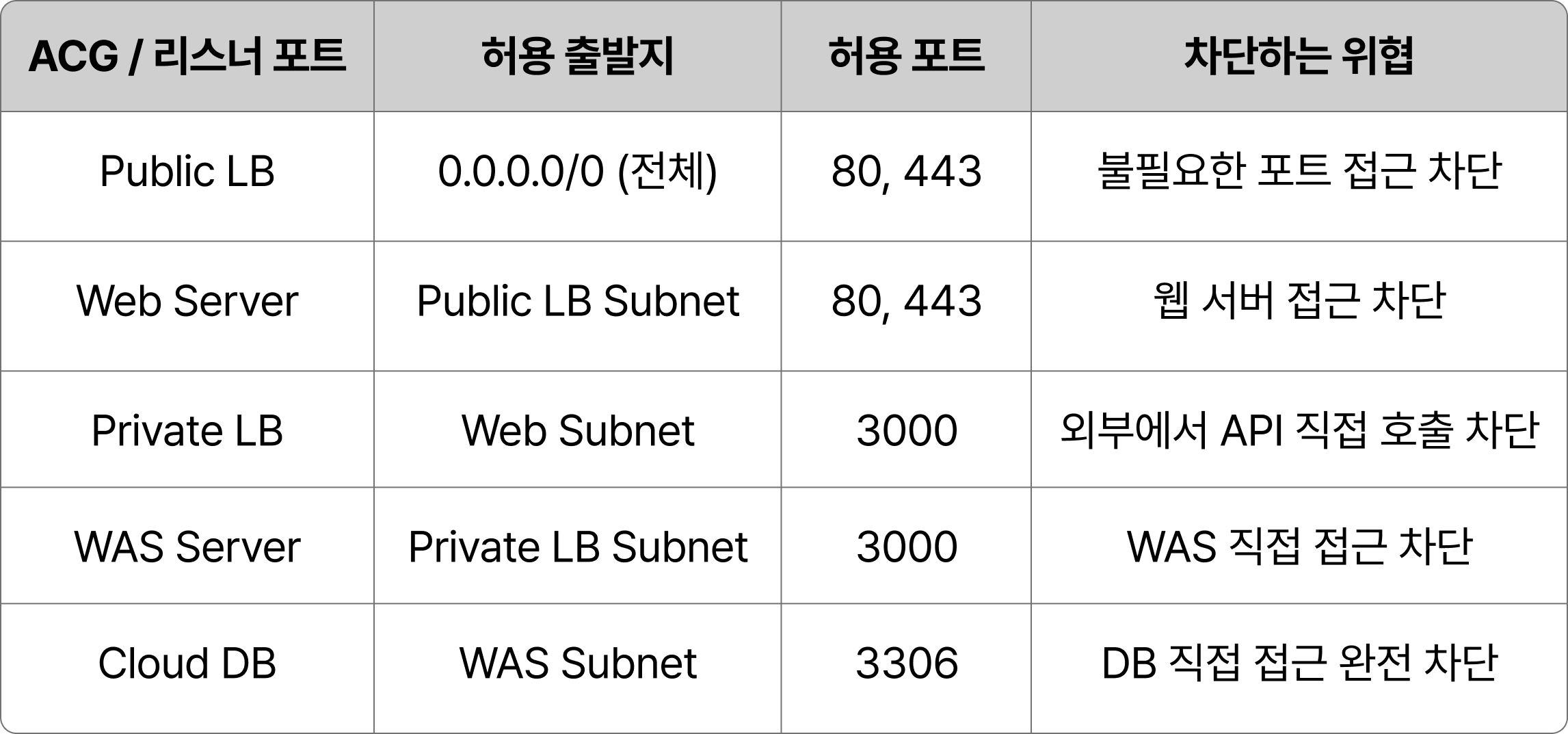
이렇게 5단계의 ACG를 구성하여 각 계층별로 필요한 트래픽만 허용하고, 불필요한 접근을 철저히 차단했습니다.
LB에는 ACG적용이 불가능하기 때문에 리스너 포트를 적용해 불필요한 포트 접근을 차단할 수 있습니다.
KMS (Key Management Service)
KMS는 데이터 암호화에 사용되는 키를 안전하게 관리해주는 서비스입니다. 암호화 키를 서버나 코드에 직접 저장하지 않고, NCP KMS가 키의 생성, 보관, 사용을 대신 관리합니다.
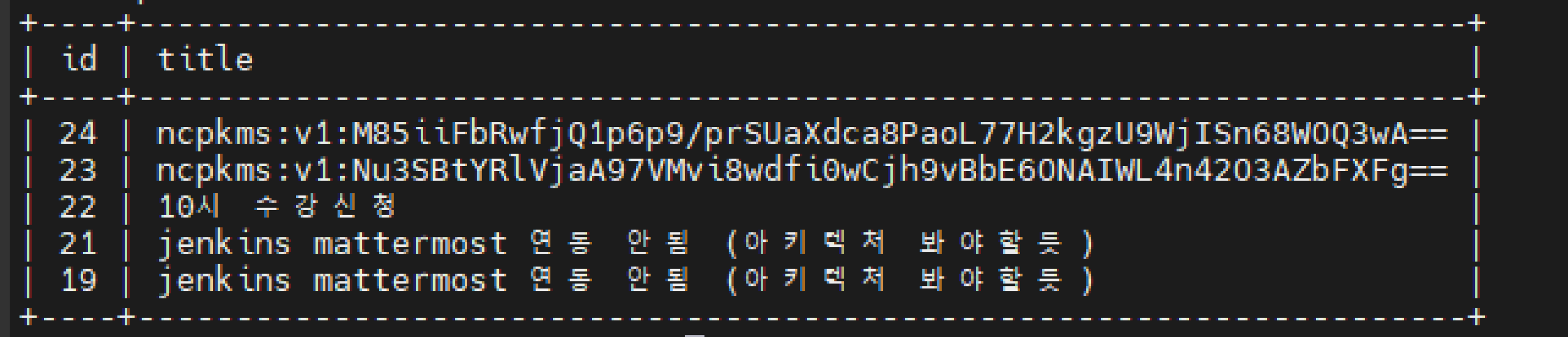
데이터베이스가 유출되더라도 데이터를 읽을 수 없도록 NCP KMS로 민감 데이터를 암호화하여 저장했습니다.
KMS의 장점:
- 암호화 키 자체를 개발자도 볼 수 없음
- DB가 유출되어도 암호문만 노출
- KMS API 권한 없이는 복호화 불가능
실제 데이터베이스를 조회하면 다음과 같이 암호화된 형태로 저장됩니다:
SSL VPN
모든 서버는 Private Subnet에 위치하여 인터넷에서 SSH 접근이 불가능합니다. 관리자는 SSL VPN을 통해서만 서버에 접속할 수 있어, 데이터 전송을 암호화하고 안전한 통신을 보장합니다.
가용성 설계
Load Balancer를 통한 이중화
Load Balancer 알고리즘

- Round Robin: 로드밸런싱으로 지정된 서버들에 대해 순차적으로 요청을 전달
- Least Connection: 클라이언트의 요청을 가장 적은 수의 연결이 이루어진 서버로 할당
- Source IP Hash: Source IP 정보를 바탕으로 해시한 결과로 로드밸런싱을 실행
각 알고리즘의 특성을 고려하여 서비스 특성에 맞는 방식을 선택할 수 있습니다.
Cloud DB
Cloud DB는 Active-Standby 구조로 설계했습니다.
Active-Active 같은 경우는 여러 DB에 동시에 쓰기 때문에 데이터 충돌 가능성이 있습니다.
Active-Standby 구조는 하나의 Master만 쓰기 수행하기 때문에 데이터 일관성을 보장할 수 있습니다.
그렇다고 Active-Active를 모든 경우에서 사용하지 않는 건 아닙니다.
Multi Region 환경이나 읽기/쓰기 부하가 매우 높은 경우에는 Active-Active 구조를 택하기도 합니다.
주요 기능 구현
이미지 업로드 - Presigned URL 방식
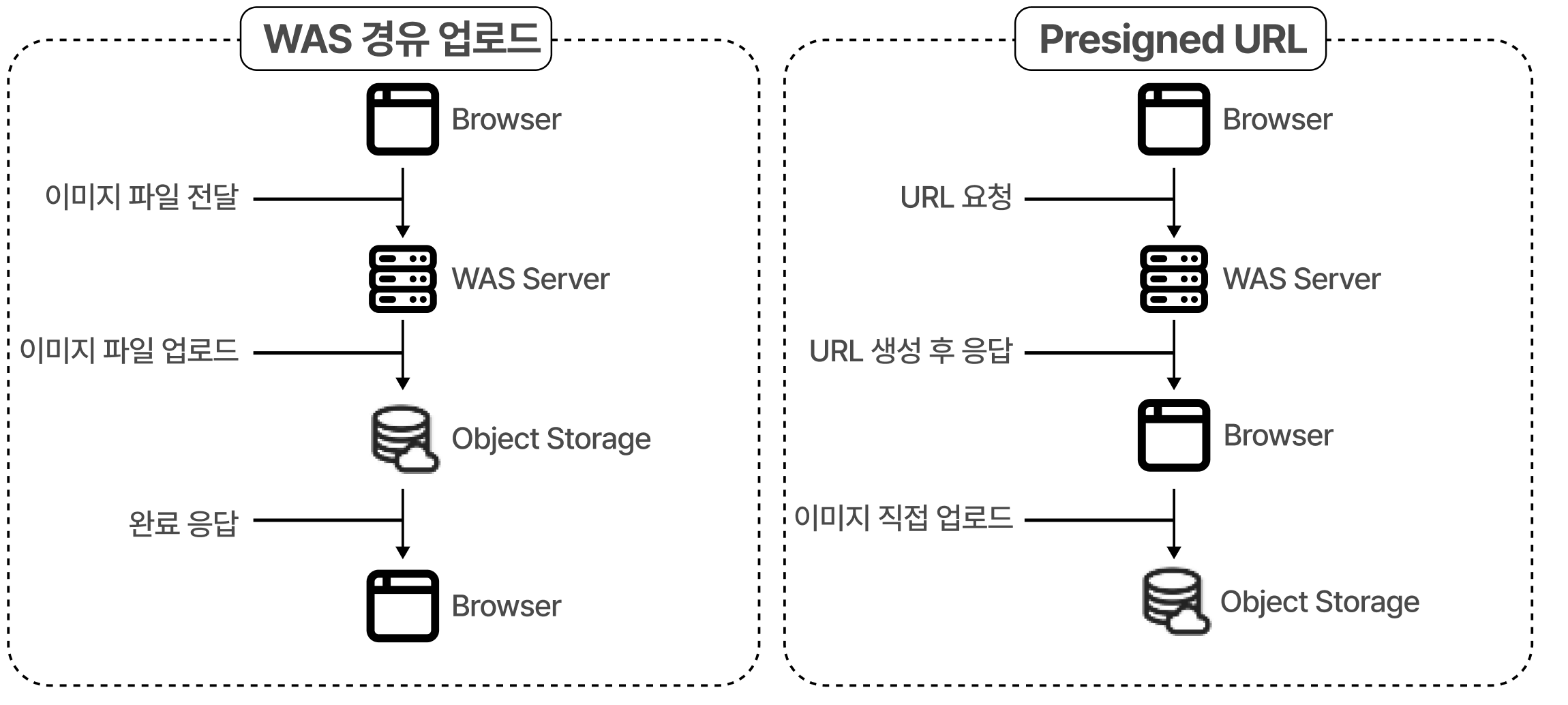
이미지 업로드 기능을 구현하면서 두 가지 방식을 비교했습니다:
WAS 경유 방식
- Browser → WAS Server → Object Storage
WAS에 0.49MB의 파일이 적재됨
메모리 사용: 약 3MB (파일 버퍼링 + S3 업로드)
Presigned URL 방식
- Browser → WAS Server (URL 요청)
→ Browser → Object Storage (직접 업로드)
WAS에 파일이 전달되지 않음
메모리 사용: 32KB (URL 생성 비용만)
성능 비교:
Presigned URL: 0.02s user 0.01s system 2% cpu 1.102 total

WAS 경유: 0.01s user 0.01s system 11% cpu 0.152 total


Presigned URL 방식을 채택하여 WAS의 부하를 크게 줄일 수 있었습니다.
이메일 알림 시스템
nodemailer + Gmail SMTP
javascript// 이메일 발송 설정 (Gmail SMTP)
const transporter = nodemailer.createTransport({
service: 'gmail',
auth: {
user: process.env.GMAIL_USER,
pass: process.env.GMAIL_APP_PASSWORD
}
});node-cron 스케줄러
javascript// 이메일 알림 스케줄러 (매분 실행)
function startNotificationScheduler() {
cron.schedule('* * * * *', async () => {
try {
const now = new Date()
const currentDate = now.toISOString().split('T')[0]
const currentHours = String(now.getHours()).padStart(2, '0')
const currentMinutes = String(now.getMinutes()).padStart(2, '0')
const currentTime = `${currentHours}:${currentMinutes}`
// ... 알림 로직
}
});
}이를 통해 사용자가 설정한 시간에 Todo 알림을 이메일로 받을 수 있습니다.

모니터링 시스템
구성 요소
| 구성 요소 | 역할 | 위치 |
|---|---|---|
| Prometheus | 메트릭 수집 및 저장 (시계열 DB) | Monitoring 서버 |
| Grafana | 대시보드 시각화, 알림 설정 | Monitoring 서버 |
| Node Exporter | 서버별 시스템 메트릭 수집 에이전트 | Web, WAS 각 서버 |
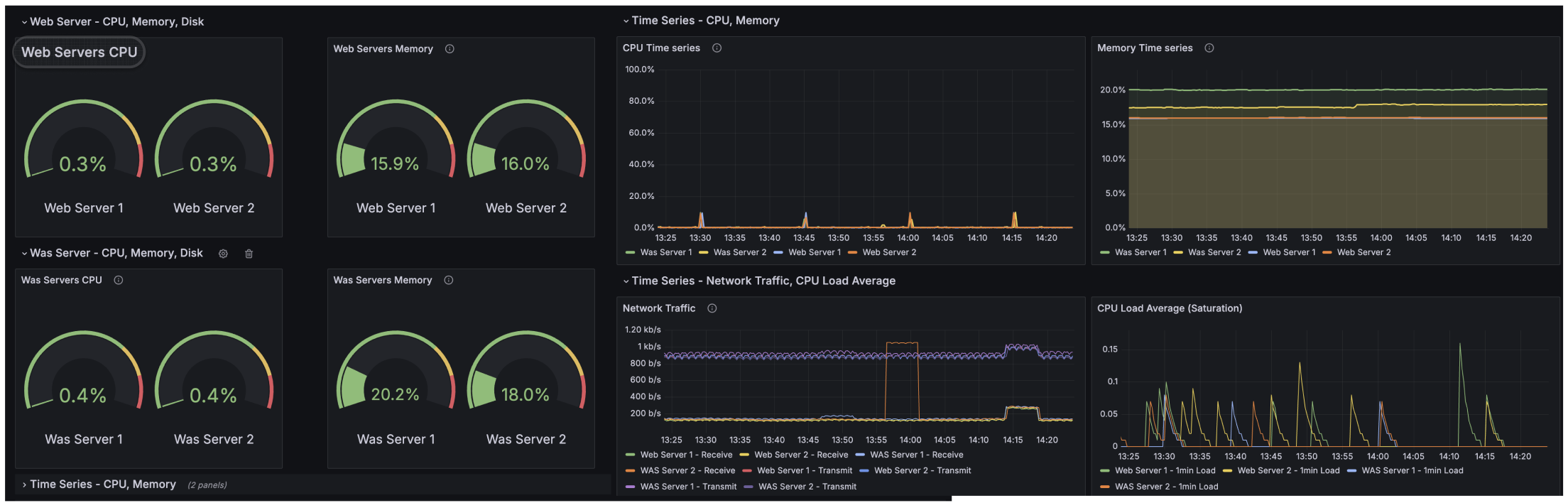
USE 메서드 기반 대시보드
| 항목 | 의미 |
|---|---|
| Utilization (사용률) | 리소스가 실제로 사용 중인 비율 |
| Saturation (포화도) | 처리 대기 중인 작업량 (큐 길이, 로드 등) |
| Errors (오류) | 리소스 오류 발생 수 |
Slack 알림 연동
CPU 사용률이 85%를 초과하면 Slack으로 알림이 전송되어 즉각적인 대응이 가능합니다:
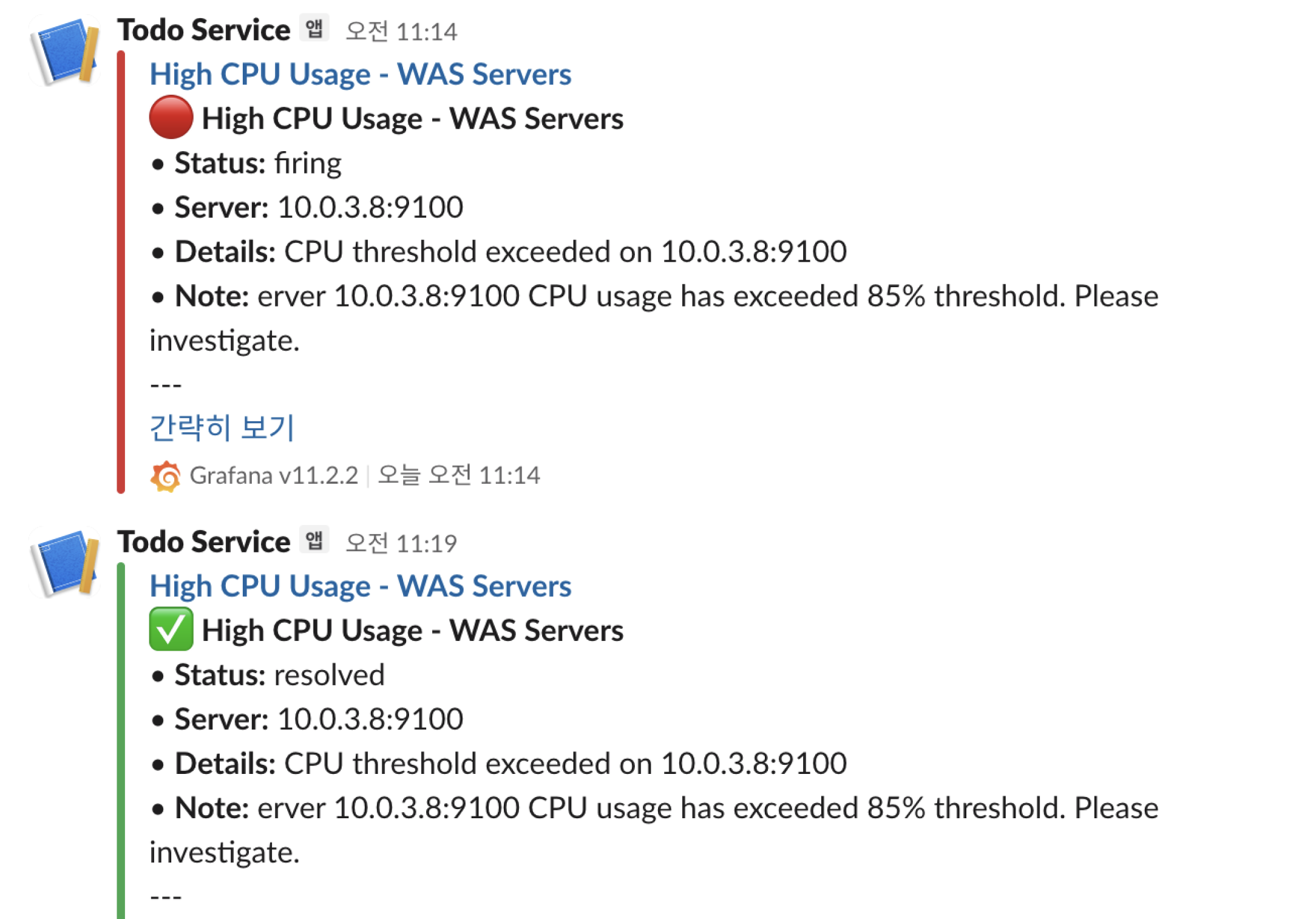
백업 및 복구 전략
백업 스케줄
- 전체 백업: 일요일 02:00
- 증분 백업: 매일 00:00
증분 백업은 전체 백업 이후에 업데이트된 내용만 백업하여 효율성을 높였습니다.

복원 테스트
실제로 복원 기능이 정상 작동하는지 테스트를 진행했습니다:
home디렉터리에test.txt파일 생성- 백업 진행
- 파일 삭제
- 복원 진행
- 파일 정상 복구 확인
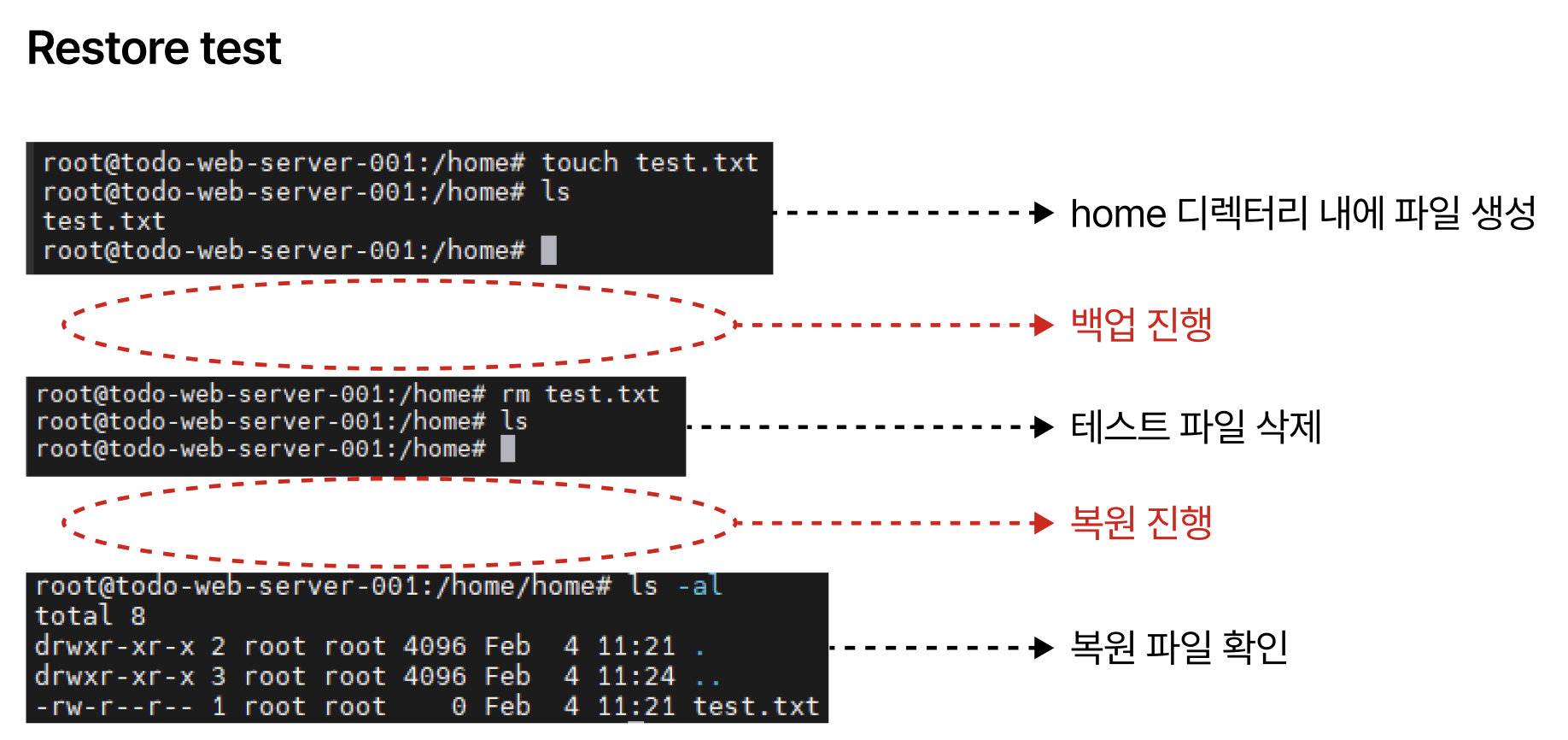
이를 통해 실제 장애 상황에서도 데이터를 안전하게 복구할 수 있음을 검증했습니다.
서비스 데모
실제 서비스는 다음 URL에서 확인할 수 있습니다:
http://todo-public-lb-125947158-91f454bb0656.kr.lb.naverncp.com
주요 기능:
- 월별 캘린더 뷰
- Todo 추가/수정/삭제
- 이미지 첨부
- 이메일 알림 설정
마치며
프로젝트를 진행하며 리소스를 사용할 때 "왜 이것을 선택했는가"에 대한 근거를 갖는 것이 중요하다는 것을 느꼈습니다.
최신 기술을 무리하게 도입하기보다, 3-Tier 아키텍처의 기본 원리를 직접 설계하고 구축하면서 다음을 배울 수 있었습니다:
- 네트워크 분리의 중요성
- 보안 계층화 전략
- 가용성 확보 방법
- 인프라의 기초
향후 계획
다음 단계로는 아키텍처를 더욱 확장해 나가고 싶습니다:
- Auto Scaling: 트래픽 변화에 자동 대응
- 재해 복구(DR) 전략: 더욱 견고한 백업 체계
- 컨테이너 기반 배포: Docker/Kubernetes 도입
이번 현장실습을 통해 클라우드 인프라의 기초를 탄탄히 다질 수 있었고, 실무에서 요구되는 아키텍처 설계 능력을 키울 수 있었습니다.
감사합니다.
정택준
Email taekjunnnn@gmail.com
Team https://nangman.cloud
